아무리 사소하더라도 배움이 없는 날은 없다.
SQL 코드카타
오늘은 7문제 풀이 완료.
이제 10문제 남았으니 목요일, 금요일에 각각 5문제씩 풀면 끝날 듯.
프로그래머스의 SQL문제 난이도는 전체적으로 leetcode에 비해 낮은 것 같다.
leetcode 유료결제를 해야 하나 진짜..?🤔
SELECT e1.id,
Ifnull(Count(e2.id), 0) AS CHILD_COUNT
FROM ecoli_data e1
LEFT JOIN ecoli_data e2
ON e1.id = e2.parent_id
GROUP BY 1
ORDER BY 1 WITH score
AS (SELECT emp_no,
Avg(score) AS avg_score
FROM hr_grade
GROUP BY 1)
SELECT he.emp_no,
he.emp_name,
CASE
WHEN avg_score >= 96 THEN 'S'
WHEN avg_score >= 90 THEN 'A'
WHEN avg_score >= 80 THEN 'B'
ELSE 'C'
END AS GRADE,
CASE
WHEN avg_score >= 96 THEN he.sal * .2
WHEN avg_score >= 90 THEN he.sal * .15
WHEN avg_score >= 80 THEN he.sal * .1
ELSE he.sal * 0
END AS BONUS
FROM hr_employees he
INNER JOIN score
ON he.emp_no = score.emp_no
ORDER BY 1;SELECT CASE
WHEN Month(differentiation_date) BETWEEN 1 AND 3 THEN '1Q'
WHEN Month(differentiation_date) BETWEEN 4 AND 6 THEN '2Q'
WHEN Month(differentiation_date) BETWEEN 7 AND 9 THEN '3Q'
WHEN Month(differentiation_date) BETWEEN 10 AND 12 THEN '4Q'
end AS QUARTER,
Count(id) AS ECOLI_COUNT
FROM ecoli_data
GROUP BY 1
ORDER BY 1;WITH a
AS (SELECT it1.item_id
FROM item_tree it1
LEFT JOIN item_tree it2
ON it1.item_id = it2.parent_item_id
WHERE it2.item_id IS NULL)
SELECT a.item_id,
ii.item_name,
ii.rarity
FROM a
INNER JOIN item_info ii
ON a.item_id = ii.item_id
ORDER BY 1 DESC; WITH a
AS (SELECT fish_type,
Avg(Ifnull(length, 10)) AS avg_length
FROM fish_info
GROUP BY 1
HAVING avg_length >= 33)
SELECT Count(*) FISH_COUNT,
Max(length) MAX_LENGTH,
a.fish_type
FROM fish_info fi
INNER JOIN a
ON fi.fish_type = a.fish_type
GROUP BY 3
ORDER BY 3;SELECT route,
Concat(Round(Sum(d_between_dist), 1), 'km') AS TOTAL_DISTANCE,
Concat(Round(Avg(d_between_dist), 2), 'km') AS AVERAGE_DISTANCE
FROM subway_distance
GROUP BY 1
ORDER BY 1 DESC WITH a
AS (SELECT fish_type,
Max(length) AS length
FROM fish_info
GROUP BY 1),
b
AS (SELECT a.fish_type,
a.length,
fni.fish_name
FROM a
INNER JOIN fish_name_info fni
ON a.fish_type = fni.fish_type),
c
AS (SELECT fi.id,
b.fish_name,
b.length
FROM b
INNER JOIN fish_info fi
ON b.fish_type = fi.fish_type
AND b.length = fi.length)
SELECT *
FROM c
ORDER BY 1 클러스터링 프로젝트
🌺 데이터셋은 총 5개의 CSV 파일로 구성되어 있습니다.
- Retail_dataset.csv 파일에 ERD(테이블 구조도) 및 컬럼 설명이 기재되어 있습니다.
🌺 각 테이블을 결합하여, 클러스터링을 위한 하나의 데이터셋으로 만들어주세요.
- 모든 테이블을 결합하지 않아도 좋습니다.
- 다만, 테이블 결합 시 알맞은 결합 방식을 사용해주세요.
🌺 필수 사항
- 이상치 처리 기법을 활용하거나, 특정 기준을 세워 이상치를 정의 하고 그 이유를 설명해주세요.
- 클러스터링시, 초기 군집의 갯수와 사용할 컬럼의 갯수는 python 머신러닝 라이브러리를 활용하여 진행해주세요.
- 컬럼별 raw data 분포를 그려주세요.
- 컬럼 간 상관계수를 히트맵 차트로 구현해주세요.(유의미한 기준은 +0.6(양의 상관관계) 또는 -0.6(음의 상관관계)으로 판단해주시면 됩니다)
🌺 선택 사항
- 필요하다면 파생변수를 생성해도 좋습니다.
- 데이터 표준화가 필요한 경우 진행해주세요. 표준화 방법을 여러가지 사용해보시고, 비교해주셔도 됩니다.
