ㆍ숫자형을 문자형으로 변환하기
TO_CHAR(숫자, '출력형식')
--문자형으로 변환하는 TO_CHAR 함수(간편한 날짜 변환)
SELECT SYSDATE, TO_CHAR(SYSDATE, 'YYYY-MM-DD'), TO_CHAR(SYSDATE,'DL')
FROM DUAL;
SELECT TO_CHAR(HIRE_DATE, 'YYYY/MM/DD DAY')
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 30;
SELECT TO_CHAR(HIRE_DATE, 'YYYY"년" MM"월" DD"일" DAY') HIRE_DATE
FROM EMPLOYEES
WHERE DEPARTMENT_ID=30;
SELECT TO_CHAR(HIRE_DATE, 'YYYY/MON/DD DY')
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 30;
SELECT TO_CHAR(SYSDATE, 'DDD') --365일 기준 345일
,TO_CHAR(SYSDATE, 'WW') --1년 기준 50주
,TO_CHAR(SYSDATE, 'Q') --4분기
FROM DUAL;
SELECT TO_CHAR(SYSDATE, 'PM'),
TO_CHAR(SYSDATE,'PM HH:MI:SS'),
TO_CHAR(SYSDATE,'HH24"시" MI"분" SS"초"')
FROM DUAL;
--오늘 날짜와 시간 출력
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS') FROM DUAL;
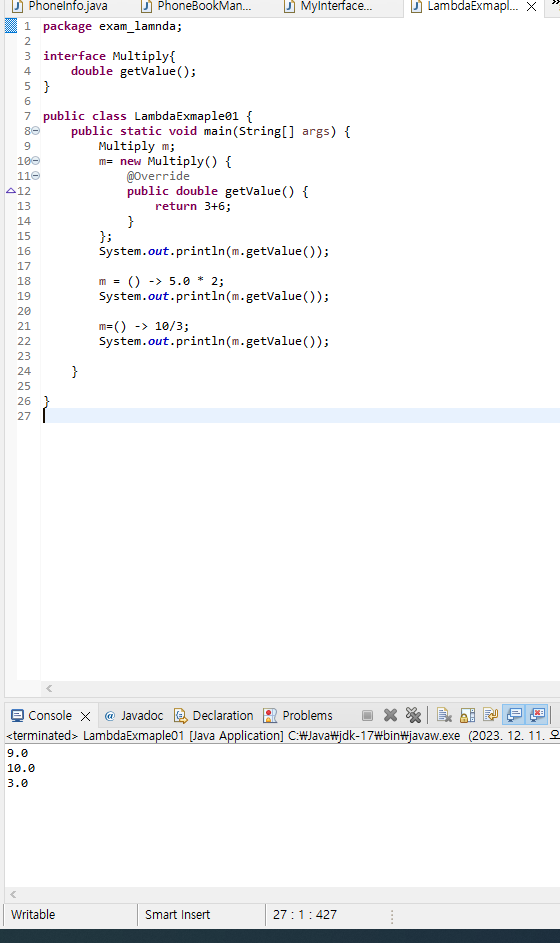
-형 변환함수의 숫자 출력 형식
구분 설명
0 자릿수를 나타내며 자릿수가 맞지 않을 경우 0으로 채운다.
9 자릿수를 나타내며 자릿수가 맞지 않아도 채우지 않는다.
L 각 지역별 통화 기호를 앞에표시
. 소수점
, 천 단위 자리 구분
--숫자형을 문자형으로 변환하기
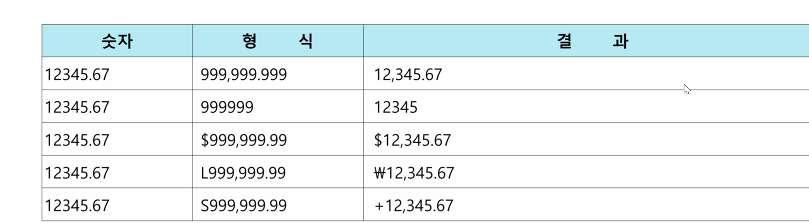
SELECT TO_CHAR(1234, '999,999'), --1234
TO_CHAR(123467,'FM999,999'), --123,467
TO_CHAR(123467890,'FM999,999,999'), --123,467,890
TO_CHAR(123467,'FML999,999') --\123,467
FROM DUAL;

--FM: 문자열의 공백 제거
--숫자의 최대 길이만큼 9999...., 형식을 지정한다. (9 : 값이 없으면 표시안함, 0:값이 없으면 "0"으로 처리)
--정수는 지정한 형식보다 값의 길이가 길면 정확하게 표현불가, 소수 지정한 길이보다 길면 반올림
SELECT TO_CHAR(1,'00') FROM DUAL;
SELECT TO_CHAR(1,'FM00') FROM DUAL;
실행해 보면 FM을 넣은 예제의 결과는 공백이 제거된것을 확인할 수 있다.
