아무리 사소하더라도 배움이 없는 날은 없다.
SQL 코드카타
SELECT q.id,
q.year,
Ifnull(n.npv, 0) AS "npv"
FROM queries q
LEFT JOIN npv n
ON q.id = n.id
AND q.year = n.year;문제 링크
제한시간 안에 풀지 못했던 난이도 hard 문제.
재귀CTE를 써서 아래 결과까지 만드는 데는 성공했는데,
정작 판매량을 월별로 어떻게 쪼개야 할지 감이 안 잡혔다.
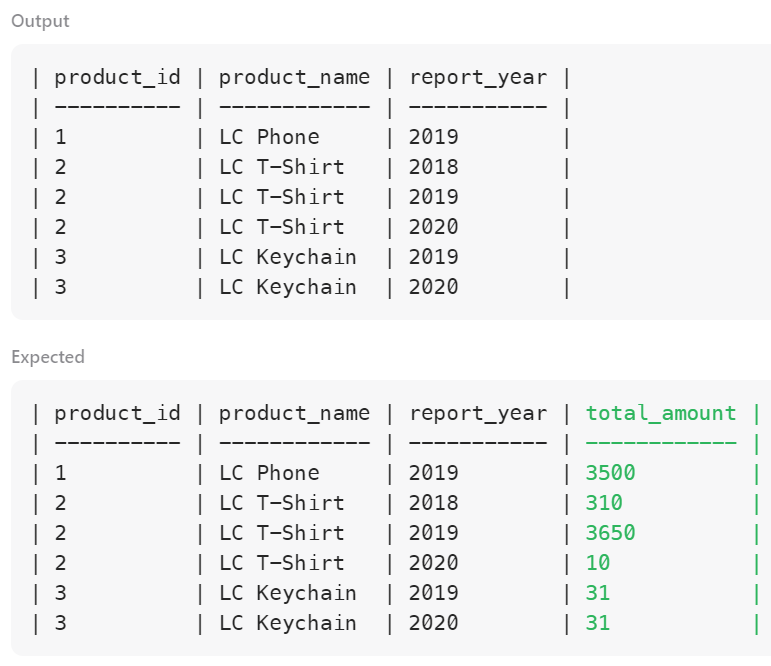
아래는 실패 시점까지의 작성 쿼리.
WITH recursive year_period
AS
(
SELECT product_id,
year(period_start) AS "report_year",
year(period_end) AS "end_year"
FROM sales
UNION ALL
SELECT product_id,
report_year+1,
end_year
FROM year_period
WHERE report_year < end_year)
SELECT *
FROM year_period y
LEFT JOIN product p
ON y.product_id = p.product_id
ORDER BY 1년도만을 기준으로 쪼개놓으면 나중에 연산하기가 힘들어질 것 같아서,
아예 재귀CTE를 만들 때 처음부터 날짜를 기준으로 만들어 봤다.
WITH recursive all_date
AS
(
SELECT min(period_start) AS "report_date"
FROM sales
UNION ALL
SELECT report_date + INTERVAL 1 day
FROM all_date
WHERE report_date <
(
SELECT max(period_end)
FROM sales))
SELECT *
FROM all_date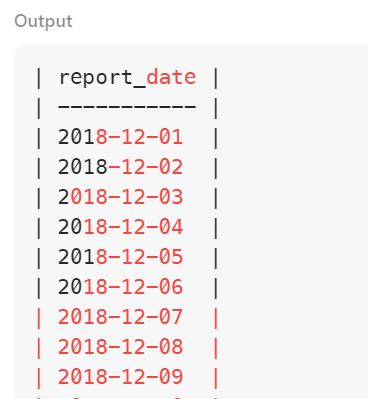
아예 나올 수 있는 모든 날짜를 다 CTE에 넣어버린 결과.
그 뒤에 Sales 테이블을 join하고, report_date 범위 안에 period_start와 period_end가 모두 들어올 수 있게 조건을 넣어주었다.
WITH recursive all_date
AS
(
SELECT min(period_start) AS "report_date"
FROM sales
UNION ALL
SELECT report_date + INTERVAL 1 day
FROM all_date
WHERE report_date <
(
SELECT max(period_end)
FROM sales))
SELECT *
FROM all_date a
JOIN sales s
ON s.period_start <= a.report_date
AND s.period_end >= a.report_date여기에 상품명을 넣기 위해 Product 테이블을 한 번 더 join하고
문제의 조건에 맞게 본 쿼리를 만들어주면 답은 나온다.
WITH recursive all_date
AS
(
SELECT min(period_start) AS "report_date"
FROM sales
UNION ALL
SELECT report_date + INTERVAL 1 day
FROM all_date
WHERE report_date <
(
SELECT max(period_end)
FROM sales))
SELECT s.product_id,
p.product_name,
date_format(a.report_date,'%Y') AS "report_year",
count(a.report_date) * s.average_daily_sales AS "total_amount"
FROM all_date a
JOIN sales s
ON s.period_start <= a.report_date
AND s.period_end >= a.report_date
JOIN product p
ON p.product_id = s.product_id
GROUP BY 1,
2,
3
ORDER BY 1,
3;일단 답은 나왔는데,
만약 재귀CTE에서 구했던 min(period_start)와 max(period_end)의 간격이 엄청나게 컸다면 CTE에서 나오는 행이 너무 많아서 (거기에 join까지 해야 하니) 연산상 굉장히 비효율적인 쿼리가 될 것 같다는 느낌이 든다...
이 문제는 나중에 다시 한 번 풀어보기로.