- 범주형 데이터를 사용할 경우, 인코딩을 진행해주세요. 원-핫 인코딩/라벨인코딩 모두 사용해도 됩니다. 다만, 범주의 갯수가 많은 경우, 별도 세그멘테이션이 필요할 수 있겠습니다. 의미있는 기준을 세워주시고 그 값을 인코딩 진행해주세요. (예시: 국가가 100개인 경우 육대륙으로 나누어 인코딩). 참고자료: https://nicola-ml.tistory.com/62#google_vignette
- 분석 결과를 한 눈에 파악할 수 있도록 datapane 으로 리포트를 구현해주세요.
2. EDA
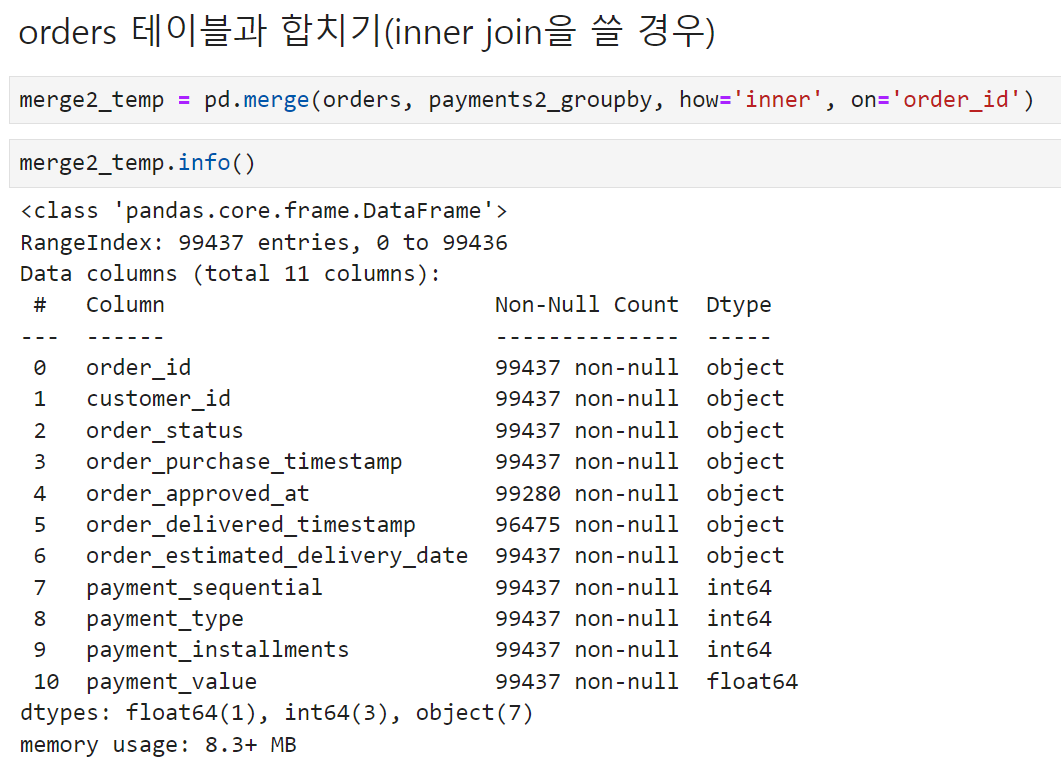
오늘은 orders 테이블과 payments 테이블을 합쳐주는 단계까지 진행했다.
먼저 orders와 payments를 합치기 전에 payments 테이블의 구조를 살펴보면
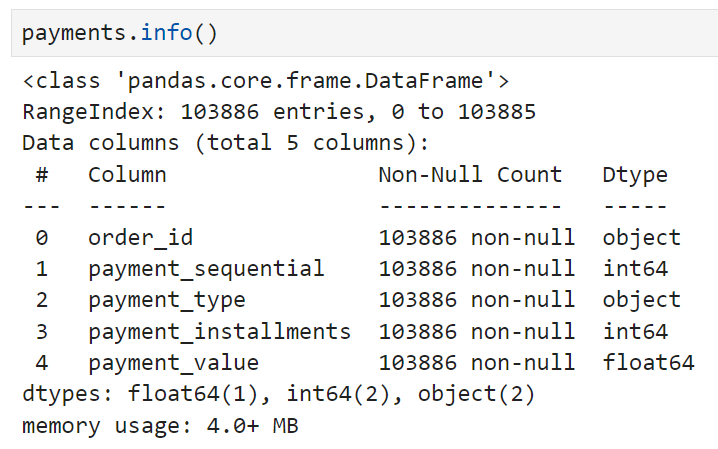
이렇게 되어 있는데,
하나의 order_id 밑에 여러 개의 다른 컬럼이 붙어있는 경우가 있었다.
