제약 조건명 지정하기
사용자가 의미있게 제약 조건명을 명시하여 제약 조건명만으로도 어떤 제약 조건을 위배했는지 알 수 있게
지정하는 방법
column_name data_type CONSTRAINT constraint_name constraint_type
제약 조건 명(constraing_name) 명명 규칙
[테이블명][칼럼명][제약조건 유형]
기본키 제약 조건명을 EMP05_EMPNO_PK로 지정했다면
EMP05_EMPNO_PK
테이블명 칼럼명 제약조건유형
EMP06 테이블을 생성(칼럼 레벨 형식)
CREATE TABLE EMP06(
EMPNO NUMBER(4) CONSTRAINT EMP06_EMPN_PK PRIMARY KEY,
ENAME VARCHAR2(10) CONSTRAINT EMP06_ENAME_NN NOT NULL,
JOB VARCHAR2(9) CONSTRAINT EMP06_JOB_UK UNIQUE,
DEPTNO NUMBER(2) CONSTRAINT EMP06_DEPTNO_FK REFERENCES DEPT01(DEPTNO)
);
insert into emp06
values(7499, 'ALLEN', 'SALEMAN',30);
select * from emp06;
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, table_name, r_constraint_name
from user_constraints where table_name='EMP06';
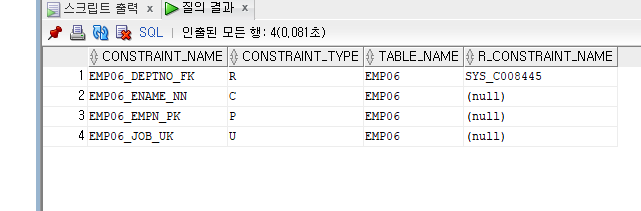
지정된 제약조건명을 확인할 수 있다.
다음은 제약조건 위배의 예시를 알아보자
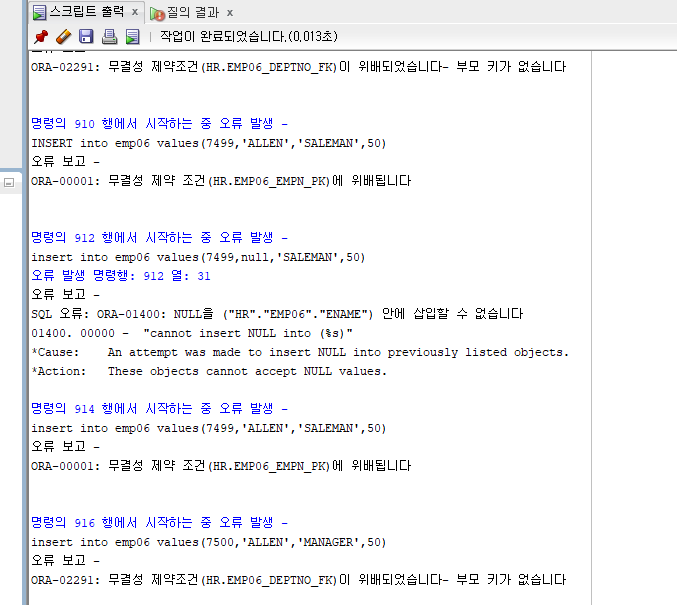
INSERT into emp06 values(7499,'ALLEN','SALEMAN',50);
insert into emp06 values(7499,null,'SALEMAN',50);
insert into emp06 values(7499,'ALLEN','SALEMAN',50);
insert into emp06 values(7500,'ALLEN','MANAGER',50);
테이블 레벨 방식으로 제약 조건 지정하기
ㆍ복합키로 기본키를 지정할 경우
칼럼레벨(NOT NULL,CHECK,DEFAULT 형식으로 불가능 반드시 테이블 레벨(기본키,유일키,외래키) 방식 사용
컬럼을 모두 정의하고 나서 테이블 정의를 마무리 짓기 전에 따로 생성된 컬럼들에 대한 제약조건을 한꺼번에 지정하는 것 NOT NULL 줄때는 컬럼 레벨만 가능
ㆍALTER TABLE로 제약 조건을 추가 할 때
테이블정의가 완료되어서 구조가 결정된 후 나중에 제약조건 추가하고자 할때 테이블 레벨 방식으로
제약조건 지정해야함
테이블 레벨 정의방식 기본형으로
CREATE TABLE table_name(
column_name1 datatype1,
column_name2 datatype2,
...