WITH result
AS (SELECT session_id,
CASE
WHEN duration < 300 THEN '[0-5>'
WHEN duration < 600 THEN '[5-10>'
WHEN duration < 900 THEN '[10-15>'
ELSE '15 or more'
END AS bin
FROM sessions),
t
AS (SELECT '[0-5>' AS Bin
FROM sessions
UNION
SELECT '[5-10>' AS Bin
FROM sessions
UNION
SELECT '[10-15>' AS Bin
FROM sessions
UNION
SELECT '15 or more' AS Bin
FROM sessions)
SELECT t.bin,
Ifnull(Count(session_id), 0) AS Total
FROM result r
RIGHT JOIN t
ON r.bin = t.bin
GROUP BY t.bin;문제 링크
연속으로 5일, 혹은 그 이상 로그인한 활성 유저를 구하는 문제.
먼저 id와 login_date를 기준으로 dense_rank를 써서 순위를 매긴다.
dense_rank를 쓰는 이유는 하루에 2번 이상 로그인하는 경우에도 동일한 순위로 간주해야 하기 때문.
그리고 로그인 날짜와 이 dense_rank의 차이를 '일 단위로' 구하기 위해
date_sub 함수를 써서 interval ~ day로 나타내 주었다.
여기까지의 결과를 temp라는 이름의 CTE에 저장한다.
WITH temp
AS
(
SELECT DISTINCT id,
login_date,
dense_rank() over(partition BY id ORDER BY login_date) AS "row_id",
date_sub(login_date, INTERVAL dense_rank() over(partition BY id ORDER BY login_date) day) AS "date_group"
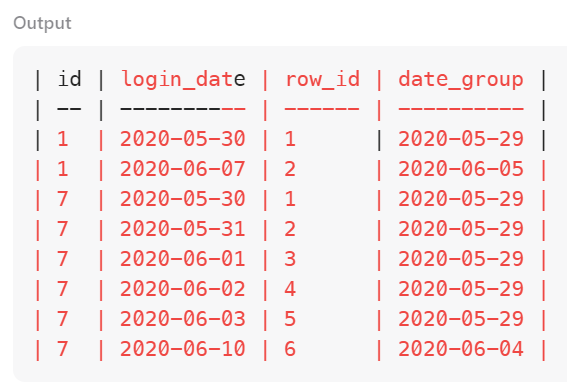
FROM logins)temp의 결과를 출력해 보면 아래와 같다.
연속으로 로그인했다면 최초 로그인 날짜로부터 하루가 증가할 때마다 row_id도 1씩 증가할 것이기 때문에, 둘 사이의 차이인 date_group도 2020-05-29로 동일한 것을 볼 수 있다. 이 date_group의 숫자가 연속 로그인을 판단하는 기준이 된다.
다음으로 temp로부터 id와 date_group, 그리고 그에 해당하는 건수(cnt)를 불러온다. 2020-05-29 그룹의 갯수가 5개라는 것은 위에서 봤던 대로 id 7번 유저가 5일 연속 로그인했다는 뜻이 된다.
WITH temp
AS
(
SELECT DISTINCT id,
login_date,
dense_rank() over(partition BY id ORDER BY login_date) AS "row_id",
date_sub(login_date, INTERVAL dense_rank() over(partition BY id ORDER BY login_date) day) AS "date_group"
FROM logins)
SELECT id,
date_group,
count(*) AS "cnt"
FROM temp
GROUP BY 1,
2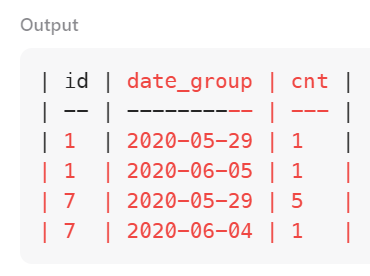
이제 위까지의 결과를 result CTE로 저장하고
Accounts 테이블과 조인한 뒤, where 절에 cnt>=5 조건을 넣고
필요한 정보를 출력하면 정답이다. cnt 자리에 다른 숫자 n을 넣으면
n일 연속 로그인한 유저의 정보를 뽑을 수 있기 때문에,
아래의 Follow up에도 대응할 수 있는 쿼리다.
Follow up: Could you write a general solution if the active users are those who logged in to their accounts for n or more consecutive days?
WITH temp
AS
(
SELECT DISTINCT id,
login_date,
dense_rank() over(partition BY id ORDER BY login_date) AS "row_id",
date_sub(login_date, INTERVAL dense_rank() over(partition BY id ORDER BY login_date) day) AS "date_group"
FROM logins),
result
AS
(
SELECT id,
date_group,
count(*) AS "cnt"
FROM temp
GROUP BY 1,
2)
SELECT DISTINCT r.id,
a.name
FROM result r
LEFT JOIN accounts a
ON r.id = a.id
WHERE cnt >= 5;문제 링크
가능한 모든 사각형 조합을 확인한 후
면적이 같을 경우 P1이 작은 것들만 출력하는 문제.
P1과 P2를 cross join하고
where절에 조건을 넣어서 간단하게 구할 수 있다.
- 자기 자신과는 사각형을 만들 수 없기 때문에 id가 같은 경우는 제외
- x_value나 y_value가 같으면 사각형이 만들어질 수 없기 때문에 이 경우도 제외.
- 면적이 같을 경우 P1이 작은 경우만 출력하면 되기 때문에 p1.id < p2.id 조건 추가
SELECT p1.id AS "P1",
p2.id AS "P2",
Abs(p1.x_value - p2.x_value) * Abs(p1.y_value - p2.y_value) AS "area"
FROM points p1,
points p2
WHERE ( p1.id <> p2.id )
AND ( p1.x_value <> p2.x_value )
AND ( p1.y_value <> p2.y_value )
AND ( p1.id < p2.id )
ORDER BY 3 DESC,
1,
2;