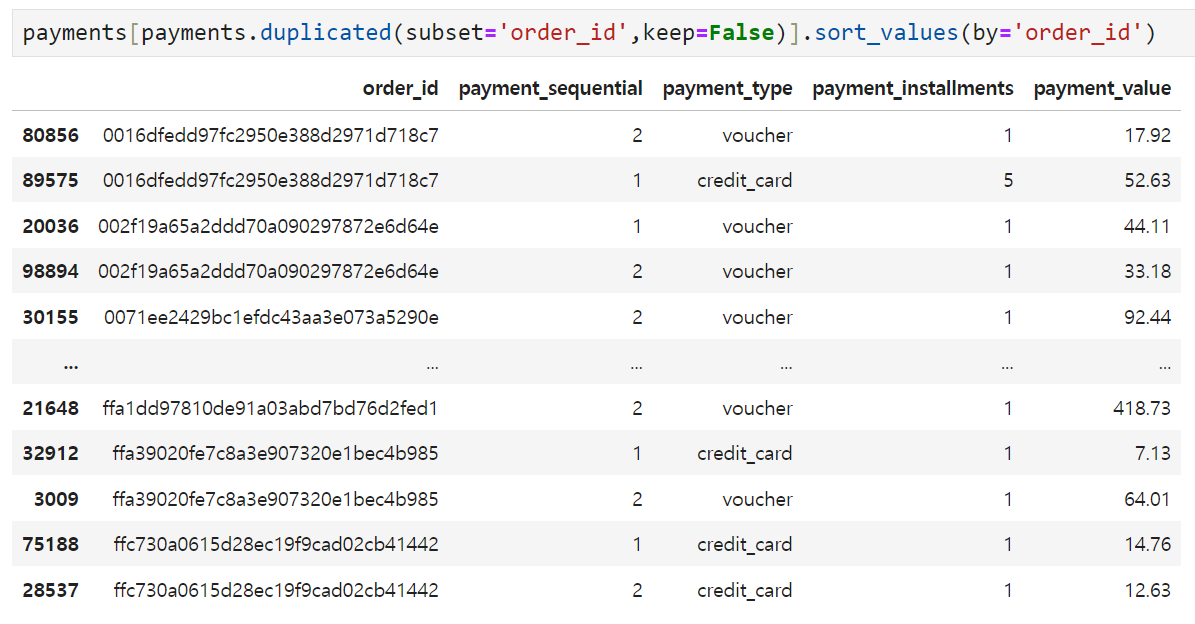
따라서, 이런 중복 행들을 사전에 처리하지 않고 orders 테이블과 payment 테이블을 합칠 경우 (조건을 inner로 한다면) 여러 개의 값들 중 하나만 orders 테이블에 가서 붙거나, (조건을 left로 한다면) 붙여놓은 결과 테이블에서 중복 행이 발생하는 문제가 생길 것 같다. 따라서 orders 테이블과 합치기 전에 어떤 컬럼을 어떻게 사용할지부터 결정하기로 했다.
-
payment_sequential은 하나의 주문을 몇 번에 걸쳐서 결제하는지를 나타내는 컬럼인데, 하나의 주문에 여러 개의 sequential이 발생한다고 해도 최종적으로 orders 테이블에 꽂히는 주문은 1건이다. 따라서 군집 분류에 효과적으로 쓰일지는 모르지만, 각 order_id별로 최대값 하나만 살리기로 했다. (아래 이미지의 예에서는 19)
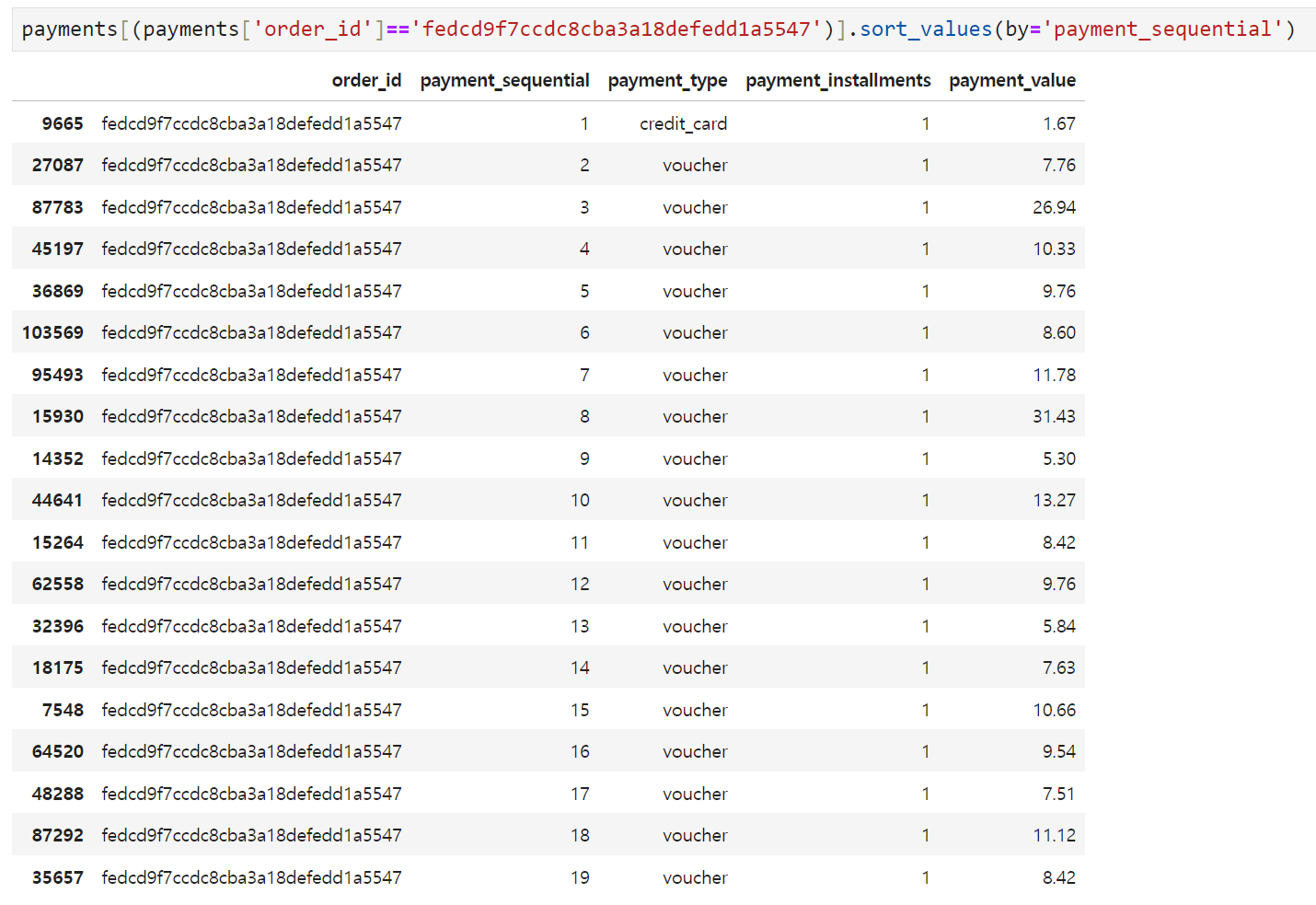