[CONSTRAINT constraint_name] constraint_type(column_name)
);
--테이블 레벨로 제약 조건을 지정하는 방식
CREATE TABLE EMP08(
empno number(4),
ename varchar2(10) not null,
job varchar2(9),
deptno number(2),
primary key(empno), //[CONSTRAINT EMP08)_EMPNO_PK] 는 오라클 서버가 자동생성해줌
unique(job),
foreign key(deptno) REFERENCES DEPT01(DEPTNO)
);
제약 조건 변경하기
ALTER TABLE table_name
ADD [CONSTRAINT CONSTRAINT_NAME] CONSTRAINTS_TYPE(COLUMN_NAME)
CREATE TABLE EMP09(
EMPNO NUMBER(4),
ENAME VARCHAR(4),
JOB VARCHAR2(9),
DEPTNO NUMBER(4)
);
--제약조건명을 명시하지 않고 기본키 추가
ALTER TABLE EMP09
ADD PRIMARY KEY(EMPNO);
--제약조건명을 명시하고 외래키 추가
ALTER TABLE EMP09
ADD CONSTRAINT EMP09_DEPTN_FK FOREIGN KEY(DEPTNO) REFERENCES DEPT01(DEPTNO);
-- ENAME 컬럼에 NOT NULL 제약조건 추가
ALTER TABLE EMP09
MODIFY(ENAME VARCHAR2(10) NOT NULL);
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, TABLE_NAME, R_CONSTRAINT_NAME
FROM USER_CONSTRAINTS
WHERE TABLE_NAME='DEPT01';
--HR 사용자로 생성한 DEPT01 테이블과 참조키(외래키) 설정 테이블 확인
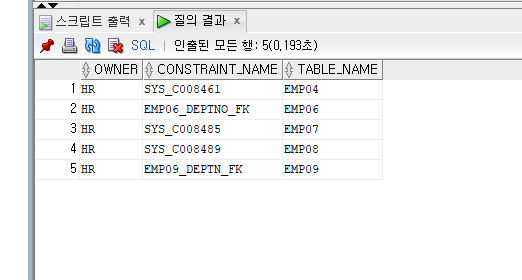
SELECT FK.owner, FK.constraint_name, FK.table_name
FROM all_constraints FK, all_constraints PK
WHERE FK.R_CONSTRAINT_NAME = PK.CONSTRIANT_NAME
AND PK.owner = 'HR'
AND FK.CONSTRAINT_TYPE = 'R'
AND PK.TABLE_NAME= 'DEPT01'
ORDER BY FK.TABLE_NAME;
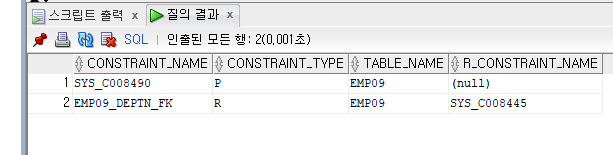
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, TABLE_NAME, R_CONSTRAINT_NAME
FROM USER_CONSTRAINTS WHERE TABLE_NAME='EMP09';
제약조건 제거하기
DROP CONSTRAINT 다음에 제거하고자 하는 제약 조건명을 명시한다.
ALTER TALBE table_name
DROP [CONSTRAINT constraint_name];
select constraint_name, constraint_type, table_name, r_constraint_name
from user_constraints where table_name='EMP06';
select * from emp06;
--ORA-00001: 무결성 제약 조건(HR.EMP06_EMPN_PK)에 위배됩니다
insert into emp06
values(7499, 'ALLEN','MANAGER',50);
ALTER TABLE EMP06
DROP CONSTRAINT EMP06_EMPNO_PK;
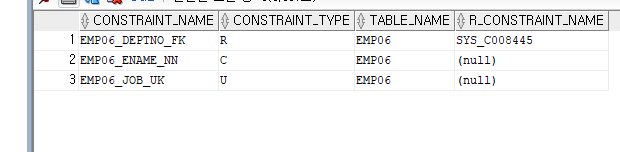
ALTER TABLE EMP06
DROP CONSTRAINT EMP06_DEPTNO_FK;
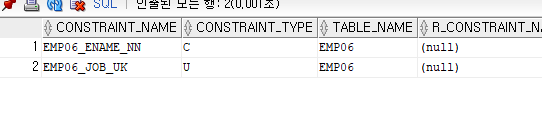
위 결과를 보면 기본키 제약조건이 제거된 것을 알 수 있다.
--외래키가 설정된 데이터 삭제 예
--우선 예제 실행을 위해 테이블 2개 생성
CREATE TABLE DEPT02(
DEPTNO NUMBER(2),
DNAME VARCHAR2(14) NOT NULL,
LOC VARCHAR2(13),
CONSTRAINT DEPT02_DEPTNO_PK PRIMARY KEY(DEPTNO)
);
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, TABLE_NAME, R_CONSTRAINT_NAME
FROM USER_CONSTRAINTS
WHERE TABLE_NAME='DEPT02';

--샘플 데이터 추가
INSERT INTO DEPT02 VALUES(10,'ACCOUNTING', 'NEW YORK');
INSERT INTO DEPT02 VALUES(20,'RESEARCH', 'DALLAS');
SELECT * FROM DEPT02;
--사원 테이블의 부서 번호가 부서 테이블의 부서 번호를 참조할 수 있도록 왜래키를 설정
DROP TABLE EMP02;
CREATE TABLE EMP02(
EMPNO NUMBER(4),
ENAME VARCHAR2(10) NOT NULL,
JOB VARCHAR2(9),
DEPTNO NUMBER(2),
CONSTRAINT EMP02_EMPNO_PK PRIMARY KEY(EMPNO),
CONSTRAINT EMP02_DEPTNO_FK FOREIGN KEY(DEPTNO) REFERENCES DEPT02(DEPTNO)
);
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, TABLE_NAME, R_CONSTRAINT_NAME
FROM USER_CONSTRAINTS WHERE TABLE_NAME='EMP02';

--샘플 데이터 추가
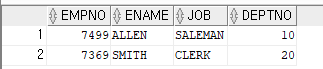
INSERT INTO EMP02 VALUES(7499, 'ALLEN', 'SALEMAN',10);
INSERT INTO EMP02 VALUES(7369, 'SMITH', 'CLERK',20);
SELECT * FROM EMP02;
-- 10번 부서를 20번으로 옮긴다.
