변이 추정
데이터의 특징을 요약하는 다양한 요소들 중 위치 외에 변이Variability가 있다. 변이는 데이터 값이 얼마나 밀집해 있는지, 혹은 퍼져 있는지를 나타내는 산포도Dispersion를 나타낸다.
위치를 추정하는 데 다양한 방법이 있었던 것처럼 (평균, 중앙값 등) 변이를 추정하는 데에도 다양한 방법이 있다.
편차
-
가장 대표적인 변이 추정 방법은 관측 데이터와 위치 추정값(e.g. 산술평균) 사이의 차이, 즉 편차를 이용하는 것이다.
-
변이를 측정하는 한 가지 방법은 이 편차들의 대푯값을 추정하는 것인데, 그렇다고 편차들을 단순 산술평균 내면 값이 0이 되어서 쓸 수 없게 된다.
-
따라서 편차를 활용하는 방법은 크게 2개로 나뉜다.
- (편차들을 단순 합하면 0이 되므로) 편차들의 절대값을 취해서 산술평균 낸 평균절대편차를 쓰거나
- 가장 유명한 변이 추정 방법인 분산과 표준편차를 쓰는 것
-
표준편차는 원래 데이터와 같은 스케일scale에 있기 때문에 분산보다 해석하기 훨씬 쉽다는 이점이 있다.
-
다만 분산, 표준편차, 평균절대편차 모두 특잇값과 극단값에 로버스트하지 않다는 약점이 있다. 특히 분산과 표준편차는 제곱편차를 쓰기 때문에 특잇값에 더욱 민감하다.
-
로버스트한 변이 추정값으로 중간값의 중위절대편차(MAD, Median Absolute Deviation)가 있다. 중위절대편차를 구하는 순서는 아래와 같다.
- 어떤 데이터 세트의 중앙값을 구한다.
- 각 데이터 값에서 중앙값을 뺀 후 절대값을 취한다. (이 값을 절대편차라고 부른다)
- 2에서 구한 절대편차들의 중앙값을 구한다.
백분위수
-
변이를 추정하는 또다른 방법은 정렬된 데이터가 얼마나 퍼져있는지를 보는 것인데, 가장 기본이 되는 측도는 가장 큰 값과 가장 작은 값의 차이를 나타내는 범위range다. 그러나 범위는 특잇값에 매우 민감하며 데이터의 변이를 측정하는 데 그렇게까지 유용하지 않다.
-
특잇값에 민감한 것을 피하기 위해 예컨대 범위의 양 끝에서 값들을 지운 후 범위를 다시 알아볼 수 있다. (마치 절사평균처럼) 좀 더 구체적으로 백분위수 사이의 차이를 가지고도 이런 추정을 해 볼 수 있다.
-
어떤 데이터에서 P번째 백분위수는 P퍼센트의 값이 그 값 혹은 그보다 작은 값을 갖고, (100-P)퍼센트의 값이 그 값 혹은 그보다 큰 값을 갖는 어떤 값을 의미한다. 쉽게 말해 25분위수라고 하면 하위25%의 값이 25분위수 밑에 깔리는 것이고, 75분위수는 그 밑으로 75%의 데이터가 깔리는 것이라고 이해하면 된다.
-
변이를 측정하는 가장 대표적인 방법은 사분위범위(IQR)라고 불리는, 25번째 백분위수와 75번째 백분위수의 차이를 보는 것이다. 박스플롯을 그렸을 때 박스의 아래쪽 경계가 Q1(25백분위수), 위쪽 경계가 Q3(75백분위수)다.
- 참고로 박스플롯에서 수염은 Q1-(1.5×IQR)과 Q3+(1.5×IQR)까지 그려진다.
- 이 수염들 바깥으로 나가는 값들이 일반적으로 이상치로 간주된다.
-
데이터 집합이 매우 클 경우 정확한 백분위수를 계산하기 위해 모든 값들을 오름차순으로 정렬하는 것은 많은 양의 연산을 필요로 한다. 이런 이유 때문에 다양한 머신러닝과 통계 소프트웨어들에서는 백분위수의 근삿값을 사용하는데, 이 근사 방법은 계산이 매우 빠르고 어느 정도 정확도가 보장되어 있어서 그냥 사용해도 무방하다.
- 참고로 numpy의 quantile은 선형보간법이라는 방법을 지원한다. 선형보간법이 뭔지는 나중에 따로 정리해 보기로.
