boost course의 딥러닝으로 만드는 질의응답 시스템을 보고 정리하였습니다.
Passage Retrieval
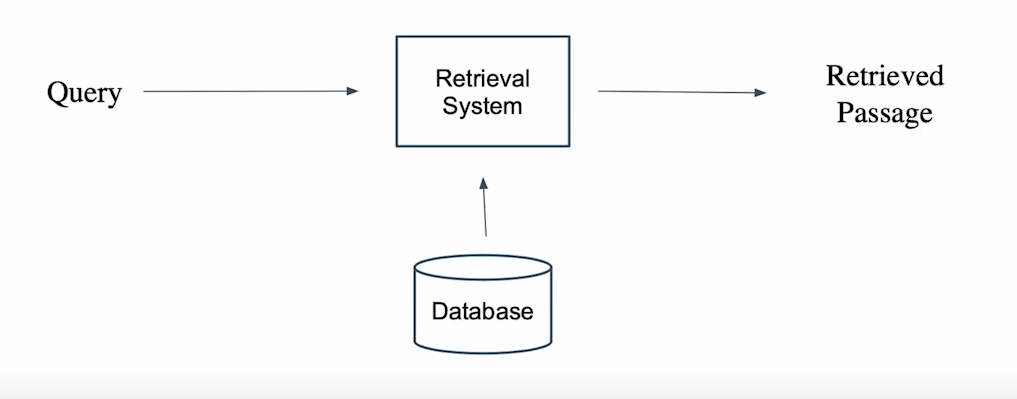
- 질문에 맞는 문서를 찾아주는 것
- 웹 상의 관련 문서를 가져오는 것
Passage Retrieval with MRC
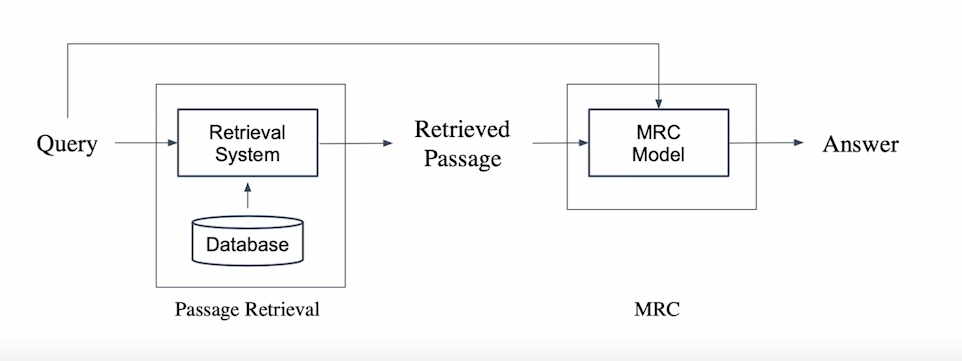
- Open-domain Question Answering을 통하여 대규모 문서 중 질문에 대한 답을 찾을 수 있음
- Question의 질문에 대한 답을 가진 문서를 찾는 과정
- Passage Retrieval + MRC의 구조
Overview of Passage Retrieval
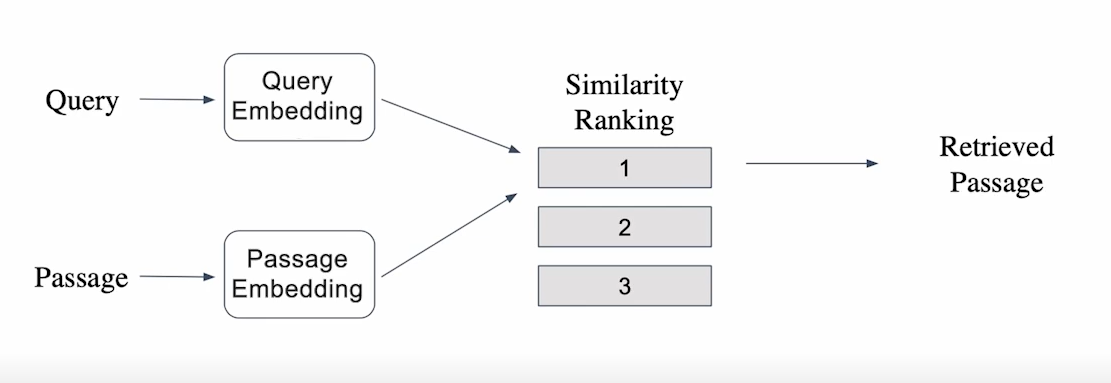
- query와 passage를 임베딩 한 뒤 유사도를 기준으로 가장 높은 passage 선택
- passage는 미리 embedding을 해 둬서 효율성 도모
Embedding

- passage를 벡터화하여 3차원 공간 안에 나타낸 것
- 문서를 고차원 상에 하나의 점으로 표현하는 것
sparse embedding
bag of words
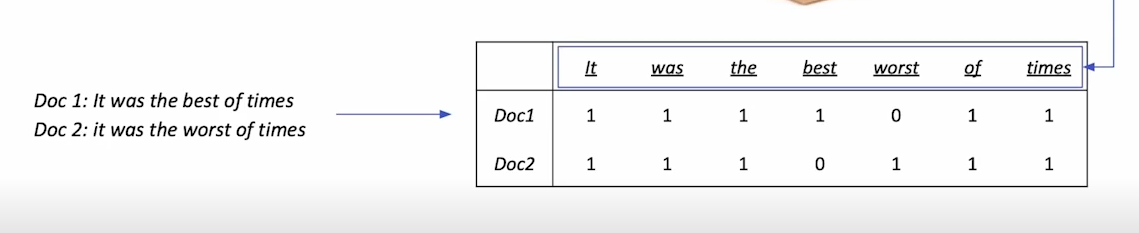
- 실제 단어가 문서 안에 존재하는지 안하는 지만 고려