UPDATE EMP02
SET DEPTNO =20
WHERE EMPNO =7499;
--ORA-02292: 무결성 제약조건(HR.EMP02_DEPTNO_FK)이 위배되었습니다- 자식 레코드가 발견되었습니다
DELETE FROM DEPT02 WHERE DEPTNO = 10;
--자식 테이블인 EMP02는 부모테이블인 DEPT02의 기본키인 부서번호를 참조하고 있어 삭제할 수 없다.
부서번호가 10번인 자료가 삭제되도록 하기 위해서는 아래와 같이 해야한다.
-사원 테이블(EMP02)의 10번 부서에서 근무하는 사원을 삭제한 후 부서 테이블(DEPT02)에서 10번 부서를 삭제한다.
-참조 무결성 때문에 삭제가 불가능하므로 EMP02 테이블의 외래키 제약 조건을 제거한 후에 10번 부서를 삭제한다.
ON ELETE CASCADE와 ON DELETE SET NULL
ON ELETE CASCADE와 ON DELETE SET NULL 옵션으로 삭제가 가능하다. 제약조건 다음에 아래 옵션을 명시
ON DELETE CASCADE 부모 테이블의 데이터가 삭제되면 자식 테이블의 데이터도 함께 삭제된다.
ON DELETE SET NULL 부모테이블의 데이터가 삭제되면 자식 테이블의 값이 NULL로 설정된다.

--진료과목 테이블
CREATE TABLE TREATMENT(
T_NO NUMBER(4) NOT NULL,
T_COURSE_ABBR VARCHAR2(3) NOT NULL,
T_COURSE VARCHAR2(30) NOT NULL,
T_TEL VARCHAR2(15) NOT NULL,
CONSTRAINT TREATMENT_NO_PK PRIMARY KEY(T_NO),
CONSTRAINT TREATMENT_COURSE_ABBR_UK UNIQUE(T_COURSE_ABBR)
);
--테이블의 컬럼에 주석을 다는 구문
--표현식
--COMMENT ON COLUMN 테이블명.컬럼명 IS '주석 내용';
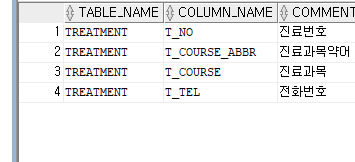
COMMENT ON COLUMN TREATMENT.T_NO IS '진료번호';
COMMENT ON COLUMN TREATMENT.T_COURSE_ABBR IS '진료과목약어';
COMMENT ON COLUMN TREATMENT.T_COURSE IS '진료과목';
COMMENT ON COLUMN TREATMENT.T_TEL IS '전화번호';
INSERT INTO TREATMENT(T_NO, T_COURSE_ABBR, T_COURSE, T_TEL)
VALUES(1001, 'NS', '신경외과', '02-3452-1009');
INSERT INTO TREATMENT(T_NO, T_COURSE_ABBR, T_COURSE, T_TEL)
VALUES(1002, 'OS', '정형외과', '02-3452-2009');
INSERT INTO TREATMENT(T_NO, T_COURSE_ABBR, T_COURSE, T_TEL)
VALUES(1003, 'C', '순환기내과', '02-3452-3009');
SELECT * FROM TREATMENT;

CREATE TABLE DOCTOR(
D_NO NUMBER(4) NOT NULL,
D_NAME VARCHAR2(20) NOT NULL,
D_SSN CHAR(14) NOT NULL,
D_EMAIL VARCHAR2(80) NOT NULL,
D_MAJOR VARCHAR2(50) NOT NULL,
T_NO NUMBER(4),
CONSTRAINT DOCTOR_D_NO_PK PRIMARY KEY(D_NO)
);
ALTER TABLE DOCTOR
ADD CONSTRAINT DOCTOR_T_NO FOREIGN KEY(T_NO) REFERENCES TREATMENT(T_NO)
ON DELETE CASCADE;
INSERT INTO DOCTOR(D_NO, D_NAME, D_SSN, D_EMAIL, D_MAJOR, T_NO)
VALUES(1,'홍길동', '660606-1234561', 'javauser@naver.com','척추신경외과',1001);
INSERT INTO DOCTOR(D_NO, D_NAME, D_SSN, D_EMAIL, D_MAJOR, T_NO)
VALUES(2,'이재환', '690724-1674536', 'jaehwan@naver.com','뇌졸중,뇌혈관외과',1003);
INSERT INTO DOCTOR(D_NO, D_NAME, D_SSN, D_EMAIL, D_MAJOR, T_NO)
VALUES(3,'양익환', '700129-1328962', 'sheep1209@naver.com','인공관절,관절염',1002);