--날짜형으로 변환하는 TO_DATE 함수
--2005년 12월 24일에 입사한 직원을 검색
SELECT FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
WHERE HIRE_DATE = '05/12/24';
SELECT FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
WHERE HIRE_DATE = TO_DATE('20051224','YYYYMMDD');
--문자열 데이터 210505'를 '2021년 05월 05일'로 표현하고자 한다.
--ORA-01481: 숫자 형식 모델이 부적합합니다
SELECT TO_CHAR ('210505', 'YYYY"년" MM"월" DD"일"') FROM DUAL;
--해결
SELECT TO_CHAR (TO_DATE('210505','YYMMDD'), 'YYYY"년" MM"월" DD"일"') AS 날짜 FROM DUAL;
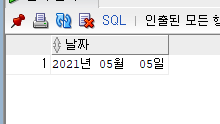
--문자열 데이터'210505를 '2021년 05월 05일'로 표현(날짜의 "0"없애기)
SELECT TO_CHAR(TO_DATE('210505','YYMMDD'), 'YYYY"년" fmMM"월" DD"일"') AS 날짜 FROM DUAL;
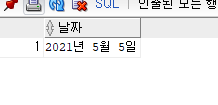
05월 05일에서 0을 제거하고자 할때는 위의 예제처럼 FM을 붙이면 된다.
-- 올해 며칠이 지났는지 날짜 계산 <= 오류발생
-- ORA- 01722: 수치가 부적합합니다
SELECT SYSDATE-'2023/10/13' FROM DUAL;
--올해 며칠이 지낫는지 날짜 계산 <= 오류 해결
SELECT TRUNC(SYSDATE-TO_DATE('2023/01/01', 'YYYY/MM/DD')) AS 기간 FROM DUAL;
일반 함수
구분 설명
NVL 첫번쨰 인자로 받은 값이 NULL과 같으면 두 번째 인자 값으로 변경
DECODE 첫번쨰 인자로 받은 값을 조건에 맞춰 변경(IF와 유사)
CASE 조건에 맞는 문장을 수행(SWITCH와 유사)
NULL을 비교할 때는 IS NULL 또는 IS NOT NULL 구문을 사용하였는다, 오라클에서는 NULL을 연산 대상으로 처리하는 SQL함수를 제공하고있다.