코드 실습
-
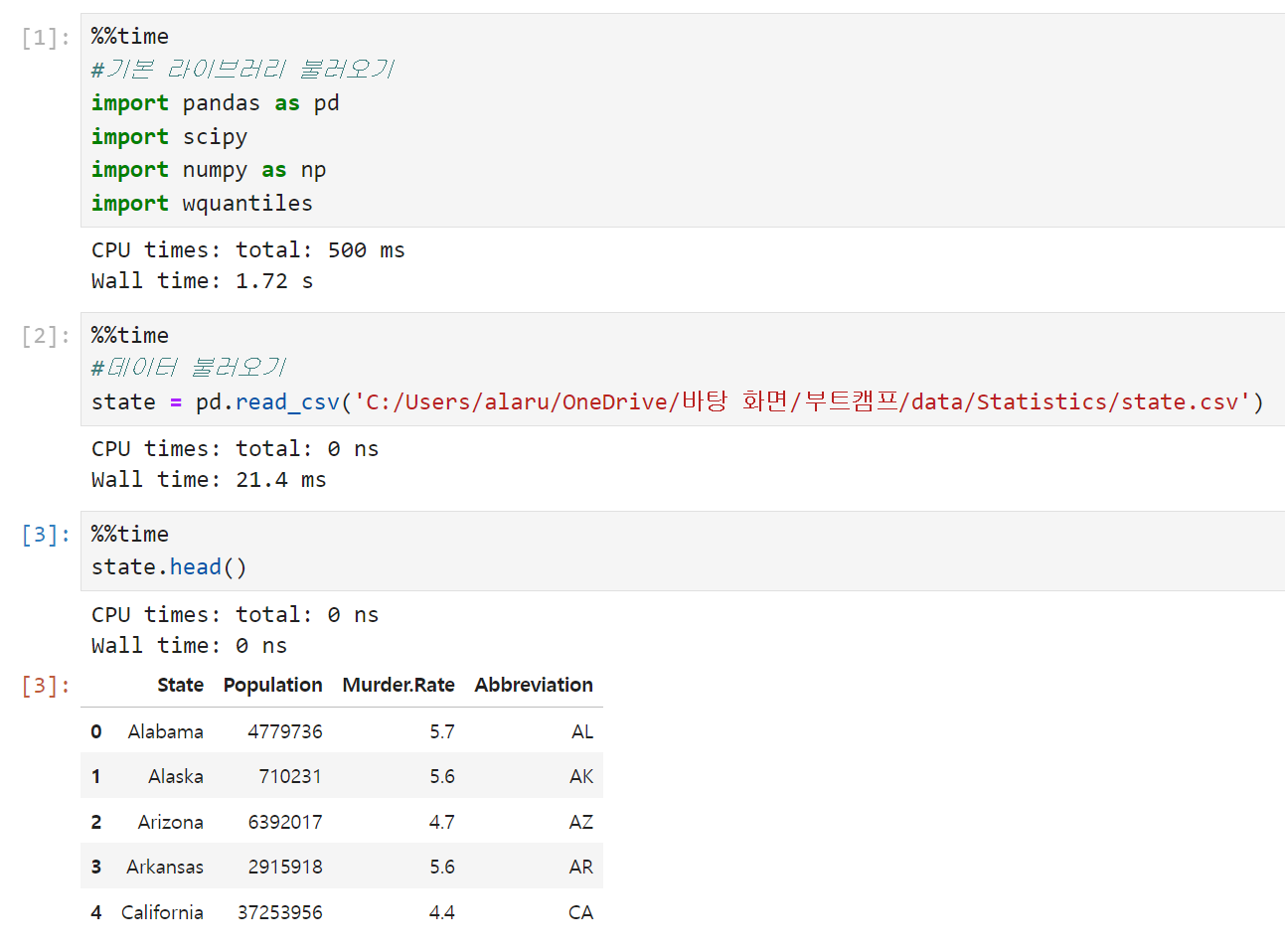
위치 추정 실습 때 썼던 라이브러리와 데이터를 불러온다. 미국 각 주의 인구와 살인 비율을 보여주는 state 데이터다.
-
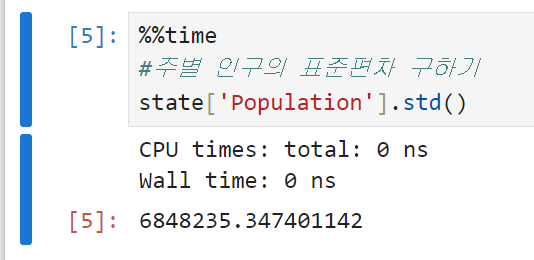
주별 인구의 표준편차를 구해 본다. 편차 4번 항목에 정리한 대로 표준편차는 원래 데이터와 같은 scale에 있어 해석이 편하다.
-
주별 인구의 IQR을 구해 본다.

-
주별 인구의 MAD, 즉 중위절대편차를 구해 본다. robust.scale.mad 함수를 쓰기 위해서는 Statsmodel이라는 라이브러리를 설치하고 불러와야 한다. 앞으로는 sm으로 통일해서 사용할 예정.
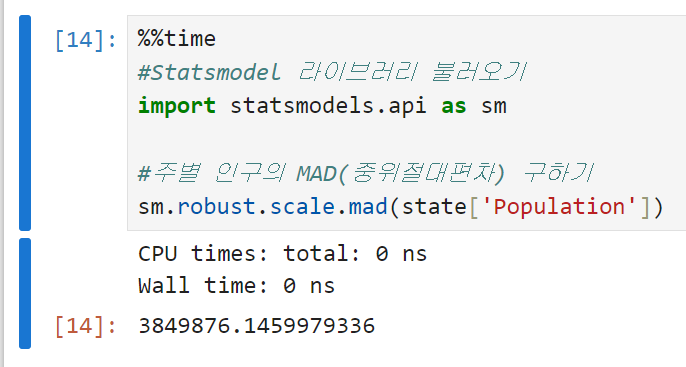
표준편차(6,848,235)가 MAD(3,849,876)의 거의 두 배에 가까울 정도로 크다.
표준편차는 산출과정에서 제곱편차를 쓰는 관계로
특잇값에 취약하기 때문에 딱히 놀라운 결과는 아니다.
세 줄 요약
- 분산과 표준편차는 가장 보편적으로 널리 사용되는 변이 측정 방법이다
- 이 두 수치 모두 특잇값에 민감하다. (즉, 로버스트하지 않다)
- 중간값과 백분위수(분위수)로부터 평균절대편차나 중간값의 중위절대편차(MAD)를 구하는 것이 좀 더 로버스트하다.