INSERT INTO DOCTOR(D_NO, D_NAME, D_SSN, D_EMAIL, D_MAJOR, T_NO)
VALUES(4,'김승현', '720901-134890', 'seunghyeon@naver.com','종양외과,외상전문',1002);
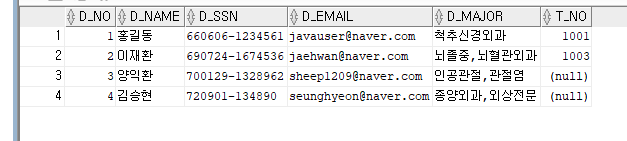
select * from doctor;

delete from treatment where T_NO = 1002;
SELECT FROM TREATMENT;
SELECT FROM DOCTOR;
ROLLBACK;
ALTER TABLE DOCTOR
DROP CONSTRAINT DOCTOR_T_NO;
ALTER TABLE DOCTOR
ADD CONSTRAINT DOCTOR_T_NO FOREIGN KEY(T_NO) REFERENCES TREATMENT(T_NO)
ON DELETE SET NULL;
DELETE FROM TREATMENT where T_NO = 1002;
SELECT FROM TREATMENT;
SELECT FROM DOCTOR;

JOIN
한개 이상의 테이블에서 원하는 결과를 얻기 위한 조인을 학습
Equi Join, Non-Equi Join, Outer Join, Self Join 방식을 학습
하나의 테이블에 대해서 sql 명령어를 사용하였다. 하지만 관계형 데이터베이스에서는 테이블간의 관계가 중요하기 때문에 하나 이상의 테이블이 빈번히 결합되어 사용된다. 한개 이상의 테이블에서 데이터를 조회하기 위해서 사용되는것이 조인(JOIN)이다.
Equi Join 동일 칼럼을 기준으로 조인 (inner join, simple join)
NonEqui Join 동일 칼럼이 없이 다른 조건을 사용하여 조인
Outer Join 조인 조건에 만족하지 않는 행도 나타난다.
Self Join 한 테이블 내에서 조인
WHERE 절에 명시하는 조건이 FROM 절에 명시한 여러 Table을 묶는 join 조건이 된다. 이러한 Join조건은 반드시 묶어야 할 Table 수보다 하나가 적다. 즉 Table 수가 n개라면 Join조건은 n-1 이 된다.
1)Cartesian Product(카티션 곱) 또는 Cross Join
Cross Join 이란 2개 잇상의 테이블이 조인될 때 WHERE절에 의해 공통되는 칼럼에 의한 결합이 발생되지 않는 경우를 말한다. 그렇기 때문에 테이블에 존재하는 모든 데이터가 검색 결과로 나타난다.
다음은 Cross Join으로 특별한 키워드 없이 SELECT문의 FROM절에 EMPLOYEES테이블과 DEPARTMENTS 테이블을 동시에기술
SELECT *
FROM EMPLOYEES,DEPARTMENTS;
조인은 3개 4개 이상의 테이블을 한꺼번에 연결하는 것이 아닌
2개씩 테이블을 연결한다.
기본적으로 조인은 다음과 같은 규칙을 준수
1) Primary key와 Foreign Key 컬럼을 통한 다른 테이블의 행과 연결
2) 연결 Key 사용으로 테이블과 테이블이 결합
3) WHERE 절에서 조인 조건을 사용 (조인 조건 개수 = 연결 테이블 수-1)
4) 명확성을 위해 칼럼 이름 앞에 테이블명 또는 테이블 별칭을 붙임.
조인은 수행될 때는 두 개 이상의 테이블이 사용되는데 이때 둘 중 하나의 테이블을 먼저 읽고 조인 조건 절을 확인하여 나머지 테이블에 가서 데이터를 가져오게 된다. 이 떄 먼저 읽는 테이블을 선행테이블(diving table 또는 inner table)이라고 하고 뒤에 읽는 테이블을 후행 테이블(driven table 또는 Outer table)이라고 한다. 그리고 선행 테이블은 조회할 데이터가 적은 테이블로 선택해야 속도면에서 유리
2)Equi Join
Equi Join은 가장 많이 사용하는 조인 방법이다. 조인 대상이 되는 두 테이블에서 공통적으로 존재하는 칼럼의 값이 일치되는 행을 연결하여 결과를 생성하는 조인 방법.
employees 테이블과 departments 테이블의 공통 칼럼인 DEPARTMENT_ID 값이 일치(=) 되는 조건을
WHERE 절에서 사용
두 테이블을 조인하려면 일치되는 공통 칼럼을 사용해야 한다. 칼럼 명이 같게 되면 혼동이 오기 때문에 칼럼명 앞에 테이블명을 점(.)과 함게 기술
SELECT FIRST_NAME, DEPARTMENT_NAME
FROM EMPLOYEES, DEPARTMENTS
WHERE EMPLOYEES. DEPARTMENT_ID = DEPARTMENTS.DEPARTMENT_ID;
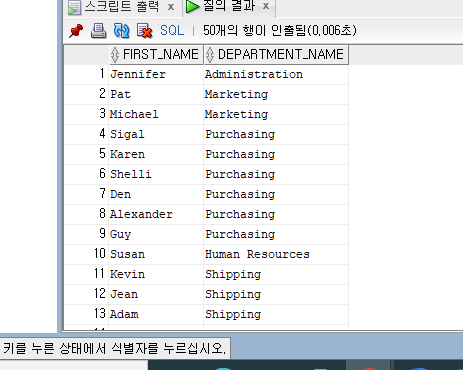
조인한 결과를 살펴보면 부서번호를 기준으로 같은 값을 가진 사원 테이블과 부서 테이블이 결합되었다.