-
payment_type는 결제수단을 나타내는 컬럼인데, 총 5개의 고유한 값이 있다. 이 중 credit_card와 voucher는 봤는데 wallet, debit_card, not_defined의 정체를 좀 더 알아보기로 했다.

우선 가장 간단한 not_defined를 보면, 이건 그냥 주문 취소 건이다. not_defined 값을 가진 order_id는 3개밖에 없고, 이걸 orders 테이블에서 조회해 보면 주문 상태에 canceled라고 뜬다. 따라서 이건 그냥 없애도 될 것 같다.
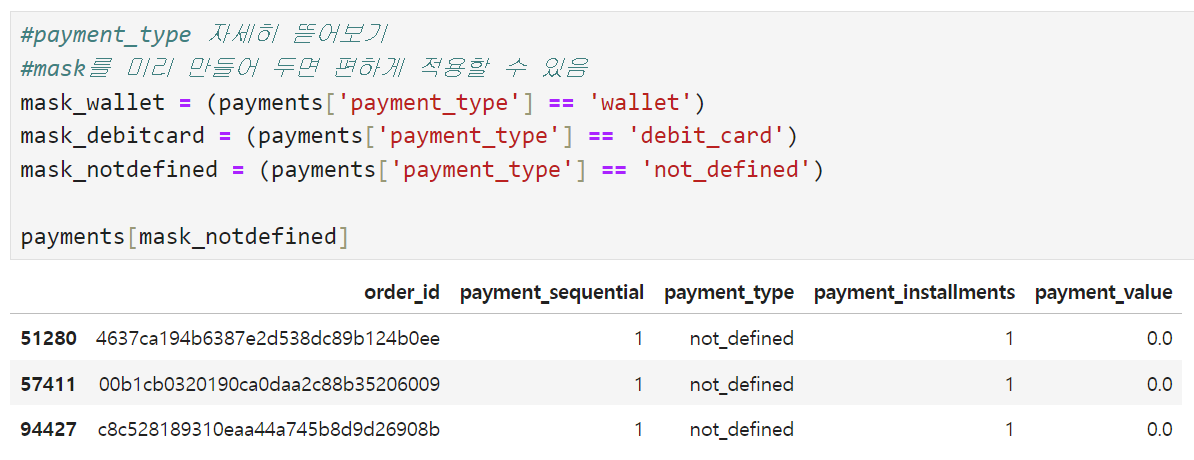
wallet과 debit_card는 각각 전자지갑(애플페이나 페이팔 등)과 직불카드(우리가 흔히 얘기하는 체크카드)를 의미하는데, 전체적인 결제수단별 분포를 살펴보면 credit_card가 75% 정도 되고, 나머지 결제수단을 합친 것들이 25% 정도 되는 것 같다.
