아무리 사소하더라도 배움이 없는 날은 없다.
SQL 문제풀이
간단한 문제들이라 따로 풀이를 남길 건 없었다.
이번 주 안에 프로그래머스 sql문제는 다 풀 수 있을 듯.
SELECT id,
CASE
WHEN size_of_colony <= 100 THEN 'LOW'
WHEN size_of_colony > 100
AND size_of_colony <= 1000 THEN 'MEDIUM'
WHEN size_of_colony > 1000 THEN 'HIGH'
end AS SIZE
FROM ecoli_data
ORDER BY 1 SELECT Sum(hg.score) AS SCORE,
hg.emp_no,
he.emp_name,
he.position,
he.email
FROM hr_grade hg
INNER JOIN hr_employees he
ON hg.emp_no = he.emp_no
WHERE hg.year = '2022'
GROUP BY 2,
3,
4,
5
ORDER BY 1 DESC
LIMIT 1 SELECT Count(*) AS FISH_COUNT
FROM fish_info fi
INNER JOIN fish_name_info fni
ON fi.fish_type = fni.fish_type
WHERE fish_name = 'BASS'
OR fish_name = 'SNAPPER'SELECT Round(Avg(Ifnull(length, 10)), 2) AVERAGE_LENGTH
FROM fish_info SELECT id,
length
FROM fish_info
WHERE length IS NOT NULL
ORDER BY 2 DESC,
1
LIMIT 10 여기서부터는 머신러닝 공부 겸
개인적인 흥미가 있어서 진행한
클러스터링 과정을 정리해 보기로 했다.
심화프로젝트 때 해 보고 싶었던 주제기도 했고
(결국 최종 주제는 다른 것이 선택됐지만),
출신이 커머스인지라 한 번 제대로 정리해 두면 나중에 쓸 곳이 있겠다 싶기도 해서.
클러스터링 프로젝트
🌺 데이터셋은 총 5개의 CSV 파일로 구성되어 있습니다.
- Retail_dataset.csv 파일에 ERD(테이블 구조도) 및 컬럼 설명이 기재되어 있습니다.
🌺 각 테이블을 결합하여, 클러스터링을 위한 하나의 데이터셋으로 만들어주세요.
- 모든 테이블을 결합하지 않아도 좋습니다.
- 다만, 테이블 결합 시 알맞은 결합 방식을 사용해주세요.
🌺 필수 사항
- 이상치 처리 기법을 활용하거나, 특정 기준을 세워 이상치를 정의 하고 그 이유를 설명해주세요.
- 클러스터링시, 초기 군집의 갯수와 사용할 컬럼의 갯수는 python 머신러닝 라이브러리를 활용하여 진행해주세요.
- 컬럼별 raw data 분포를 그려주세요.
- 컬럼 간 상관계수를 히트맵 차트로 구현해주세요.(유의미한 기준은 +0.6(양의 상관관계) 또는 -0.6(음의 상관관계)으로 판단해주시면 됩니다)
🌺 선택 사항
- 필요하다면 파생변수를 생성해도 좋습니다.
- 데이터 표준화가 필요한 경우 진행해주세요. 표준화 방법을 여러가지 사용해보시고, 비교해주셔도 됩니다.
- 범주형 데이터를 사용할 경우, 인코딩을 진행해주세요. 원-핫 인코딩/라벨인코딩 모두 사용해도 됩니다. 다만, 범주의 갯수가 많은 경우, 별도 세그멘테이션이 필요할 수 있겠습니다. 의미있는 기준을 세워주시고 그 값을 인코딩 진행해주세요. (예시: 국가가 100개인 경우 육대륙으로 나누어 인코딩). 참고자료: https://nicola-ml.tistory.com/62#google_vignette
- 분석 결과를 한 눈에 파악할 수 있도록 datapane 으로 리포트를 구현해주세요.
1. 데이터 불러오기
데이터 출처 : https://www.kaggle.com/datasets/quangvinhhuynh/marketing-and-retail-analyst-e-comerce
다운받은 데이터는 총 7개 파일로 이루어져 있다.
이 중 Retail_dataset은 ERD를 포함한 컬럼 정의가 기술되어 있는 파일이고, capstone_data_cleaned는 (뒤에 cleaned가 붙은 걸로 봐서) 전처리까지 완료된 일종의 샘플 데이터 같은 게 아닐까 싶었다. 따라서 실제 분석에는 위의 2개를 제외한, 5개의 데이터셋만 사용하기로 했다.