조인은 Primary key와 foreign Key를 통한 다른 테이블 행과 연결한다.
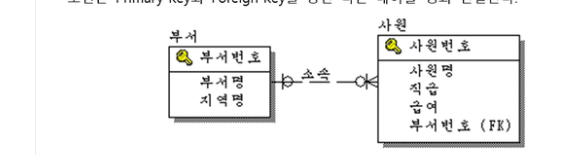
부서 테이블의 Primary key인 부서번호가 사원 테이블의 Foreign Key 로 설정되어 있다.
이 연결 Key를 WHERE 절에서 조인 조건에 사용하였다. 비교 연산자로 "="를 사용하였으므로 이를
Equi Join이라고 한다.
WHERE EMPLOYEES.DEPARTMNET_ID = DEPARTMENT.DEPARTMENT_ID
테이블 명이 너무 긴 경우에는 테이블 명에 간단하게 별칭을 부여해서 문장을 간단하게 기술할 수 있다.
테이블 명의 별칭은 FROM 절 다음에 테이블 이름을 명시하고 공백을 둔 다음에 별칭을 지정한다.
FROM EMPLOYEES E, DEPARTMENTS D
테이블명 별칭 테이블명 별칭
-- 조인시 공통컬럼을 조회하고자 할때는 반드시 테이블명.컬럼 또는 테이블 별칭.컬럼으로 명시.
-- ORA-00918: 열의 정의가 애매합니다.
SELECT FIRST_NAME, DEPARTMENT_NAME, DEPARTMENT_ID
FROM EMPLOYEES, DEPARTMENTS
WHERE EMPLOYEES.DEPARTMENT_ID = DEPARTMENTS.DEPARTMENT_ID; //DEPARTMENT_ID가 양쪽다 존재하는 컬럼이기 때문에
SELECT FIRST_NAME, DEPARTMENT_NAME, EMPLOYEES.DEPARTMENT_ID
FROM EMPLOYEES, DEPARTMENTS
WHERE EMPLOYEES.DEPARTMENT_ID = DEPARTMENTS.DEPARTMENT_ID;
SELECT EMPLOYEE_ID, FIRST_NAME, DEPARTMENT_ID
FROM EMPLOYEES;
SELECT DEPARTMENT_ID, DEPARTMENT_NAME
FROM DEPARTMENTS;
SELECT FIRST_NAME, DEPARTMENT_NAME
FROM EMPLOYEES, DEPARTMENTS
WHERE EMPLOYEES. DEPARTMENT_ID = DEPARTMENTS.DEPARTMENT_ID;
SELECT FIRST_NAME, DEPARTMENT_NAME, E.DEPARTMENT_ID
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID;
SELECT E.FIRST_NAME, D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID AND E.FIRST_NAME='Susan';
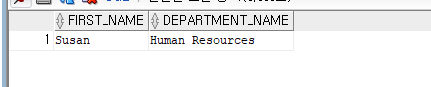
SELECT * FROM JOBS;
--사원 테이블(EMPLOYEES)과 직무 테이블(JOBS) => 공통컬럼: JOB_ID
--사원 테이블(EMPLOYEES)과 부서 테이블(DEPARTMENTS) => 공통컬럼: DEPARTMENT_ID
--사원명, 직무ID, 직무명(JOB_TITLE), 부서번호, 부서명을 출력해 주세요.
SELECT FIRST_NAME, E.JOB_ID,J.JOB_TITLE,D.DEPARTMENT_ID, D.DEPARTMENT_NAME //FIRST_NAME은 사원 테이블에만 있기 때문에 앞에 알파벳. 안써두됨
FROM EMPLOYEES E, DEPARTMENTS D, JOBS J
WHERE E.JOB_ID = J.JOB_ID AND E.DEPARTMENT_ID = D.DEPARTMENT_ID;
3)Non-Equi Join
Non-Equi 조인은 조인할 테이블 사이에 칼럼의 값이 직접적으로 일치하지 않을 시 사용하는 조인으로 '='을 제외한 연산자를 사용한다.
