오늘 내용은 코드 실습과 병행해서 정리해야겠다.
백분위수, 상자그림(Box plot)
-
데이터의 전체 분포를 알아보는 데에도 백분위수는 유용하다. 주로 사분위수Quantile나 십분위수Decile이 공식적으로 사용되는데, 이 중에서도 사분위수는 꼬리 부분, 즉 외측 범위를 묘사하는 데 유용하다.
-
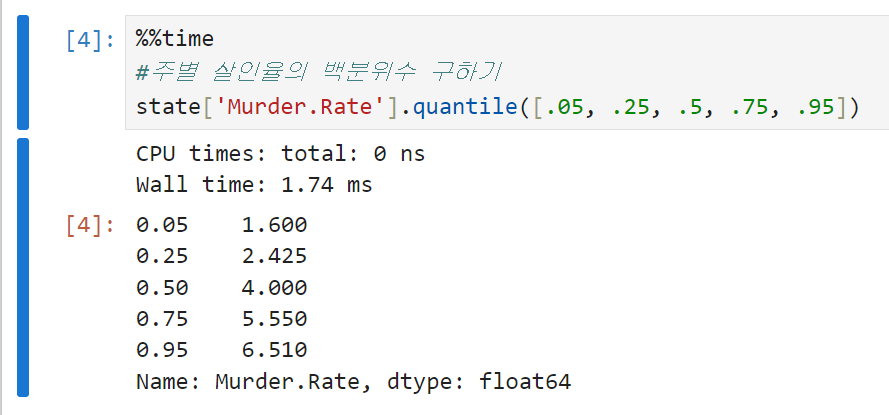
주별 살인율의 백분위수를 각각 구해보면, 5% 백분위수는 1.6% 정도인 데 비해 95% 백분위수는 6.5%에 달한다. 중간값을 보면 10만명 당 4건 꼴로 살인이 발생하는 것을 알 수 있다.
-
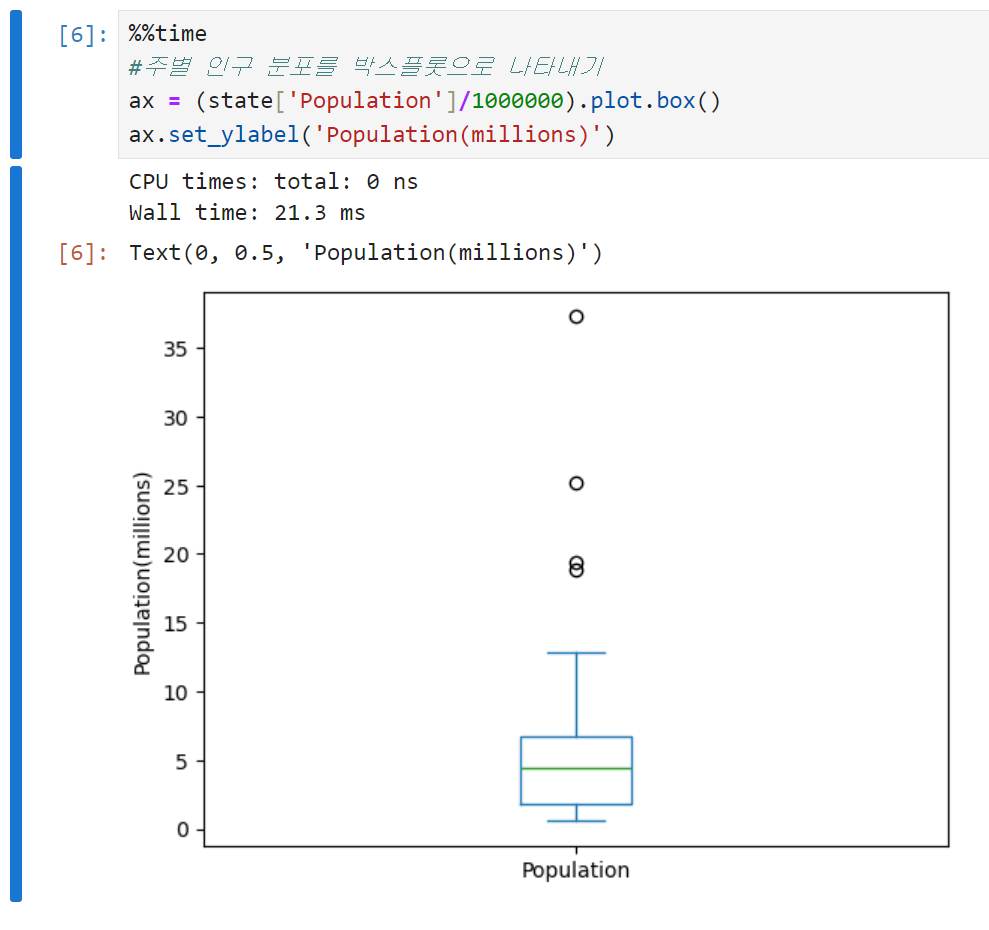
이 백분위수를 시각적으로 표현해 데이터의 분산도를 손쉽게 파악할 수 있게 만든 것이 투키에 의해 처음 소개된 상자그림(Box plot)이다. 실제로 의사소통을 할 때는 주로 박스플롯이라고 얘기했던 듯. 박스플롯으로 주별 인구를 나타낸 결과는 아래와 같다.