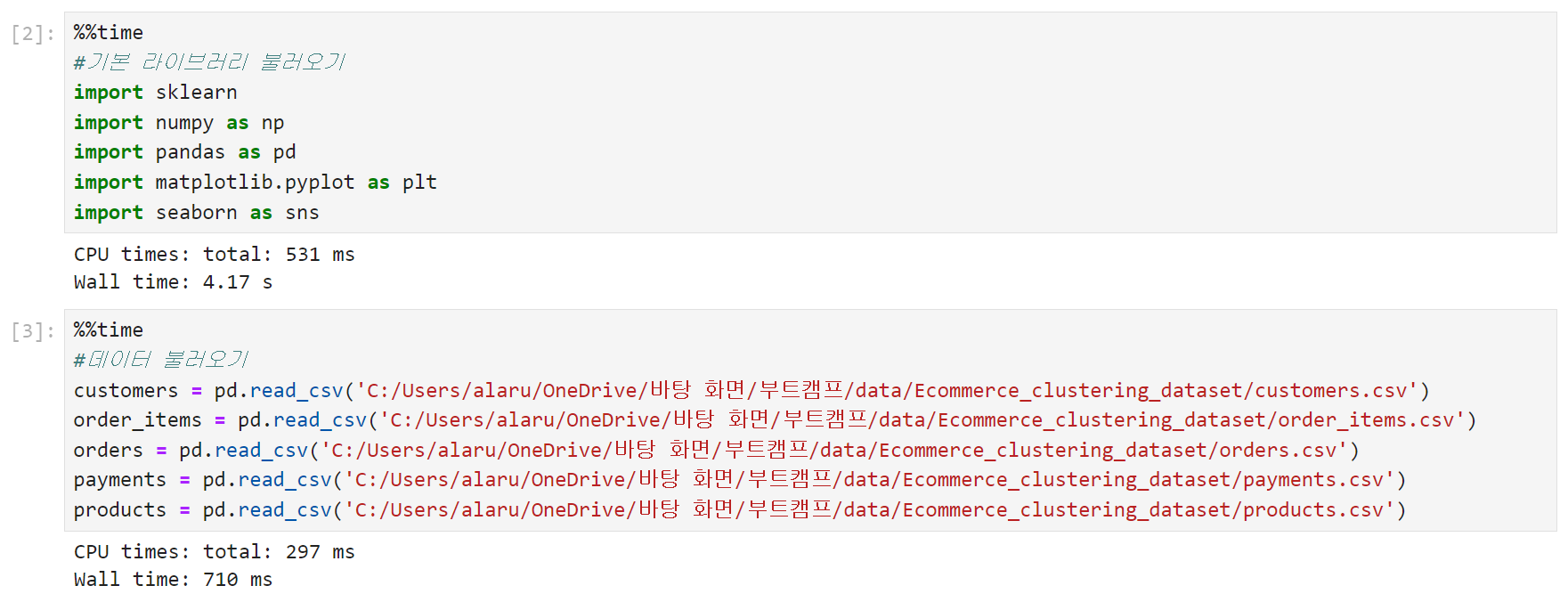
2. EDA
불러온 데이터를 하나씩 살펴보는 단계.
고객(customers) 테이블은 id, 우편번호, 도시, 그리고 해당 도시가 속한 주(state)의 5개 컬럼으로 이루어져 있다. 예를 들어 첫 번째 고객은 상파울로(SP) 주 franca에 사는 사람인 셈. 불러와놓고 보니 브라질 데이터였다(!)
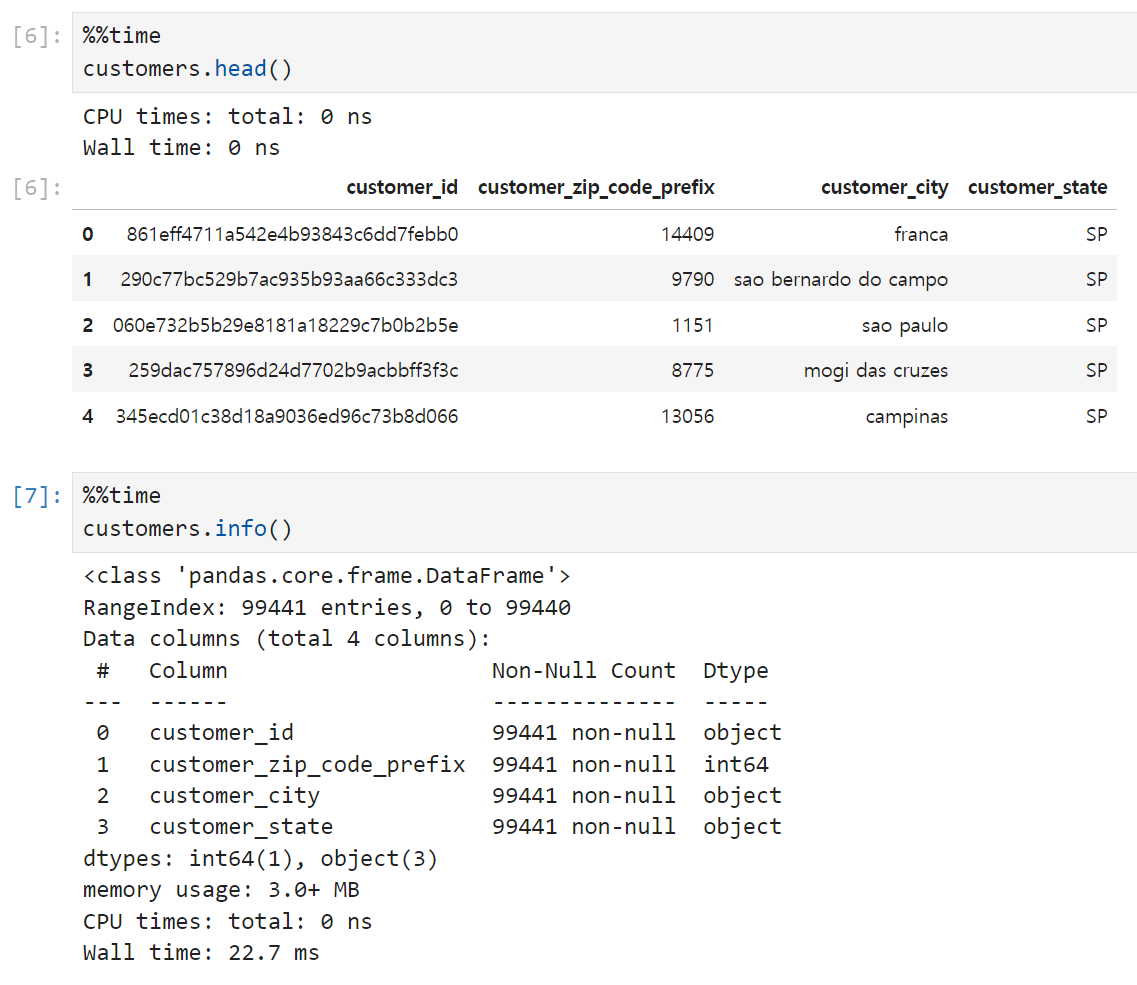
결측치는 없고, 이 테이블에는 이상치라고 부를 만한 컬럼이 없다.
따라서 별도의 전처리까진 필요없을 듯.
주문 상품(order_items) 테이블은 총 6개 컬럼 & 112,650 row로 구성되어 있고, 결측치는 없었다.