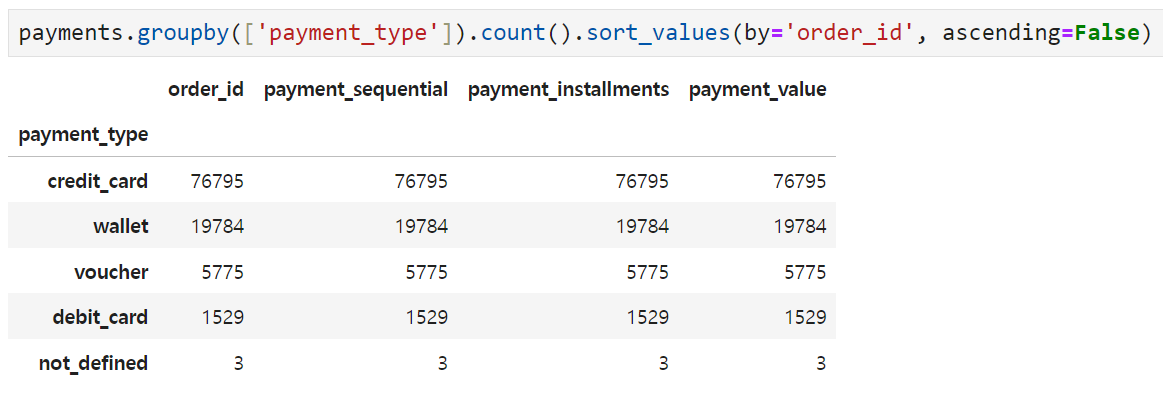
payment_type에서는 not_defined 값인 것들은 삭제하고 나머지들은 order_id별로 사용한 결제수단의 갯수를 세어주기로 했다. 일단 그루핑해 보고 분포가 어떻게 나오는지를 봐야 감이 올 듯. -
payment_installments는 신용카드(credit_card)의 할부 수를 나타낸 컬럼인데, credit card 외에 wallet이나 voucher등은 무조건 1로 들어가 있다. credit_card도 1로 들어가 있는 경우가 있는데 이건 일시불인 것 같다. 따라서 order_id 별로 이 컬럼을 묶어야 한다면 최대값을 쓰는 것이 가장 자연스러울 것 같다. 만약 최대값을 썼을 경우

- 1로 나온다 → credit_card든 다른 결제수단을 섞어서 쓰든 하여튼 일시불
- 1이 아닌 다른 값(2 이상)이 나온다 → credit card의 할부 수 (다른 결제수단은 2 이상일 수 없으므로)
어제는 payment_installments의 값이 고정되어 있는 하나의 값이라고 생각했는데 데이터를 자세히 보면서 그렇지만은 않을 수도 있다는 걸 알게 됨.
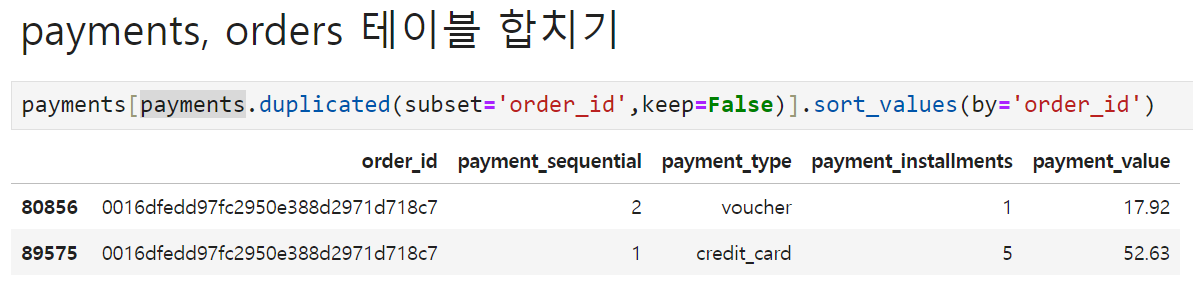
-
마지막으로 payment_value는 결제액이므로 order_id별로 합산(sum)해서 쓰면 될 것 같다.