1NULL을 다른 값으로 변환하는 NVL 함수
NULL을 0 또는 다른 값으로 변환하기 위해서 사용하는 함수
NVL(컬럼 또는 표현식, 대체값)
SELECT FIRST_NAME, SALARY, COMMISSION_PCT,JOB_ID
FROM EMPLOYEES ORDER BY JOB_ID;
--NULL을 다른 값으로 변환하는 NVL함수
--NVL(컬럼, 컬럼의 값이 NULL일 때 대체값);
SELECT FIRST_NAME, SALARY, COMMISSION_PCT, JOB_ID
FROM EMPLOYEES
ORDER BY JOB_ID;
SELECT FIRST_NAME, SALARY, NVL(COMMISSION_PCT, 0 ), JOB_ID
FROM EMPLOYEES
ORDER BY JOB_ID;
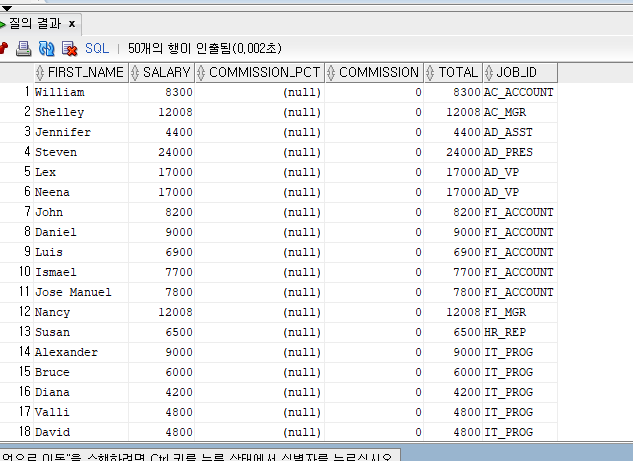
SELECT FIRST_NAME, SALARY, COMMISSION_PCT,
SALARY COMMISSION_PCT AS COMMISSION,
SALARY + (SALARY COMMISSION_PCT) AS TOTAL, JOB_ID
FROM EMPLOYEES
ORDER BY JOB_ID;
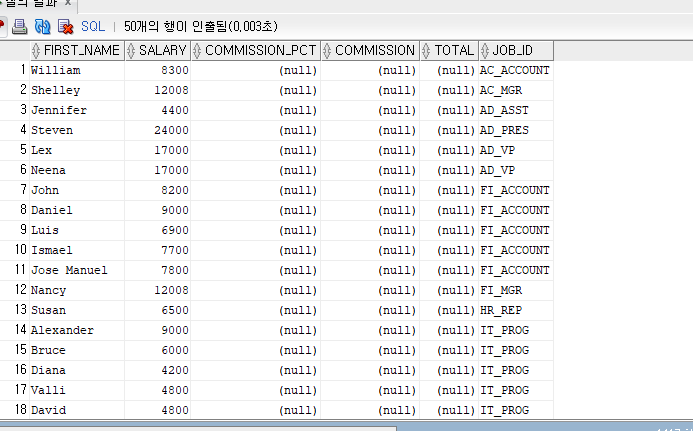
SELECT FIRST_NAME, SALARY, COMMISSION_PCT,
SALARY NVL(COMMISSION_PCT,0) AS COMMISSION,
SALARY + (SALARY NVL(COMMISSION_PCT,0)) AS TOTAL, JOB_ID
FROM EMPLOYEES
ORDER BY JOB_ID;
NULL값을 연산신에 사용하면 NULL값이 되므로
NULL값을 NVL함수로 0값으로 대체함으로써 나타내 보았다.
NULL값 은 없다
--<문제> 모든 직원은 자신의 상관(MANAGER_ID)이 있다.
--하지만 EMPLOYEES 테이블에 유일하게 상관이 없는 로우가 있는데 그 사원의 MANAGER_ID 칼럼 값이 NULL이다.
--상관이 없는 대표이사만 출력하되 MANAGER_ID 칼럼 값 NULL 대신 CEO로 출력한다.
SELECT EMPLOYEE_ID, FIRST_NAME, NVL(MANAGER_ID, 0)
FROM EMPLOYEES
WHERE MANAGER_ID IS NULL;
--ORA -01722: 수치가 부적합합니다
SELECT EMPLOYEE_ID, FIRST_NAME, NVL(MANAGER_ID,'CEO')
FROM EMPLOYEES
WHERE MANAGER_ID IS NULL;
SELECT FIRST_NAME, SALARY, NVL(TO_CHAR(MANAGER_ID),'CEO')
FROM EMPLOYEES;
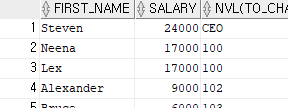
위 사진을 보면 숫자형태인 MANAGER_ID값을 TO_CHAR로 문자형태로 바꾼 후
NULL값을 CEO라고 변경 한 것을 확인 할 수 있다.