SELECT FIRST_NAME, E.JOB_ID,J.JOB_TITLE,D.DEPARTMENT_ID, D.DEPARTMENT_NAME //FIRST_NAME은 사원 테이블에만 있기 때문에 앞에 알파벳. 안써두됨
FROM EMPLOYEES E, DEPARTMENTS D, JOBS J
WHERE E.JOB_ID = J.JOB_ID AND E.DEPARTMENT_ID = D.DEPARTMENT_ID;
--Non-Equi Join
--급여 등급 테이블
CREATE TABLE SALARYGRADE(
GRADE NUMBER,
MINSALARY NUMBER,
MAXSALARY NUMBER
);
INSERT INTO SALARYGRADE (GRADE, MINSALARY, MAXSALARY) VALUES(1, 2000, 3000);
INSERT INTO SALARYGRADE (GRADE, MINSALARY, MAXSALARY) VALUES(2, 3001, 4500);
INSERT INTO SALARYGRADE (GRADE, MINSALARY, MAXSALARY) VALUES(3, 4501, 6000);
INSERT INTO SALARYGRADE (GRADE, MINSALARY, MAXSALARY) VALUES(4, 6001, 8000);
INSERT INTO SALARYGRADE (GRADE, MINSALARY, MAXSALARY) VALUES(5, 8001, 10000);
INSERT INTO SALARYGRADE (GRADE, MINSALARY, MAXSALARY) VALUES(6, 10001, 13000);
INSERT INTO SALARYGRADE (GRADE, MINSALARY, MAXSALARY) VALUES(7, 13001, 20000);
INSERT INTO SALARYGRADE (GRADE, MINSALARY, MAXSALARY) VALUES(8, 20001, 30000);
SELECT * FROM SALARYGRADE;
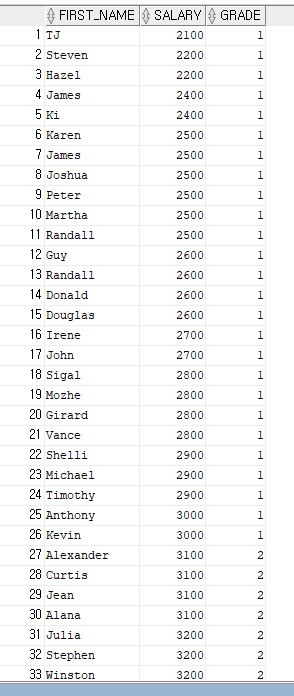
--사원명, 급여 ,등급을 출력해 주세요.
SELECT E.FIRST_NAME, E.SALARY, S.GRADE
FROM EMPLOYEES E, SALARYGRADE S
WHERE E.SALARY BETWEEN S.MINSALARY AND S.MAXSALARY;
SELECT E.FIRST_NAME, E.SALARY, S.GRADE
FROM EMPLOYEES E, SALARYGRADE S
WHERE E.SALARY >= S.MINSALARY AND E.SALARY <= S.MAXSALARY;
아래 결과를 보면 등급별로 출력이 되는것을 알 수 있다.
4)Outer Join
행이 조인 조건에 만족하지 않을 경우 그 행은 결과에 나타나지 않게 된다. 이때 조인 조건에 만족하지 않는 행들도 나타내기 위해 Outer Join이 사용된다.
--사원 테이블과 부서 테이블을 조인하여 사원 이름과 부서번호와 부서명을 출력한다.
SELECT E.FIRST_NAME, D.DEPARTMENT_ID, D.DEPARTMENT_NAME
FROM EMPLOYEES E , DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID
ORDER BY D.DEPARTMENT_ID;
SELECT *FROM DEPARTMENTS;
SELECT E.FIRST_NAME, D.DEPARTMENT_ID, D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID(+) = D.DEPARTMENT_ID; // Outer Join을 하기 위해서 사용하는 기호는(+)이며
//조인 조건에서 정보가 부족한 칼럼명 뒤에 위치하게 하면 된다. 사원테이블에 부서번호 120번 이상이 없기 때문에 E.DEPARTMENT_ID쪽에 +를 붙인다.

아래 결과를 보면 사원은 존재하지 않기 때문에 NULL값이 있지만 부서번호 120번 이상 의 부서도 출력되는것을 확인할 수 있다.

--Outer join
--부서테이블의 부서번호는 전부 출력하고 사원테이블에 데이터는 조건에 일치하는 데이터만 출력할 때
--Outer Join을 사용.
SELECT E.FIRST_NAME, D.DEPARTMENT_ID, D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID(+) = D.DEPARTMENT_ID; // Outer Join을 하기 위해서 사용하는 기호는(+)이며
//조인 조건에서 정보가 부족한 칼럼명 뒤에 위치하게 하면 된다. 사원테이블에 부서번호 120번 이상이 없기 때문에 E.DEPARTMENT_ID쪽에 +를 붙인다.
// ↑↓ 같은 표현
SELECT E.FIRST_NAME, D.DEPARTMENT_ID, D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE D.DEPARTMENT_ID =E.DEPARTMENT_ID(+);
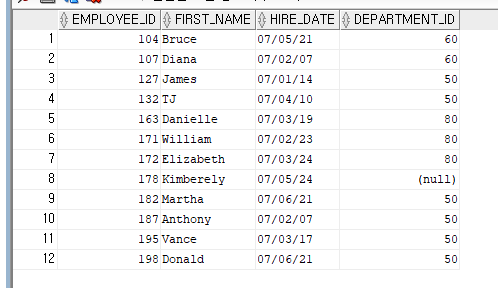
--2007년도 상반기에 입사한 사원의 사원번호, 이름, 입사일, 부서번호를 구해보자.