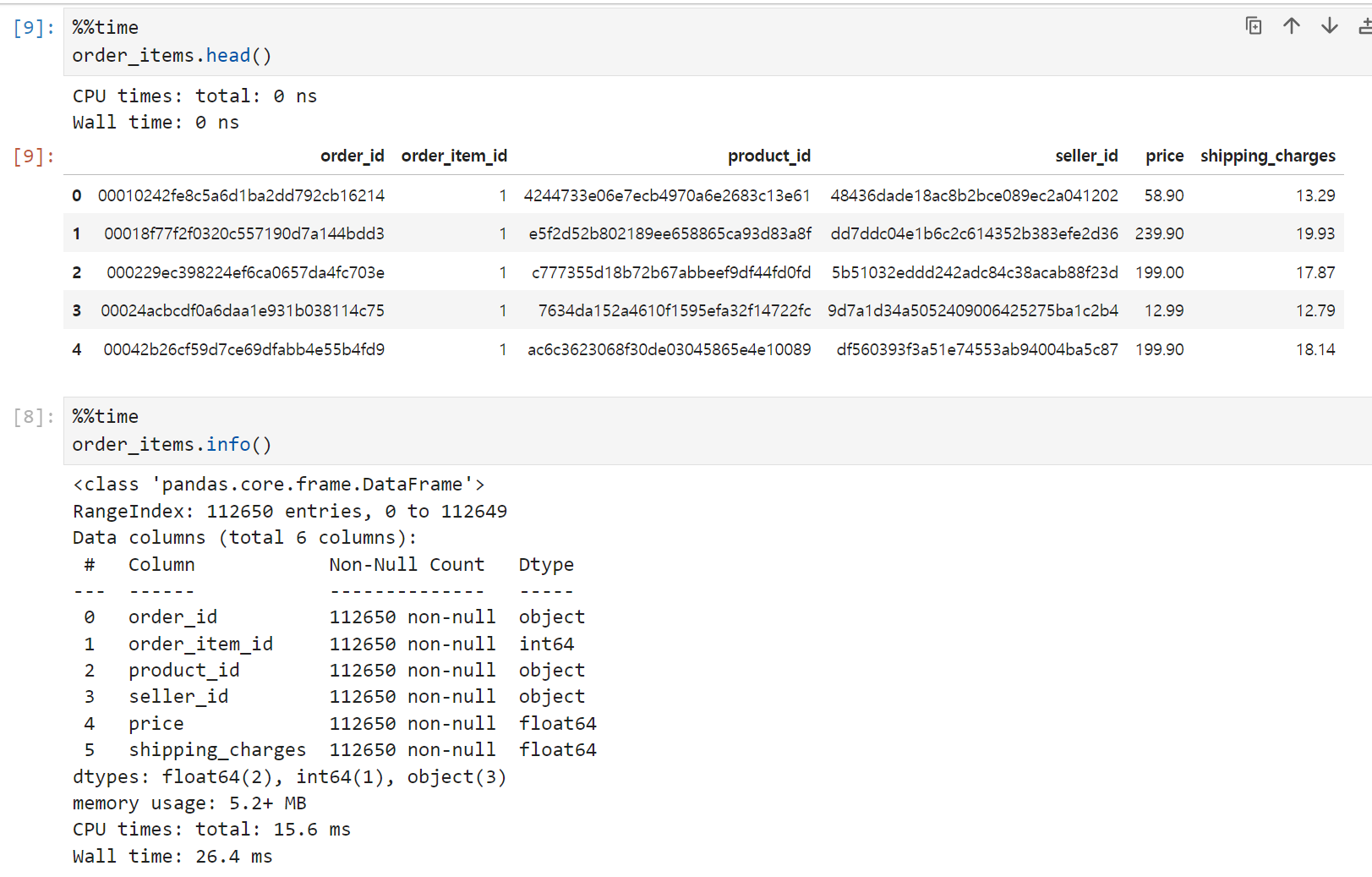
order_item_id가 정확히 무슨 컬럼인지 감이 안 잡혀서 ERD 문서를 참고했는데, order_id에 종속된 특정 품목의 고유 번호를 나타내는 컬럼이다. 이 컬럼과 order_id가 결합되어 이 테이블의 기본 키가 된다고.

예를 들어 아래 이미지처럼 동일한 order_id 하에 order_item_id가 1~4까지 있는 경우가 있다. order_item_id를 제외한 나머지 컬럼들의 값이 모두 동일하기 때문에, 섣불리 값을 합치다가 price나 shipping_charges가 뻥튀기될 수 있는 가능성이 있어 보인다.

주문(orders) 테이블은 99,441개의 row에 7개의 컬럼으로 구성되어 있다.
해당 주문의 고유id와 주문한 고객의 id, 주문 상태, 구매 시점, seller side에 주문이 접수된 시점, 고객에게 배송된 시점, 예상 도착일자 등이 기재되어 있다.