선택을 위한 DECODE 함수
SWITCH CASE 문과 같이 여러가지 경우에 대해서 선택할 수 있는 함수
DECODE(표현식, 조건1, 결과1, 조건2, 결과2, 조건3, 결과3, ... 조건절외 나머지결과N)
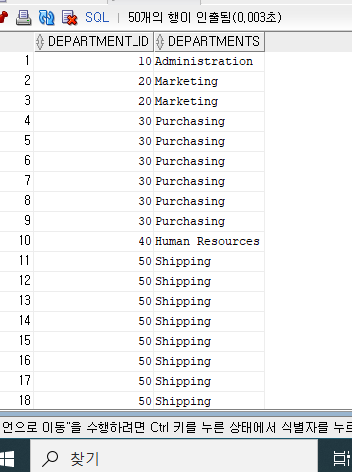
ex 부서명 구하기
select * from departments;
--선택을 위한 DECODE 함수
select department_id, decode(department_id,
10,'Administration',
20,'Marketing',
30,'Purchasing',
40,'Human Resources',
50 ,'Shipping',
60,'IT') AS DEPARTMENTS
FROM EMPLOYEES
WHERE DEPARTMENT_ID BETWEEN 10 AND 60
ORDER BY DEPARTMENT_ID;
조건에 따라 서로 다른 처리가 가능한 CASE 함수
CASE WHEN 조건1 THEN 결과1
WHEN 조건2 THEN 결과2
WHEN 조건3 THEN 결과3
ELSE 결과N
END
--조건에 따라 서로 다른 처리가 가능한 CASE 함수 (범위 설정 가능)
SELECT EMPLOYEE_ID, FIRST_NAME, DEPARTMENT_ID,
CASE WHEN DEPARTMENT_ID = 10 THEN 'Administraion'
WHEN DEPARTMENT_ID = 20 THEN 'Marketing'
WHEN DEPARTMENT_ID = 30 THEN 'Purchasing'
WHEN DEPARTMENT_ID = 40 THEN 'Human Resources'
WHEN DEPARTMENT_ID = 50 THEN 'Shipping'
WHEN DEPARTMENT_ID = 60 THEN 'IT'
--ELSE 'Public Relations'
END DEPARTMENT_NAME
FROM EMPLOYEES
WHERE DEPARTMENT_ID BETWEEN 10 AND 60
ORDER BY DEPARTMENT_ID;
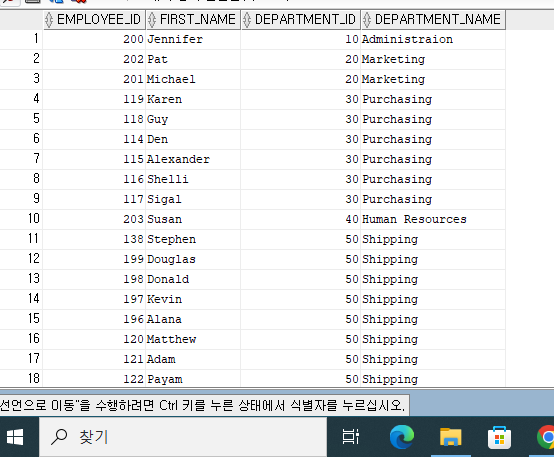
위 코드를
줄인 예제이다.
SELECT EMPLOYEE_ID, FIRST_NAME, DEPARTMENT_ID,
CASE DEPARTMENT_ID WHEN 10 THEN 'Administraion'
WHEN 20 THEN 'Marketing'
WHEN 30 THEN 'Purchasing'
WHEN 40 THEN 'Human Resources'
WHEN 50 THEN 'Shipping'
WHEN 60 THEN 'IT'
END DEPARTMENT_NAME
FROM EMPLOYEES
WHERE DEPARTMENT_ID BETWEEN 10 AND 60
ORDER BY DEPARTMENT_ID;
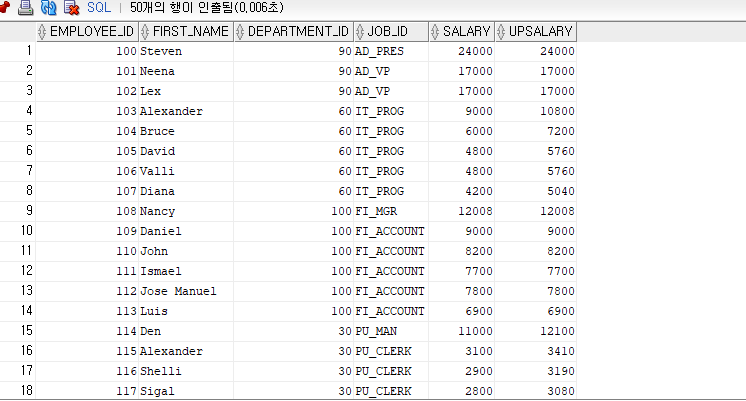
--<문제> 부서명에 따라 급여를 인상하도록 하자. (직원번호, 직원명, 직급, 급여)
--부서명이 'Marketing'인 직원은 5%, 'Purchasing'인 사원은 10%, 'Human Resources'인 사원은 15%,
--'IT'인 직원은 20%인 인상한다.