--(결과 행의 수 : 12)
SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE,DEPARTMENT_ID
FROM EMPLOYEES
WHERE HIRE_DATE >= '2007/01/01' AND HIRE_DATE <= '2007/06/30';
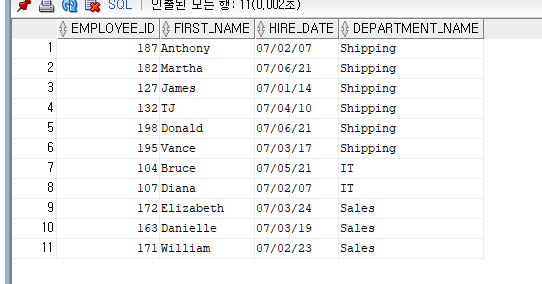
--2007년도 상반기에 입사한 사원의 사원번호, 이름 , 입사일, 부서명을 출력
--(결과 행의 수 :11 )
SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE, D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID AND
HIRE_DATE >= '2007/01/01' AND HIRE_DATE <= '2007/06/30';
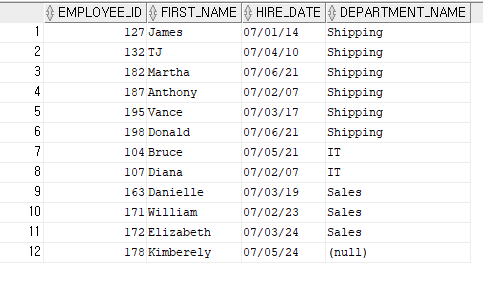
SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE, D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID(+) //사원이 부족한게아니라 부서가 부족함
AND HIRE_DATE >= '2007/01/01' AND HIRE_DATE <= '2007/06/30';
Self Join
자기 자신과 조인을 맺는 것. FROM 절 다음에 동일한 테이블명을 2번 기술하고 WHERE 절에도 조인 조건을 주어야 하는데 이때 서로 다른 테이블인 것처럼 인식할 수 있도록 하기 위해서 별칭을 사용
--SELF JOIN
-- 사원명과 사원의 매니저(상사) 이름을 출력하기 위한 쿼리문
SELECT WORK.FIRST_NAME 사원명, MANAGER.FIRST_NAME 매니저명
FROM EMPLOYEES WORK, EMPLOYEES MANAGER
WHERE WORK.MANAGER_ID = MANAGER.EMPLOYEE_ID;

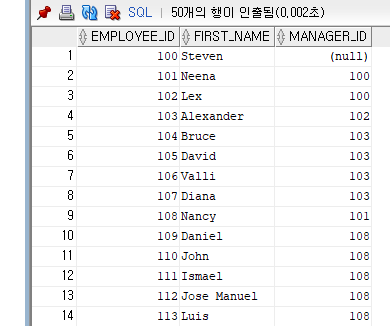
-- 사원 테이블(사원번호, 사원명, 관리자번호)
SELECT EMPLOYEE_ID, FIRST_NAME, MANAGER_ID
FROM EMPLOYEES;
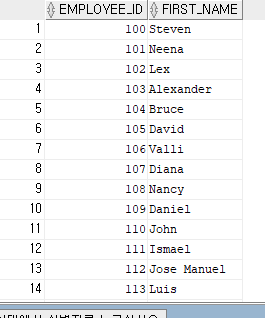
-- 관리자 테이블(관리자번호가 사원번호이므로 관리자사원번호, 관리자명)
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES ORDER BY EMPLOYEE_ID;
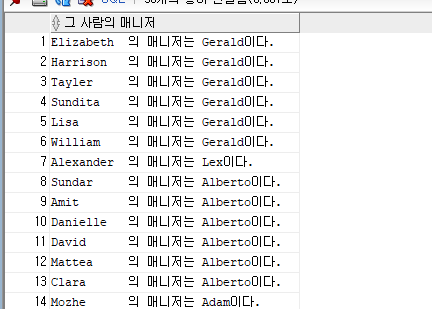
SELECT RPAD(WORK.FIRST_NAME,11,' ') ||'의 매니저는' || MANAGER.FIRST_NAME||'이다.' AS "그 사원의 매니저"
FROM EMPLOYEES WORK, EMPLOYEES MANAGER
WHERE WORK.MANAGER_ID = MANAGER.EMPLOYEE_ID;
SELECT CONCAT(CONCAT(CONCAT(RPAD(WORK.FIRST_NAME,11,' '), '의 매니저는 '), MANAGER.FIRST_NAME),'이다.') AS "그 사람의 매니저"
FROM EMPLOYEES WORK, EMPLOYEES MANAGER
WHERE WORK.MANAGER_ID = MANAGER.EMPLOYEE_ID;
ANSI Join
sql은 대부분의 상용데이터베이스 시스템에서 표준 언어이다.
다른 DBMS와의 호환성을 위해서는 ANSI 조인을 사용하는 것이 좋다.
ANSI 표준 SQL조인 구문은 몇 가지 새로운 키워드와 절을 제공하여, SELECT 문의 FROM절에서 조인을 완벽하게 지정할 수 있다.
