boost course 자연어처리의 모든 것의 강의를 보고 rnn에 대해 정리하였습니다.
RNN
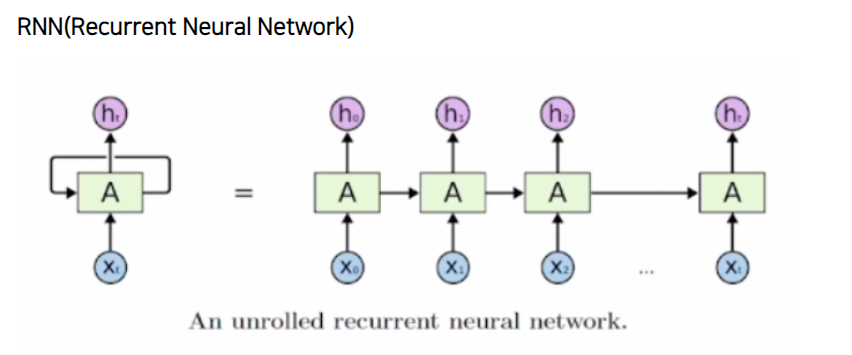
RNN은 입력과 출력을 시퀀스 단위로 처리하는 모델입니다. 현재 입력값에 대하여 이전 입력값들에 대한 정보를 바탕으로 예측값을 산출한다는 말입니다. 예를들어 I am a student라는 문장이 있고 RNN 모델이 있다고 가정해 봅시다. 현재 RNN 모델 안에는 무작위로 초기화된 Hidden state가 있습니다. 이때 RNN모델 안으로 처음에 I라는 단어가 들어가 Hidden state를 update하고 output(필요하다면)을 내놓게 됩니다. 그 다음 am이라는 단어가 들어갈 때에 I에서 만들어진 Hidden state를 이용하여 parameter들을 update하고 output(필요하다면)을 내놓게 됩니다. 그러면 현재 hidden state에는 I와 am의 정보가 담겨있게 되고 이런식으로 순서가 있는 sequence 정보를 처리하는 모델을 rnn이라고 합니다.
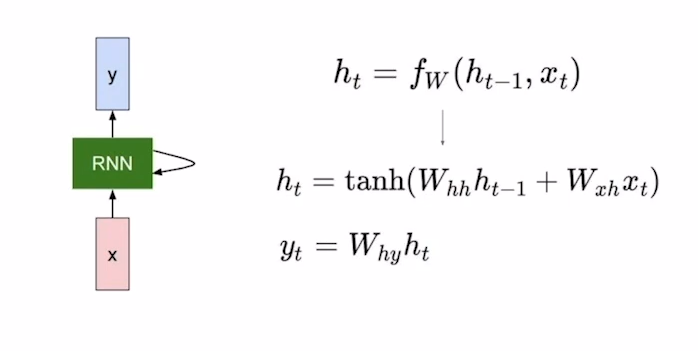
이제는 RNN을 좀 더 자세하게 들여다 보겠습니다.
- t - 시점(i am a student의 경우 i는 1, am 은 2...)
- h(t-1) - t-1시점의 hidden state
- h(t) - t시점의 hidden state
- x(t) - t시점의 input 값
- F(w) - RNN 함수(with parameter W)
- y(t) - t시점의 output 값
- tanh() - activation function tanh
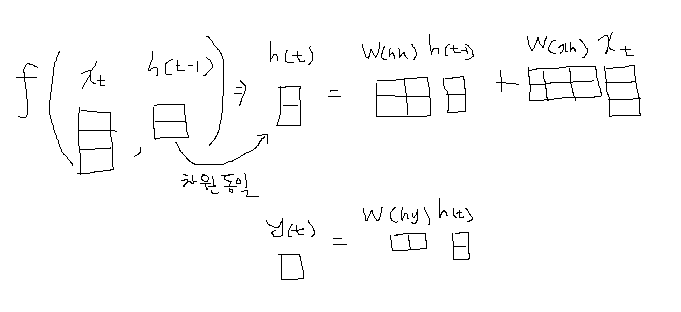
앞에서 RNN은 이전시점까지의 Hidden state를 사용한다고 말했습니다. 그래서 rnn의 입력으로는 이전시점까지의 hidden state( h(t-1) )와 현재시점의 input값( x(t) )이 들어갑니다. 두 값이 RNN( F(W) ) 모델에 input으로 들어가 선형변환을 거치게 되고 tanh함수를 이용하여 현재시점의 Hidden state( h(t) )를 생성하게 됩니다. 그 후 해당 t시점의 output이 필요하면 h(t)에 또 한번의 선형변환을 통하여 y(t)를 구하게 됩니다.