정리하자면, payment 테이블에서는
- payment_type에서 not_defined 값 제거
- order_id별로 그루핑하되
- payment_sequential 컬럼은 최대값 사용
- payment_type 컬럼은 고유값의 수 사용
- payment_installment 컬럼은 최대값 사용
- payment_value 컬럼은 합계 사용
이 될 것 같다. 이 조건대로 데이터를 변환해 보면
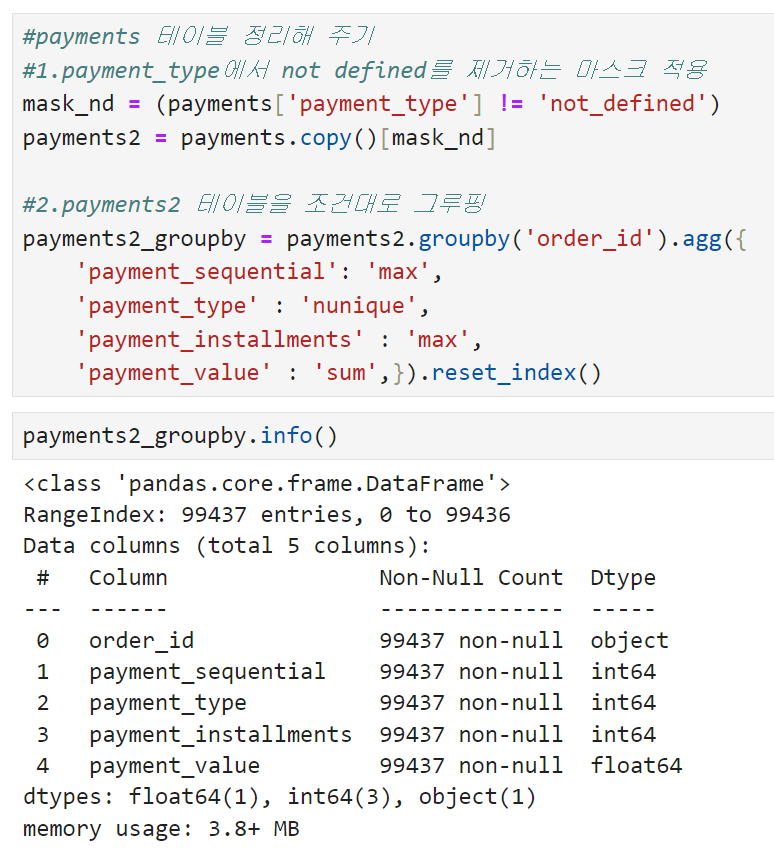
원래 10만 행이 조금 넘던 payments 테이블이 99,437 행으로 줄어든 것을 확인할 수 있다. 그루핑이 원하는 대로 잘 수행됐는지를 체크하기 위해 중복되는 order_id가 있는지 여부를 확인해 봤다.

중복된 order_id 없이 잘 그루핑된 것 같다.
이제 이 결과(payment2_groupby)를 order_id와 하나로 합쳐보기로 했다.
기준이 되는 테이블은 orders이고 조건은 order_id를 기준으로 left로 수행하기로 했다. inner가 아니라 left로 수행하는 이유는 혹시나 join 조건이 안 맞아서 행 수가 줄어들었을 때 어떤 컬럼에서 문제가 생긴 건지 체크가 어렵기 때문.
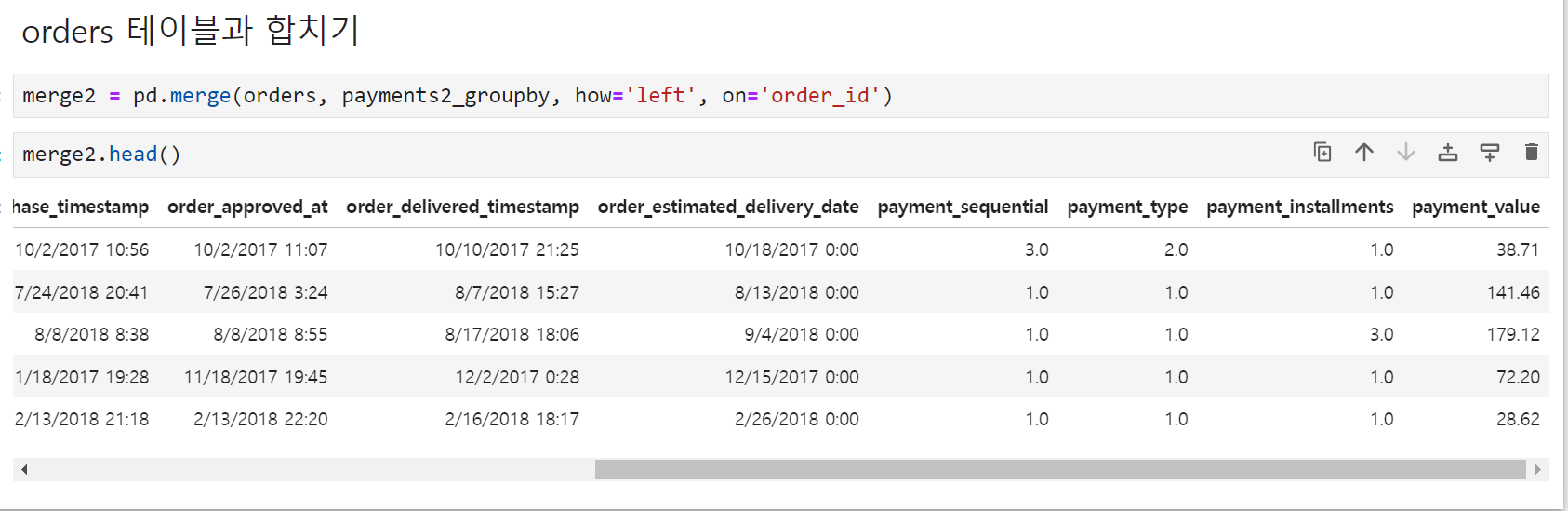
합쳐진 결과 orders 테이블의 오른쪽에 payment_sequential부터 payment_value까지 4개의 컬럼이 추가되었다. 조건이 left였으므로 혹시 orders에 있는 order_id 중 조인이 수행되지 않은 컬럼이 있는지 체크해 보기로 했다.