--부서명으로 조건 부여
select EMPLOYEE_ID, FIRST_NAME, E.DEPARTMENT_ID,JOB_ID, JOB_ID, SALARY,
CASE WHEN DEPARTMENT_NAME = 'Marketing' THEN SALARY 1.05
WHEN DEPARTMENT_NAME = 'Purchasing' THEN SALARY1.10
WHEN DEPARTMENT_NAME = 'Human Resources' THEN SALARY 1.15
WHEN DEPARTMENT_NAME = 'IT' THEN SALARY 1.20
ELSE SALARY
END UPSALARY
FROM EMPLOYEES E INNER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID
ORDER BY EMPLOYEE_ID;
SELECT EMPLOYEE_ID, FIRST_NAME, E.DEPARTMENT_ID, JOB_ID, SALARY,
CASE DEPARTMENT_NAME WHEN 'Marketing' THEN SALARY 1.05
WHEN 'Purchasing' THEN SALARY 1.10
WHEN 'Human Resources' THEN SALARY 1.15
WHEN 'IT' THEN SALARY 1.20
ELSE SALARY
END AS UPSALARY
FROM EMPLOYEES E INNER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID
ORDER BY EMPLOYEE_ID;
그룹 함수
SUM, AVG, MIN, MAX, COUNT
칼럼의 값별로 그룹 함수의 결과 값을 구하는 GROUP BY 절을 학습
그룹의 결과를 제한할 때는 HAVING절을 학습
1) 그룹 함수의 종류
SUM 그룹의 누적 합계를 반환
ABG 평균을 반환
MAX 최댓값을 반환
MIN 최솟값을 반환
COUNT 총 개수를 반환
NULL을 저장한 컬럼과 연산한 결과는 NULL이다. 그러나 그룹함수는 다른 연산자와는 달리, 해당 칼럼 값이NULL인 것을 제외하고 계산하기때문에 결과를 NULL로 반환하지 않는다. 그래서 로우(레코드) 개수 구하는 COUNT 함수는 NULL값에 대해서는 세지 않는다
--그룹함수
--<예> 직원의 총 급여 구하기(SUM함수)
SELECT SUM(SALARY) FROM EMPLOYEES;
SELECT TO_CHAR(SUM(SALARY),'$999,999') AS TOTAL
FROM EMPLOYEES;
--<예> 직원의 평균 급여 구하기 (AVG함수)
SELECT AVG(SALARY)
FROM EMPLOYEES;
--ROUND: 반올림 함수 ROUND(숫자,자릿수), ROUND(숫자) = ROUND(숫자, 0)
SELECT ROUND(AVG(SALARY),1)
FROM EMPLOYEES;
--FLOOR: 절사(소숫점이하 버림)
// FLOOR소수점 자리 버리는것
SELECT FLOOR(AVG(SALARY))
FROM EMPLOYEES;
--<예> 최근에 입사한 사원가 가장 오래전에 입사한 직원의 입사일 출력하기(MAX/MIN함수)
SELECT TO_CHAR(MAX(HIRE_DATE), 'YYYY.MM.DD'), TO_CHAR(MIN(HIRE_DATE), 'YYYY.MM.DD')
FROM EMPLOYEES;

--<예> 사원수 구하기(COUNT 함수)
SELECT COUNT(*), COUNT(EMPLOYEE_ID), COUNT(COMMISSION_PCT)
FROM EMPLOYEES;
SELECT JOB_ID FROM EMPLOYEES;
SELECT DISTINCT JOB_ID FROM EMPLOYEES;
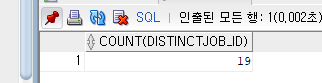
--<문제> JOB_ID의 종류가 몇 개인지 즉, 중복되지 않은 직업의 개수를 구해보자.