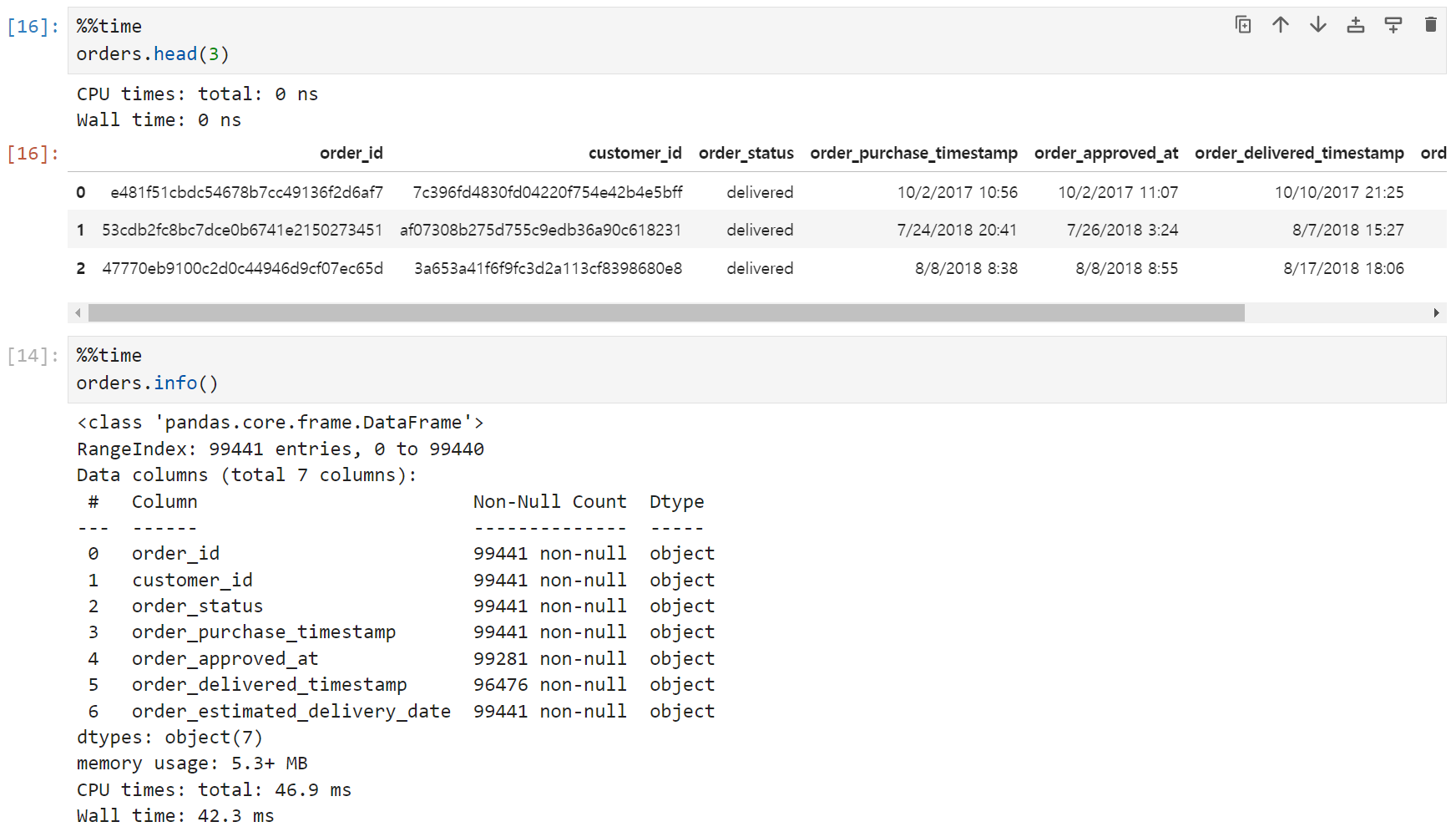
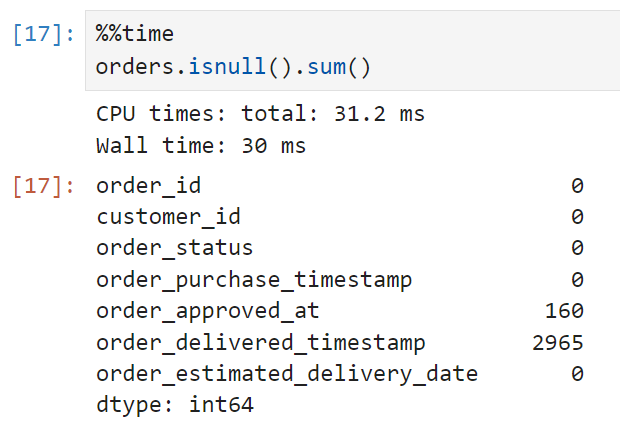
이 테이블에는 결측치가 있다. 판매자 측에 주문이 접수된 시점(order_approved_at)에 160개, 고객에게 배송된 시점(customer_delivered_timestamp)에 2,965개다. 전체 데이터가 99,441개이므로 결측치의 비율은 3% 정도. 혹시라도 이 컬럼을 쓰게 될 경우 인지하고 있어야 할 사항이다.
결제(payments) 테이블은 5개 컬럼, 103,886개의 row로 이루어져 있고 결측치는 없다.
- order 테이블과 연결할 때 key로 쓸 수 있을 order_id
- payment_sequential (이 컬럼은 설명이 모호하다는 이유로 심화프로젝트에서는 사용하지 말라는 튜터님의 가이드가 있었다.)
- payment_type(결제수단)
- payment_installments(할부개월수)
- payment_value(결제액)
컬럼은 이렇게 구성되어 있다.