- vocab이 커지면 커질수록 0이 많이 존재하여 비효율적임
- 조금 더 advanced한 방법으로는 n-gram을 이용하여 구성하는 방법이 있음
- dimension of embedding vector = num of words
- 단어의 overlap을 정확하게 잡아 내야 할 때 유용(검색어를 포함 하는가)
- 의미가 비슷하지만 다른 단어인 경우에는 비교 불가(유사성 판단 x)
TF-IDF
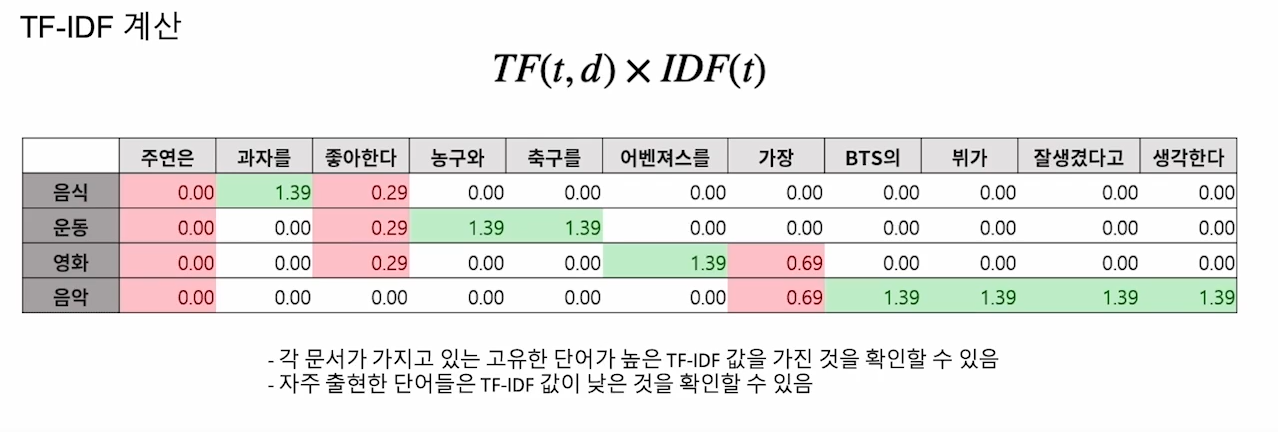
- Term Frequency (TF) - 단어의 등장 빈도
- TF = raw count / num words
- Inverse Document Frequency (IDF) - 단어가 제공하는 정보의 양
- IDF = Log(the number of document / document frequency (include term t))
- 아주 빈도가 큰 단어의 경우에는 IDF score가 낮아짐
- TF-IDF = TF x IDF
BM25
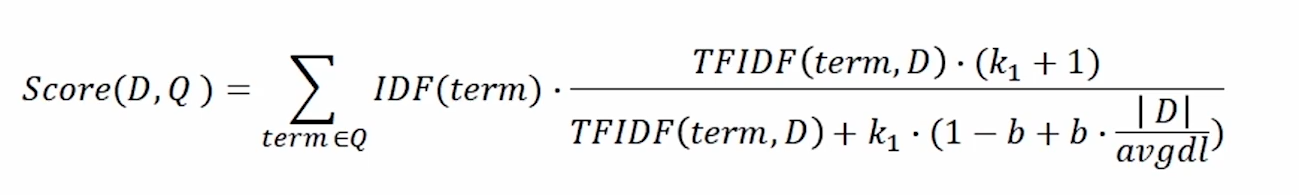
- TF-IDF의 개념을 바탕으로 문서의 길이까지 고려하여 점수를 매김
- TF에 한계값을 지정하여 일정 범위를 유지
- 평균적인 문서의 길이보다 더 작은 문서에서 단어가 매칭된 경우 그 문서에 가중치를 부여

NLP취준생