SELECT COUNT(DISTINCT JOB_ID) FROM EMPLOYEES;
--컬럼과 그룹 함수를 같이 사용할 때 유의할 점
--결과:ORA-00937: 단일 그룹의 그룹 함수가 아닙니다
SELECT FIRST_NAME, MIN(SALARY) FROM EMPLOYEES;

GROUP BY 절을 사용해 특정 조건으로 세부적인 그룹화하기
SELECT 칼럼명, 그룹함수(컬럼명)
FROM 테이블명
WHERE 조건문
GROUNP BY 칼럼명
-특정 그룹으로 묶어 데이터 집계시 사용
-WEHRE와 ORDER BY절 사이에 위치
-집계(그룹)함수와 함께 사용
-SELECT 리스트에서 집계(그룹)함수와 함께 사용
-SELECT 리스트에서 집계(그룹)함수를 제외한 모든 컬럼과 표현식은 GROUP BY절에 명시해야함
하지만 GROUP BY 절에 사용된 컬럼이라도 SELECT 절에는 사용되지 않아도 된다.
-컬럼과 그룹 함수를 같이 사용할 때 유의할 점
--결과:ORA-00937: 단일 그룹의 그룹 함수가 아닙니다
SELECT FIRST_NAME, MIN(SALARY) FROM EMPLOYEES;
--사원들을 부서번호를 기준으로
SELECT DEPARTMENT_ID
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;
--<예> 부서별 최대 급여와 최소 급여 구하기
SELECT DEPARTMENT_ID, MAX(SALARY)"최대 급여",
MIN(SALARY)"최소 급여"
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;
SELECT DEPARTMENT_ID, MAX(SALARY)"최대 급여" , MIN(SALARY)"최소 급여", ROUND(AVG(SALARY),1)
FROM EMPLOYEES
WHERE DEPARTMENT_ID='10'
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;
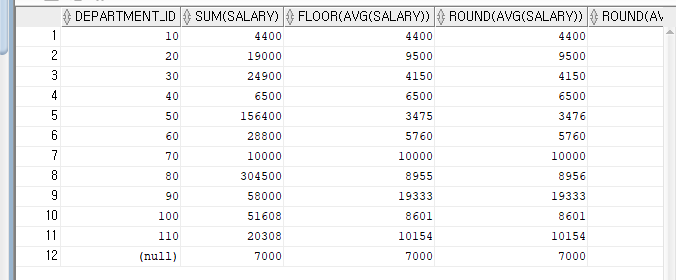
--<예> 소속 부서별 급여의 합과 평균 구하기
SELECT DEPARTMENT_ID, SUM(SALARY) "급여의 합", ROUND(AVG(SALARY),1)"급여의 평균"
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;
-- 위 쿼리문에서 평균값 소수점 이하 절사.
SELECT DEPARTMENT_ID, SUM(SALARY) "급여의 합", FLOOR(AVG(SALARY))"급여의 평균"
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;
-- 소수점 처리에 관한 쿼리문
SELECT DEPARTMENT_ID,
SUM(SALARY),
FLOOR(AVG(SALARY)),
ROUND(AVG(SALARY)),
ROUND(AVG(SALARY),1)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;
GROUP BY 절에는 반드시 컬럼명이 사용되어야 하며 별칭 사용불가
HAVING 조건
SELECT 절에 조건을 사용하여 결과를 제한할 때는 WHERE 절을 사용하지만, 그룹의 결과를 제한할 때는 HAVING절을 사용함.