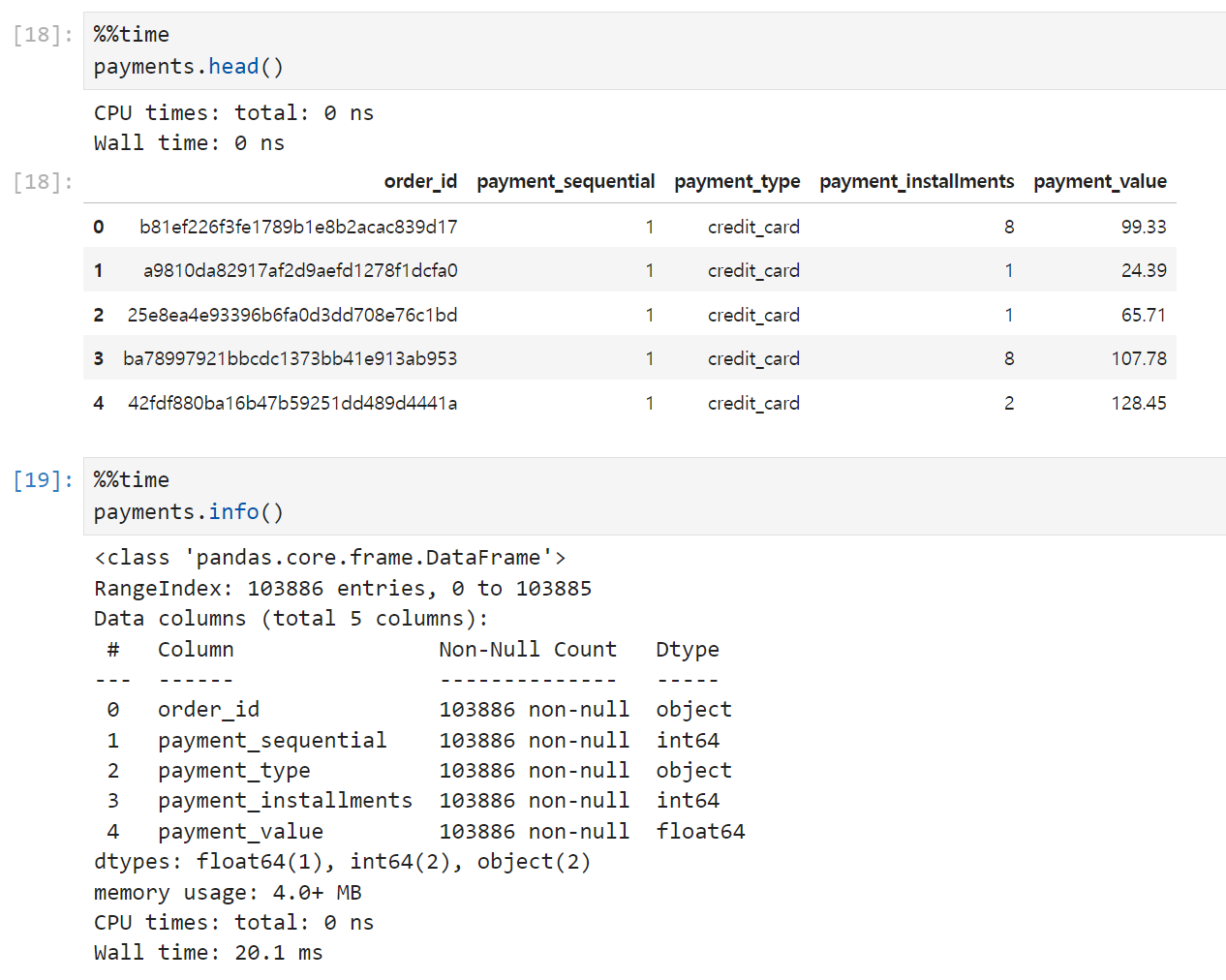
다만 해석을 잘 해야 하는 사항들이 있을 것 같은데,
주문(order) 테이블의 row 수는 99,441개인데 비해 payments의 컬럼 수는 10만개가 좀 넘는다. 얼핏 생각하면 주문 한 번에 결제 한 번이 대응되어야 할 것 같지만, payment의 컬럼 수가 더 많다는 것은
1) 결제에 실패하고 재시도한 케이스가 들어가 있거나
2) 기타 다른 이유가 있기 때문
일 거라고 생각해서 ERD 문서와 데이터를 좀 더 살펴봤다.

이 경우를 보니 payments 테이블의 row가 orders보다 많은 이유, 그리고 payment_sequential 컬럼이 무엇을 의미하는지 감을 잡게 됐다. 동일한 order_id를 여러 개의 결제수단으로 나눠서 결제하는 경우가 있을 수 있다. (신용카드 1번, 나머지는 바우처로) 이 때, 각각의 결제수단으로 결제할 때마다 payment_sequential이 자동으로 부여되고 결제금액도 나누어서 찍히는 것.
따라서, 이 테이블을 order_id 단위로 합쳐서 활용하고자 한다면
- payment_value는 합산하고
- payment_type은 고유한 값(credit_card, voucher)의 갯수를 세고
- installments는 어차피 하나의 값으로 고정이니 그걸 쓰면 되고
- payment_sequential은 order_id별 최대값을 쓰면 될 것 같다.
