boost course의 딥러닝으로 만드는 질의응답 시스템을 보고 복습차원에서 정리한 것입니다.
Generation-based MRC

- 주어진 지문과 질문을 보고 답변을 생성하는 문제 (generation)
- 모든 Q&A task는 Generation-based MRC 문제로 치환 가능
Evaluation of Generation-based MRC
- EM, F1 Score 사용 가능
- 더 정확한 계산을 위해서는 ROUGE-L, BLEU Score를 사용
Overview of Generation-based MRC
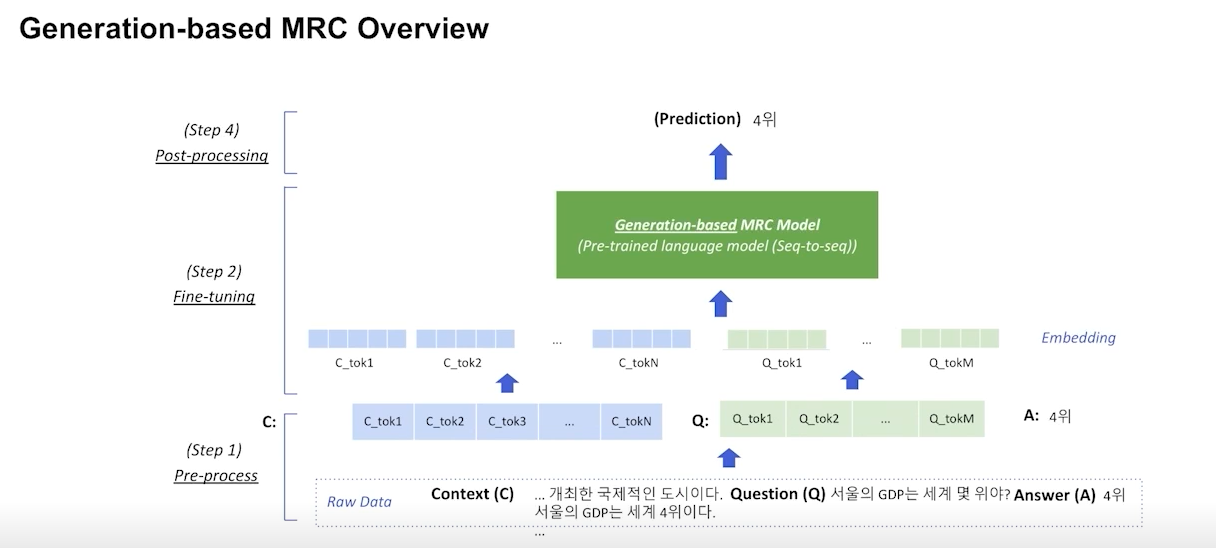
- Extraction-based model과 거의 동일
- Generation-based model은 바로 정답을 생성 (seq2seq model)
- encoder only model은 generation task에 사용 불가
Preprocessing

example of data
- Extraction-based model보다 훨신 간단
- start position과 end position을 알 필요가 없음
tokenizer
- Extraction-based model과 동일