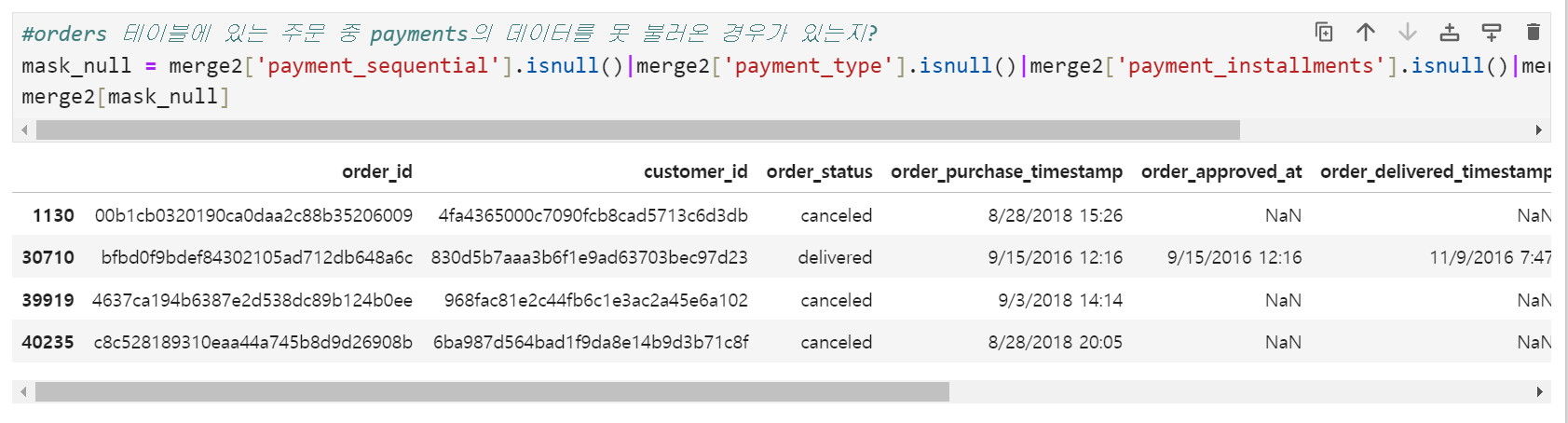
새로 추가된 컬럼들 중 어느 하나라도 null인 경우를 마스크로 만들어 merge2에 적용했더니 4개의 order_id가 발견되었다. order_status가 canceled, 즉 취소된 주문인 경우가 3건 있고 delilvered라고 되어있는데 결제정보가 담기지 않은 주문 1건이다. 건수가 많지 않기도 하고 단순 오류일 가능성이 있어 이 행은 버리기로 했다.
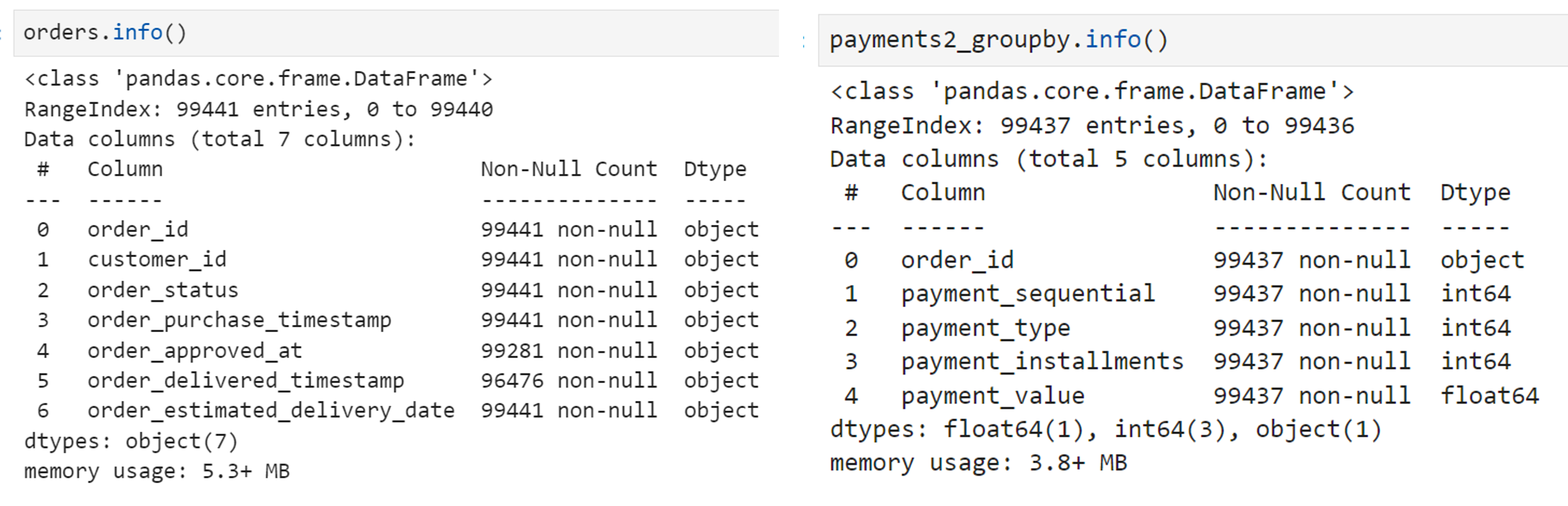
확인 결과 기준이 되는 orders 테이블과 payments 테이블의 row 수의 차이가 딱 4개였는데, merge2를 만들 때 payment 정보를 못 불러온(즉, null인 경우) 경우의 수와 일치했다. 저 행들을 정리하면 merge2까지의 생성은 무사히 완료될 것 같다.