마지막으로 products 테이블은 32,951개의 row와 6개의 컬럼으로 구성되어 있다.
각 product의 고유 id와 카테고리명, 그리고 무게와 상품 길이 등의 제원이 기재되어 있다.
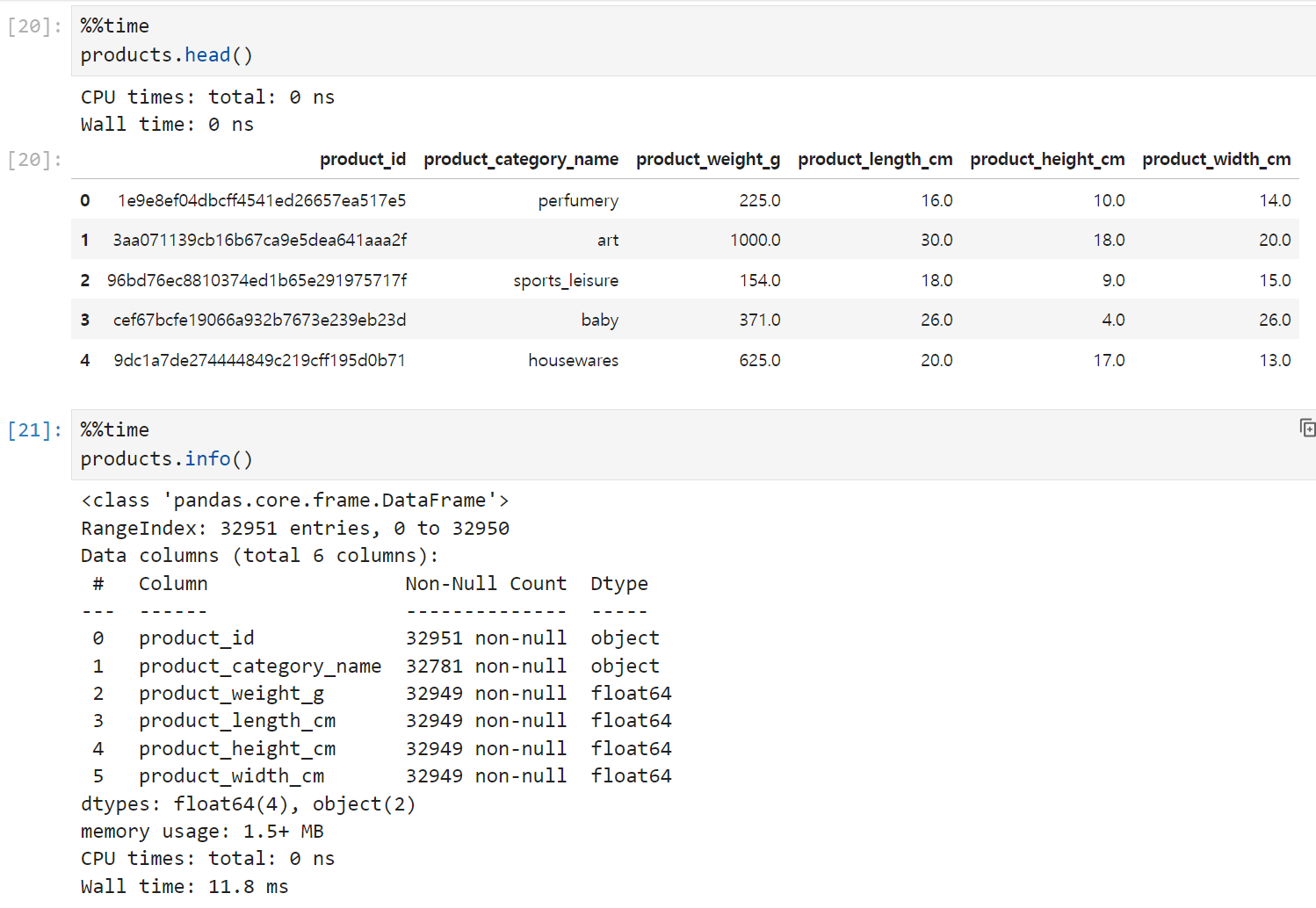
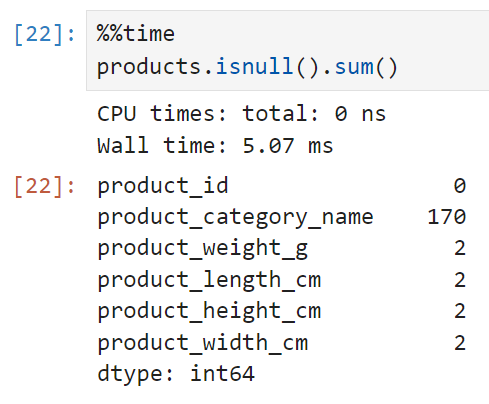
이 테이블에도 약간의 결측치가 들어가 있다. 카테고리명이 없는 경우가 170건, 스펙이 기재되지 않은 데이터가 2건씩이다. 전체 데이터에 비하면 1%보다도 작은 매우 작은 값이라 무시하고 진행해도 될 것 같긴 한데, 어쨌든 이 테이블을 쓸 때 알아두어야 할 것들이다.
데이터셋의 대략적인 현황은 이 정도로 살펴보면 될 것 같고,
클러스터링을 수행하기 위해 하나의 데이터셋으로 합치는 과정을 먼저 진행해 보기로 했다. 이상치나 결측치 처리 등의 본격적인 전처리는 그 이후에 진행하기로 하고.
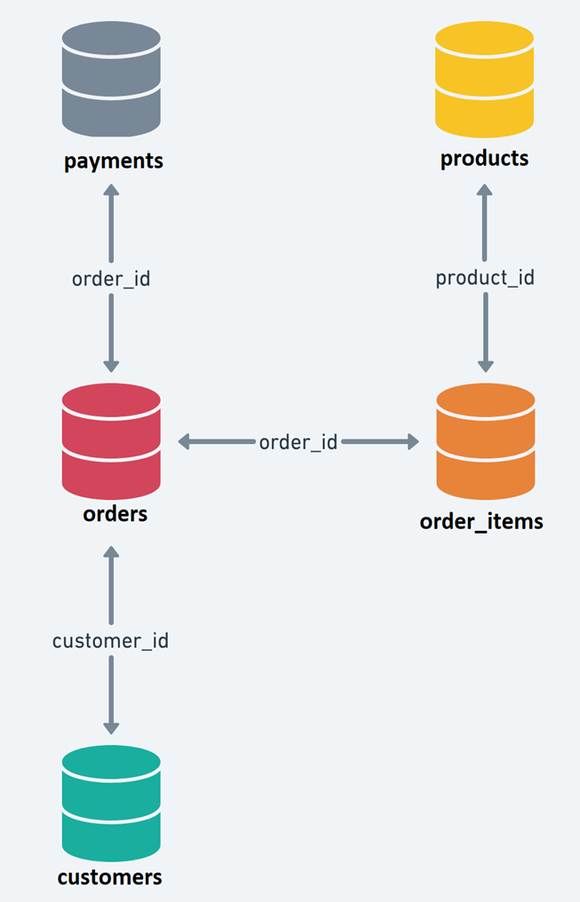
먼저 ERD를 보면서 products와 order_items부터 합쳐보기로 했다.
없는 아이템을 주문할 수는 없으므로, order_items에 들어가 있는 product_id는 반드시 products 테이블에 있을 것이라고 생각해서 order_items를 기준이 되는 테이블로 하고 inner 조건으로 합쳐봤다.