-GROUP BY절 다음에 위치해 GROUP BY한 결과를 대상으로 다시 필터를 거는 역할
-HAVING 다음에는 SELECT 리스트에 사용했던 집계함수를 이용한 조건을 명시
SELECT DEPARTMENT_ID, AVG(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID;
SELECT DEPARTMENT_ID, FLOOR(AVG(SALARY))
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING FLOOR(AVG(SALARY)) >= 5000
ORDER BY DEPARTMENT_ID;
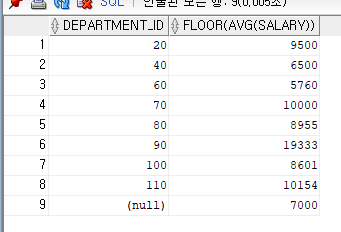
--급여가 3000 이상인 사원들에 대해 부서별 급여의 평균
SELECT DEPARTMENT_ID, FLOOR(AVG(SALARY))
FROM EMPLOYEES
WHERE SALARY >= 3000
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;
-- 급여의 평균이 5000 이상인 부서별 정보 출력
SELECT DEPARTMENT_ID, FLOOR(AVG(SALARY))
FROM EMPLOYEES
WHERE SALARY >= 3000
GROUP BY DEPARTMENT_ID
HAVING AVG(SALARY) >= 5000
ORDER BY DEPARTMENT_ID;
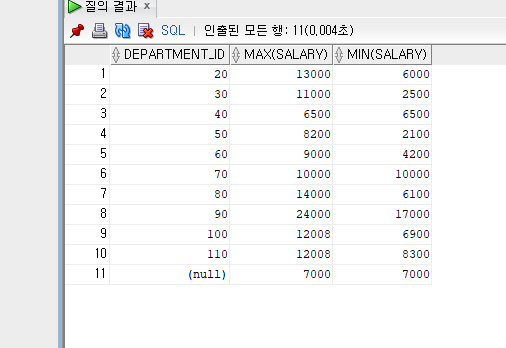
SELECT DEPARTMENT_ID, SALARY
FROM EMPLOYEES
--부서별 최대급여와 최소급여를 출력하되 최대 급여가 5000초과한 부서만 출력하는 쿼리문 작성
SELECT DEPARTMENT_ID, MAX(SALARY), MIN(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING MAX(SALARY) > 5000
ORDER BY DEPARTMENT_ID;
SELECT DEPARTMENT_ID,COUNT(EMPLOYEE_ID)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING COUNT(EMPLOYEE_ID) > 4
ORDER BY DEPARTMENT_ID;
람다식 사용하기
추상메서드가 하나일때만 사용가능
람다식 기본
람다식을 사용하여 인터페이스 구현하고 생성 후 사용하는 함수형 스타일로 코드 작성
1)일반 인터페이스 구현
public static MyInterface test3(){
return new MyInterface(){
@Override
public void print(){
System.out.println("Hello");
}
};
}
test3() 메서드에서 반환된 익명 클래스를 사용하려면 다음처럼 test3() 메서드를 호출하고, 반환되는 값을 저장. 이때 반환하는 익명 클래스가 구현한 MyInterface 타입으로 참조변수를 선언 후 참조변수를 이용해 print() 메서드 호출
MyInterface m = test3();
m.print(): // test3() 메서드에서 반환된 MyInterface
2)람다식 구현
바로 앞에서 구현한 코드를 람다식으로 구현
MyInterface m = () -> System.out.println("Hello");

메서드의 매개변수들이 선언되는 괄호()는 그대로 표현하고, 인터페이스에 선언된 추상 메서드의 본문을 구현할 때는 화살표(->) 기호 다음에 작성. 본문을 구현할 때 명령문이 한줄이면 위와 같이 작성하고, 여러 줄일 때는 중괄호{}로 감싸준다.
이떄 인터페이스에 선언된 추상 메서드가 여러개일때는 어떤 메서드의 본문인지 구별방법X
따라서 람다식으로 구현하려는 인터페이스는 반드시 하나의 메서드만 선언되어야 함★
그리고 하나의 메서드만 선언된 인터페이스를 "함수형 인터페이스"라고 한다.
람다식 구현 = 함수형 인터페이스
3) 람다식 문법
() -> 명령문; < 함수형 인터페이스의 추상 메서드 구현시 명령문이 한개일 때
() ->{ < 함수형 인터페이스의 추상 메서드 구현시 명령문이 여러 개일 때
명령문1;
명령문n;
};