Types of RNN
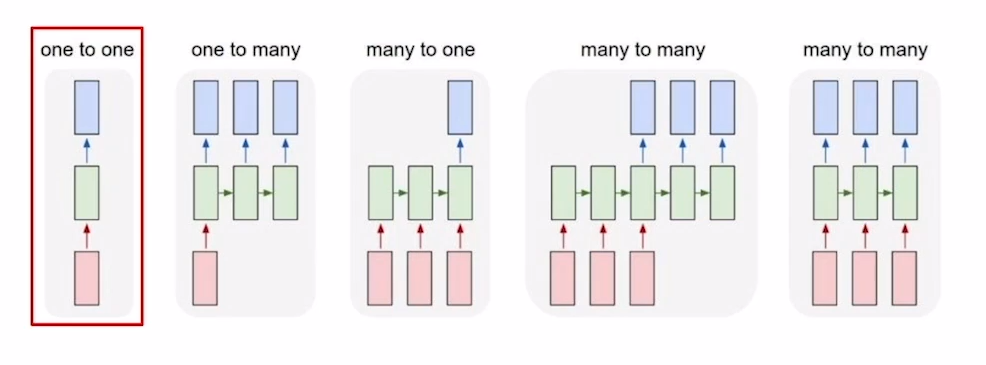
앞에서 RNN에 대하여 말씀을 드릴 때 매 시점마다 Output을 구하는 것이 아니라 필요하다면 Output을 구한다고 계속 말했습니다. RNN에서는 이러한 Output의 구조에 따라 여러가지 type이 존재하게 됩니다.
one-to-one(standard neural net)
[키, 몸무게, 나이]와 같은 정보를 입력값으로 할 때, 이를 통해 저혈압/고혈압인지 분류하는 형태의 태스크가 이 경우에 해당합니다.
one-to-many(image captioning)
하나의 이미지를 입력으로 주면 이미지에 대한 설명글을 시점별로 생성하는 형태의 task가 여기에 해당합니다. 원래 앞에서 말하기로는 RNN은 매 시점마다 input을 준다고 말하였습니다. 하지만 이 경우 입력이 처음 step에만 들어가는 것처럼 보입니다. 그래서 이 경우 첫시점 외에 나머지 시점에는 O으로 이루어진 Tensor를 입력으로 주게됩니다.
many-to-one(sentiment classification)
하나의 문장을 sequence 순서대로 입력을 주고 마지막 시점에 나온 hidden state를 가지고 output을 구하여 하나의 결과를 내는 경우가 여기에 속하게 됩니다.
many-to-many(machine translation)
i go home과 같은 문장을 입력으로 주고, 나는 집에 간다 라는 문장을 output으로 뽑아주는 이러한 task가 이 경우에 해당합니다. 이 경우는 입력을 줄 때 마다 output을 구해주어야 합니다.
Character level language model
training
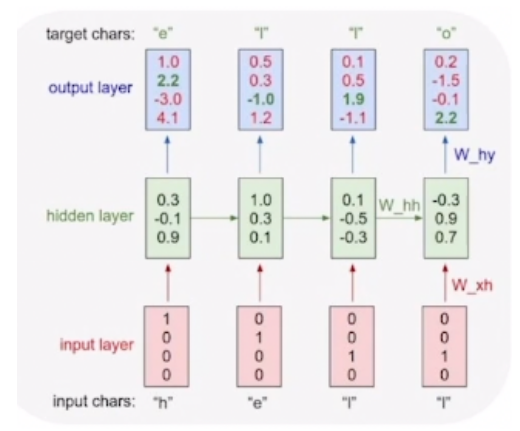
- many-to-many type으로 Character level에서 다음 Character를 예측하는 언어모델
- hello라는 단어가 있을 때 h가 주어지면 e를 예측하는 방식으로 hidden state 학습
- 다음에 올 단어를 예측하는 task이기 때문에 마지막 output의 dimension은 총 단어의 수
- 마지막 output logit에 softmax함수를 통하여 각 단어일 확률을 구하고 loss를 전달
예시를 보면 3, 4번째 input이 동일하지만 결과는 l, o로 달라져야함 -> hidden state의 차이
inference
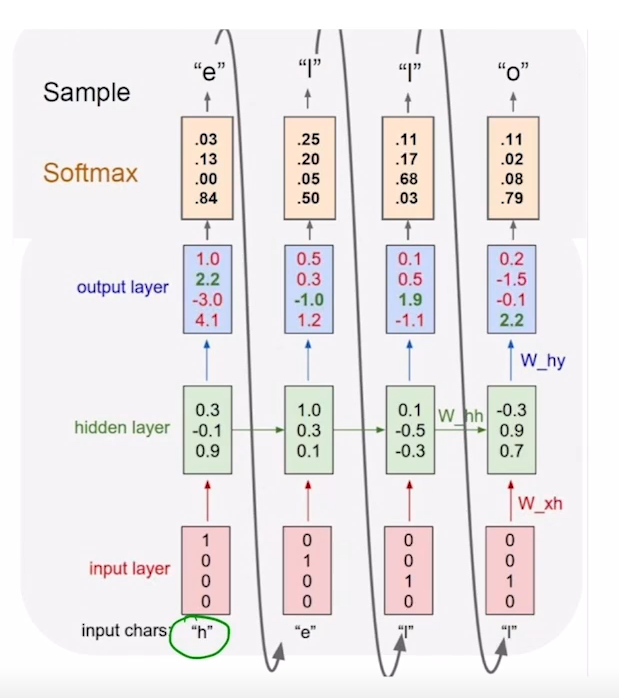
- 학습을 마친 후 inference를 진행할 때에는 이전의 output값을 다음 step의 input으로 사용
language model의 방법은 character level 보다 더 높은 word level 차원에서도 학습 가능하고 실제 코드쓰기나 소설쓰기 등 다양한 task가 가능함