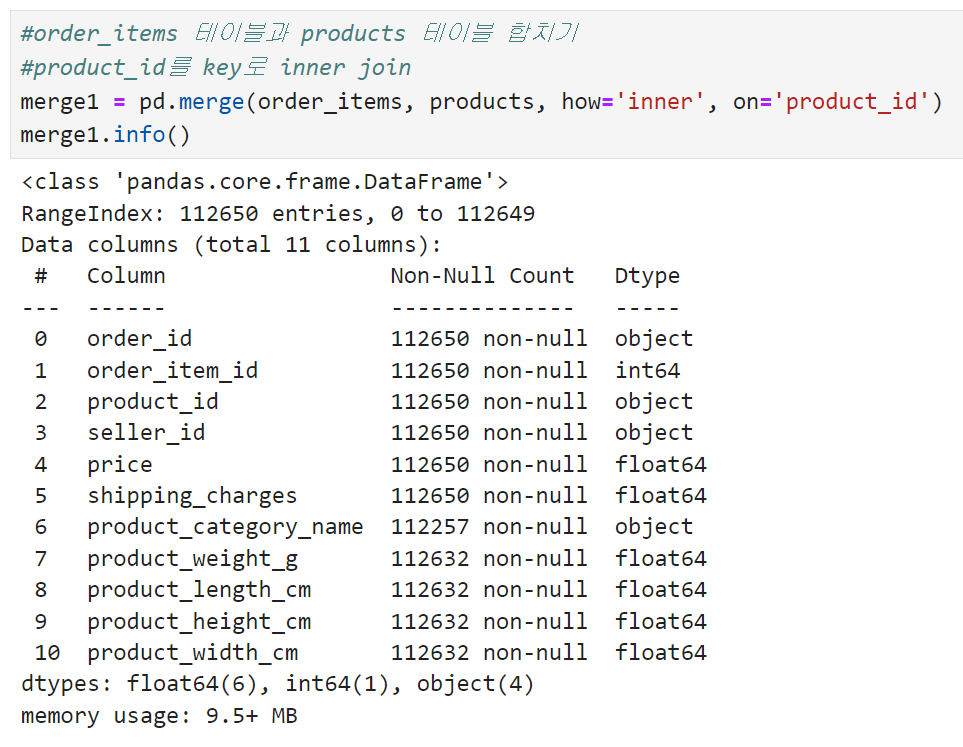
임시로 쓸 merge1 데이터프레임이 완성되었다.
order_items를 기준으로 했으므로 row 수는 똑같이 112,650이 나오고,
products 테이블에 있던 결측치의 볼륨이 조금 더 늘어난 것으로 보인다.
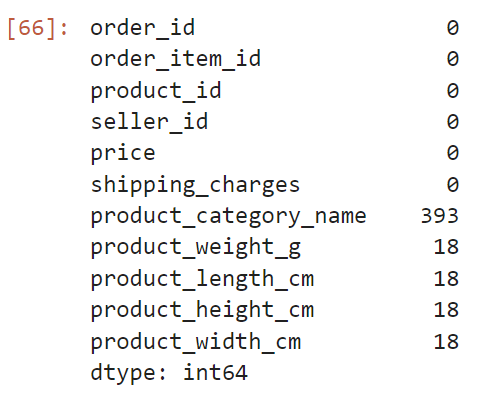
아마도 products 테이블에 있던,
결측치가 들어간 상품을 주문한 건수가 여러 건이어서 그런 것 같다.
정확히 확인해 보자.
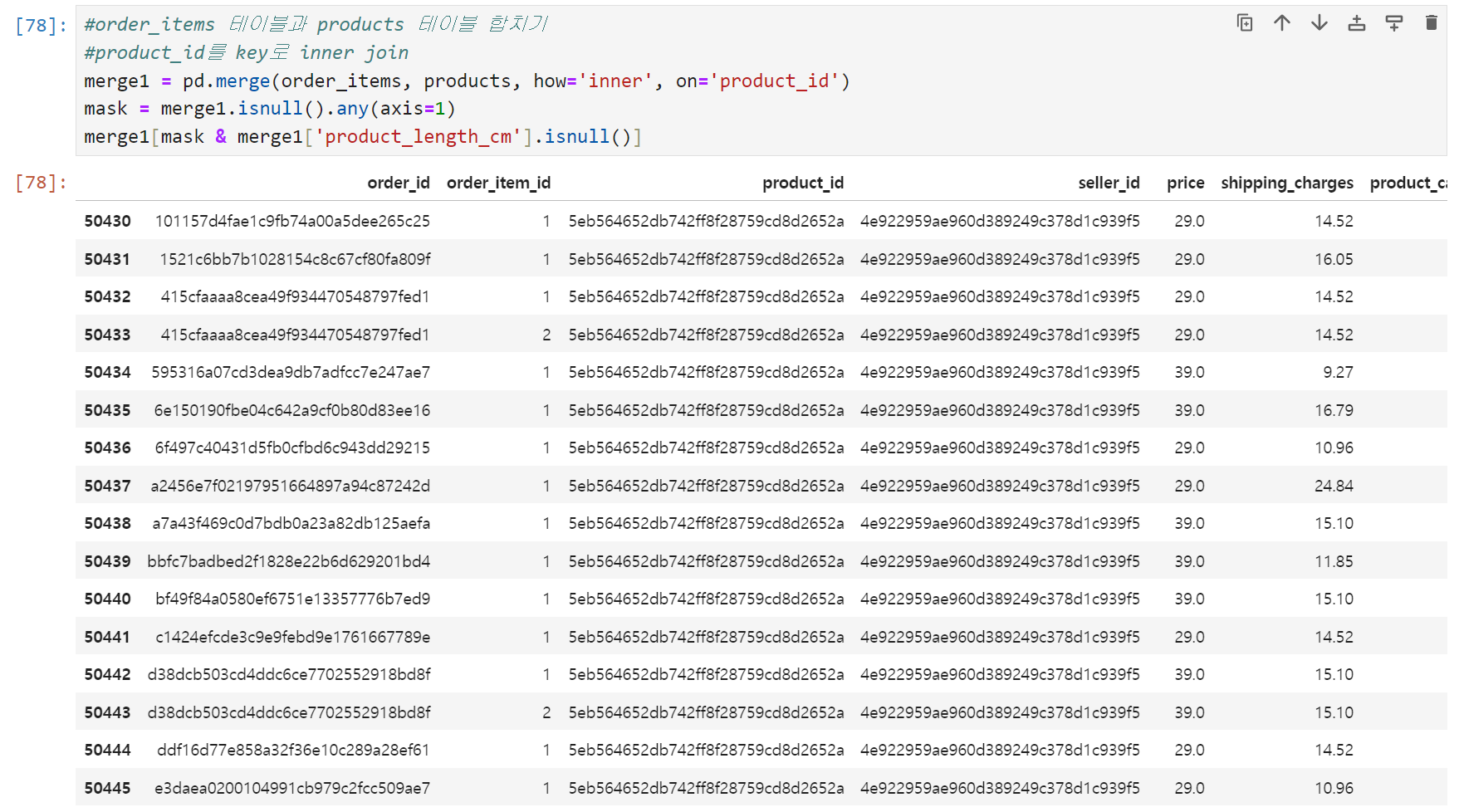
확인 결과
- seller_id 4e922959ae960d389249c378d1c939f5이 판매하는
product_id 5eb564652db742ff8f28759cd8d2652a 상품 - seller_id 09ff539a621711667c43eba6a3bd8466이 판매하는