input IDs
- text(context + question)을 index로 바꾼 것

special tokens
- Extraction-based model과 동일
- 각각의 토큰은 임의로 설정한 것이기 때문에 모델마다 달라질 수 있음
attention mask, token type IDs
- Extraction-based model과 동일
- BART모델의 경우 입력 sequence에 token type IDs가 없음
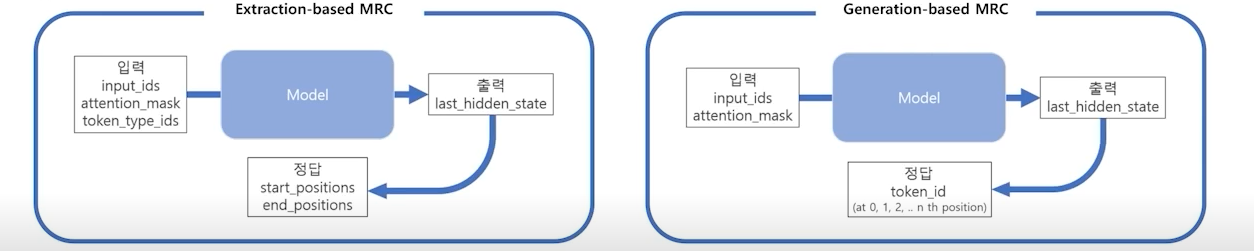
outputs
- Extraction-based model은 output으로 token id를 출력
- start/end position을 알 필요가 없음
Model
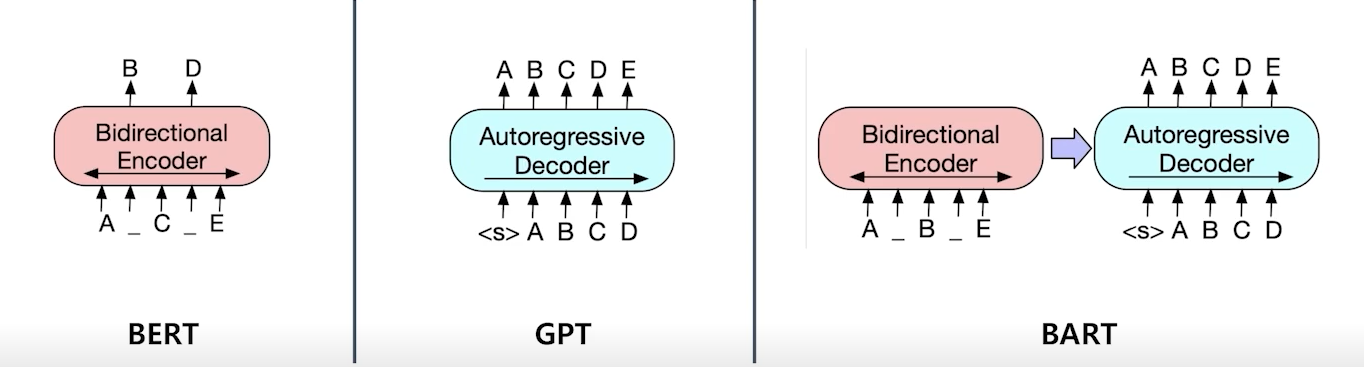
BART
- BERT 또는 GPT와 달리 인코더와 디코더 두가지 구조를 모두 가지고 있음
- 인코더는 BERT와 비슷하게 Bi-directional
- 디코더는 GPT와 비슷하게 Auto-regressive
pretraining of BART
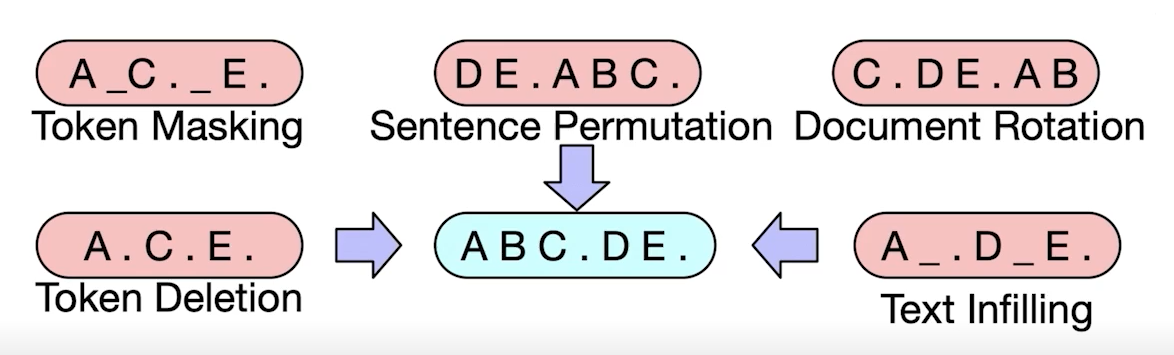
- 텍스트에 노이즈를 주고 원래 텍스트를 복구하는 문제를 푸는 방식
Post-processing
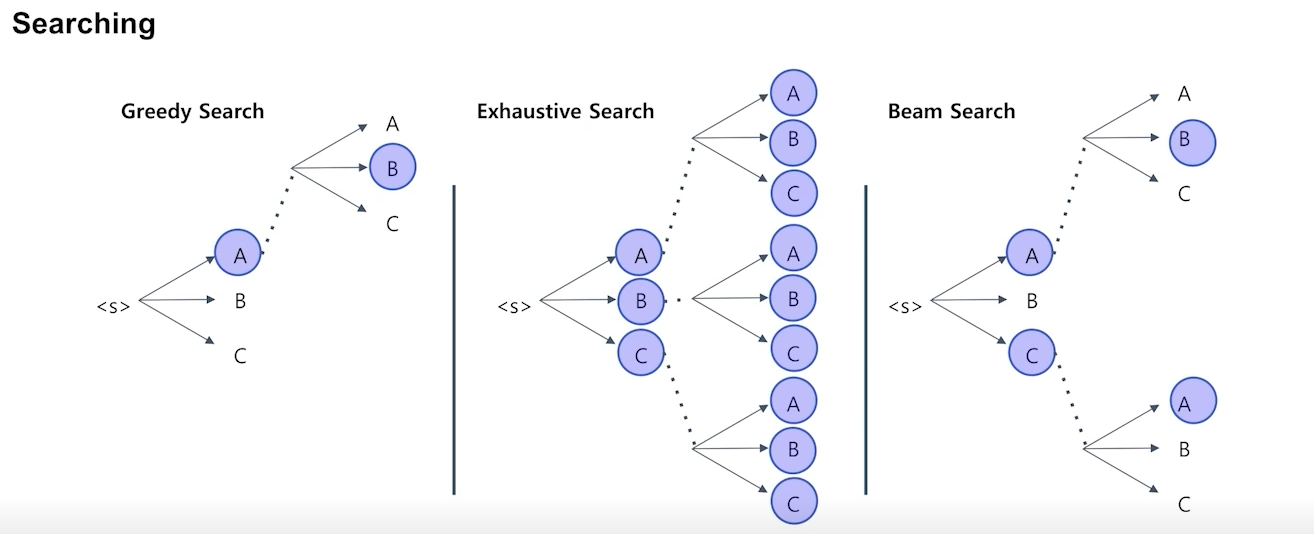
- greedy search - 가장 확률이 높은 단어 하나만 고려 (생성 속도 빠름, 최적의 선택은 아님)
- exhaustive search - 모든 가능성을 다 고려 (생성 속도 엄청 느림, 최적의 선택 가능)
- beam search - 가장 확률이 높은 n개만 고려 (두가지 방법의 절충안)

NLP취준생