1)ANSI Cross Join
이전에는 쉼표(,)로 테이블 명을 구분하였으나 쉼표 대신 CROSS JOIN이라고 명확하게 지정
SELECT *FROM EMPLOYEES CROSS JOIN DEPARTMENTS;
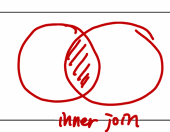
2) ANSI Inner Join ★
앞서 배운 조인 구문 중 공통 칼럼을 '='(equal) 비교연산자를 통해 같은 값을 가지는 로우를 연결하는 형태이나 ANSI Inner Join은 다음과 같은 형식으로 작성
SELECT * FROM table1 INNER JOIN table2
ON table1.column = table2.column
WHERE 조건문
-- INNER JOIN
SELECT FIRST_NAME, DEPARTMENT_NAME
FROM EMPLOYEES INNER JOIN DEPARTMENTS
ON EMPLOYEES.DEPARTMENT_ID = DEPARTMENTS.DEPARTMENT_ID;
--JOIN만 작성 시 기본값은 INNER JOIN
SELECT FIRST_NAME, DEPARTMENT_NAME
FROM EMPLOYEES JOIN DEPARTMENTS
ON EMPLOYEES.DEPARTMENT_ID = DEPARTMENTS.DEPARTMENT_ID;
--사원 테이블(EMPLOYEES)과 직무 테이블(JOBS) => 공통컬럼: JOB_ID
--사원 테이블(EMPLOYEES)과 부서 테이블(DEPARTMENTS) => 공통컬럼: DEPARTMENT_ID
--사원명, 직무ID, 직무명(JOB_TITLE), 부서번호, 부서명을 출력해 주세요.
SELECT E.FIRST_NAME, E.JOB_ID, J.JOB_TITLE, E.DEPARTMENT_ID, D.DEPARTMENT_NAME
FROM EMPLOYEES E INNER JOIN JOBS J ON E.JOB_ID = J.JOB_ID
INNER JOIN DEPARTMENTS D ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;
3)-USING을 이용한 조인 조건 지정
두 테이블 간의 조인 조건에 사용되는 칼럼이 같다면 ON 대신 USING을 사용가능
SELECT * FROM table1 INNER JOIN table2
USING(공통칼럼)
- 연결에 사용하려는 컬럼 명이 같은 경우 USING() 사용, 다른 경우 ON() 사용
SELECT EMPLOYEES.FIRST_NAME, DEPARTMENTS.DEPARTMENT_NAME
FROM EMPLOYEES INNER JOIN DEPARTMENTS
USING(DEPARTMENT_ID);
4)ANSI Outer Join
기존 조인에서는 반드시 모든 레코드가 출력되어야 되는 경우 '(+)'표시를 했다.
ANSI구문의 OUTER JOIN에서는 이전에 지원하지 않았던 FULL까지 지원
SELECT*FROM table1[LEFT|RIGHT|FULL] OUTER JOIN table2
--OUTER JOIN
SELECT E.FIRST_NAME, D.DEPARTMENT_ID, D.DEPARTMENT_NAME
FROM EMPLOYEES E RIGHT OUTER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;
SELECT E.FIRST_NAME, D.DEPARTMENT_ID, D.DEPARTMENT_NAME
FROM DEPARTMENTS D LEFT OUTER JOIN EMPLOYEES E
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;
--2007년 상반기에 입력한 사원번호, 사원명, 입사일, 부서명을 출력해 주세요
SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE, D.DEPARTMENT_NAME
FROM EMPLOYEES E LEFT OUTER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID
WHERE HIRE_DATE BETWEEN '2007/01/01' AND '2007/06/30';
-- 사용자 계정 생성
-- 사용자를 생성하기 위해서는 DBA만 사용자를 생성할 수 있다. 그래서 최고권한자(SYSDBA)인 SYS로 접속.
-- create user 사용자명 identified by 비밀번호; (비밀번호는 대소문자 구분합니다.)
CREATE USER javauser IDENTIFIED BY java1234;
--비밀번호 변경 시
ALTER USER javauser IDENTIFIED BY java1234;
-- 사용자 권한 부여
-- 오라클은 사용자 생성시 어떠한 권한도 가지고 있지 않기에 권한 부여를 해주어야 한다.
-- grant 권한 to 사용자명;
//GRANT CREATE SESSION TO javauser;
--grant 롤 to 사용자명;
GRANT CONNECT, RESOURCE TO javauser;
// 접속권한 생성권한
--RESOURCE : 사용자 계정으로 TABLE을 생성 이용할 수 있는 권한
--CONNECT : 사용자가 DB에 접속할 수 있는 권한
ALTER USER javauser
DEFAULT TABLESPACE users QUOTA UNLIMITED ON users; //users에 대해서 권한을 한정하지 않고 주기
--CONNECT 롤에 포함된 권한 - CREATE SESSION 권한이 없으면 해당 유저로 접속이 되지 않음
SELECT * FROM role_sys_privs
WHERE role='CONNECT';
--RESOURCE 롤에 포함된 권한
SELECT * FROM role_sys_privs
WHERE role='RESOURCE';
--create 트리거, 시퀸스, 타입, 프로시저, 테이블 등 8가지 권한이 부여되어있음
-- 먼저 JAVAUSER에게 부여된 롤 확인
select * from dba_role_privs
where GRANTEE = 'JAVAUSER';