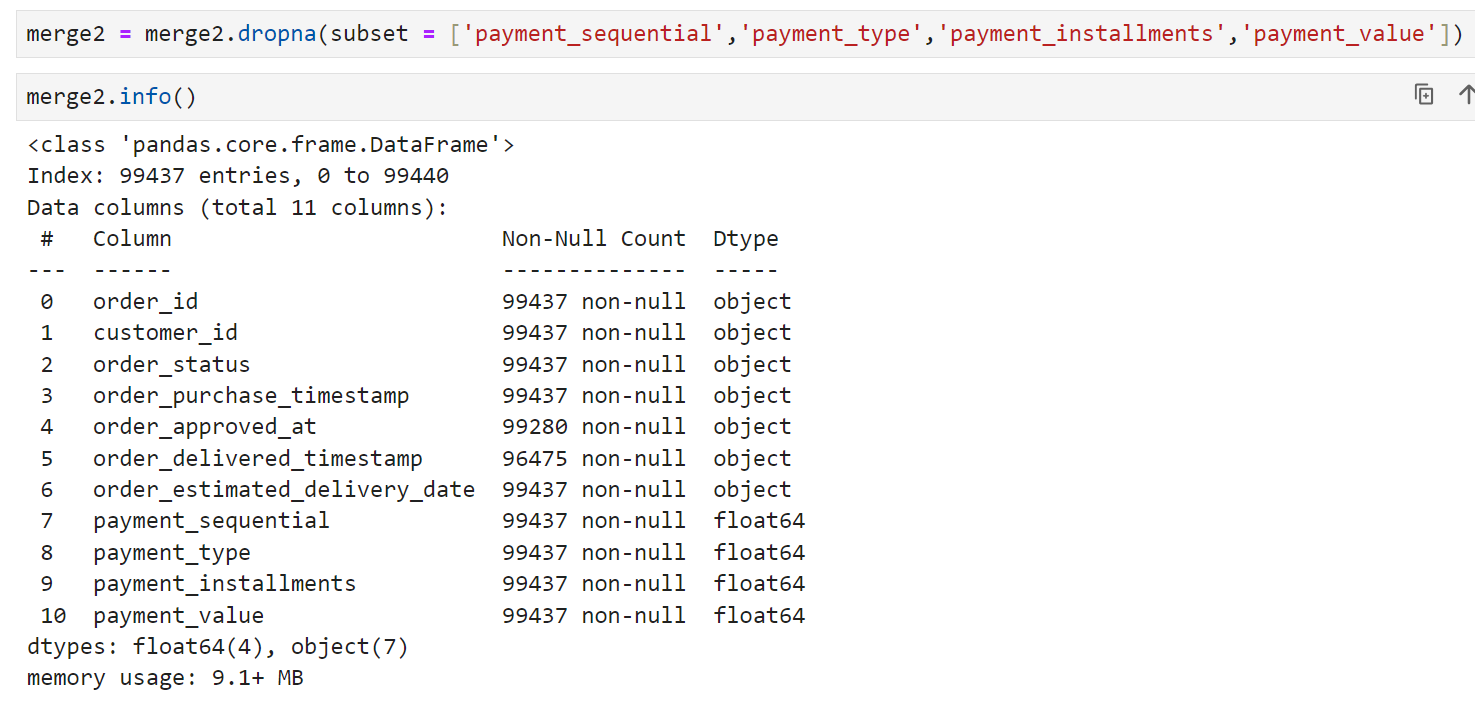
merge2에서 payment 정보를 못 불러온 행들을 제외시킨 결과, 99,437건으로 row가 정리되었다. inner join을 썼으면 처음부터 이런 결과를 얻을 수 있었겠지만, 몇 개의 row가 무슨 이유로 제외되는지를 정확하게 확인하고 넘어가야 해서 일부러 join의 방식은 left로 선택했다.
이제 테이블 merge 과정에서 2개를 완료했고,
merge2와 customers 테이블을 병합해서 merge3를 만든 후
맨 처음 만들었던 merge1과 최종적으로 병합하면 데이터셋이 완성될 것 같다.
이후 진행과정은 내일 TIL에서 다뤄보기로.
※ orders와 payments2_groupby를 inner 조건으로 한 방에 합친 결과