product_id 8b8cfc8305aa441e4239358c9f6f2485 상품
이렇게 두 상품에는 상품의 제원(무게, 가로, 세로, 높이)이 빠져있다. 카테고리는 모두 toy로 동일하다. 그리고
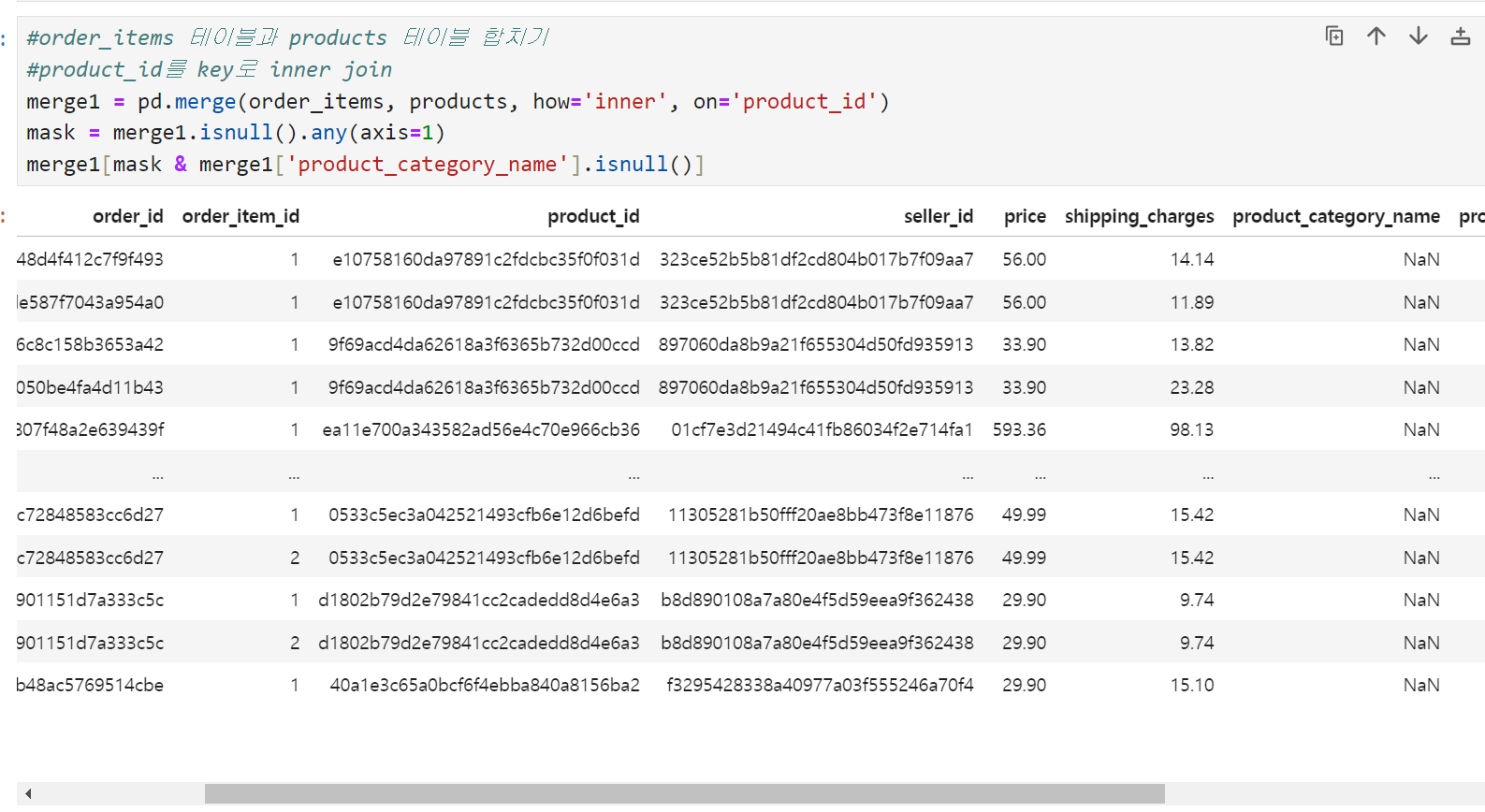
제원은 잘 들어가 있는데 product_category_name이 빠진 값들이 400개 정도 존재한다. 우선 merge1 테이블의 상황은 이 정도로 정리.
※ mask에 조건을 미리 지정해 주고 데이터프레임에 씌울 때, 위의 이미지처럼 두 개의 조건을 중첩해서 쓰는 것도 가능하다.
다음으로 orders 테이블과 payments, customers 테이블을 합쳐주고 이걸 마지막으로 merge1과 합쳐서 클러스터링을 위한 데이터셋을 만드는 과정까지 마무리해보기로 했다.
이 과정은 내일 TIL에 정리하기로.