-
박스플롯 읽는 법은 크게 아래와 같다.
-
중간값은 상자 안의 초록색 수평선으로 표시된다. 주별 인구의 중간값이 약 500만 정도 된다는 걸 바로 알 수 있다.
-
상자의 위쪽과 아래쪽 경계는 각각 75%백분위수, 25%백분위수를 의미한다. 박스 경계가 걸쳐져 있는 범위를 보면 75%와 25% 백분위수의 차이, 즉 주 절반 정도가 200만에서 700만 정도에 분포한다는 것을 알 수 있다.
-
위아래로 뻗어있는 수염Whisker은 각각 Q1-1.5×IQR, Q3+1.5×IQR까지다. IQR의 150% 범위까지는 허용하되, 그 범위를 넘어가는 값은 이상치(특잇값)로 간주된다. 이상치는 하나의 점 또는 원으로 표시된다.
-
도수분포표, 히스토그램
-
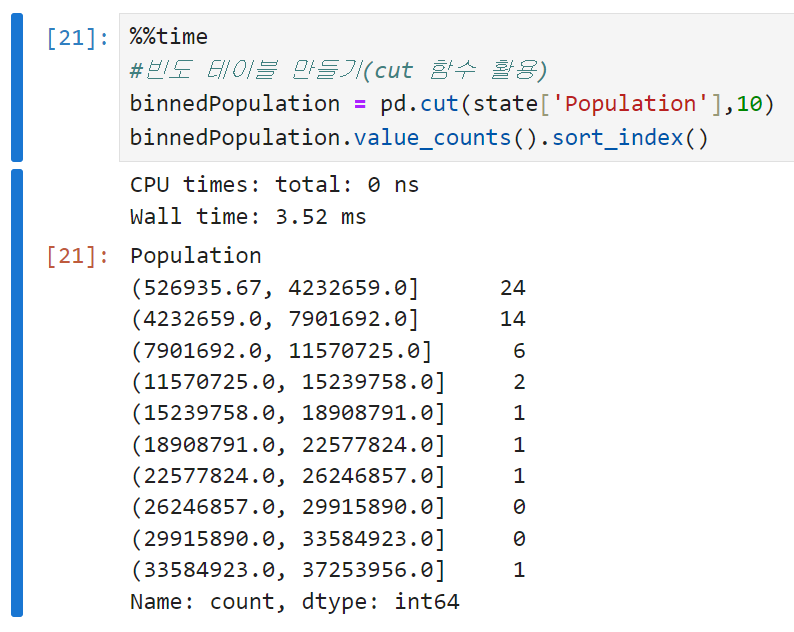
도수분포표는 변수의 범위를 동일한 크기의 구간으로 나눈 다음, 각 구간마다 몇 개의 변숫값이 존재하는지를 나타내기 위해 사용한다. 판다스에서 cut 함수를 쓰면 각 구간에 매핑하는 시리즈를 만들 수 있다. (이 때 sort_index()를 써서 출력 순서를 제어하지 않으면 빈도수를 기준으로 내림차순 정렬되기 때문에 구간이 꼬이게 됨)
-
도수분포표와 백분위수 모두 구간을 나눠서 데이터를 살펴보는 접근법이다. 다만,
- 백분위수(사분위수, 십분위수)는 각 구간에 같은 수의 데이터가 포함되도록, 즉 구간의 크기를 다르게 나누는 방법이고
- 도수분포표는 구간의 크기가 같도록, 즉 구간 안에 다른 갯수의 데이터가 들어오게 하는 방법이라는 차이가 있다.
-
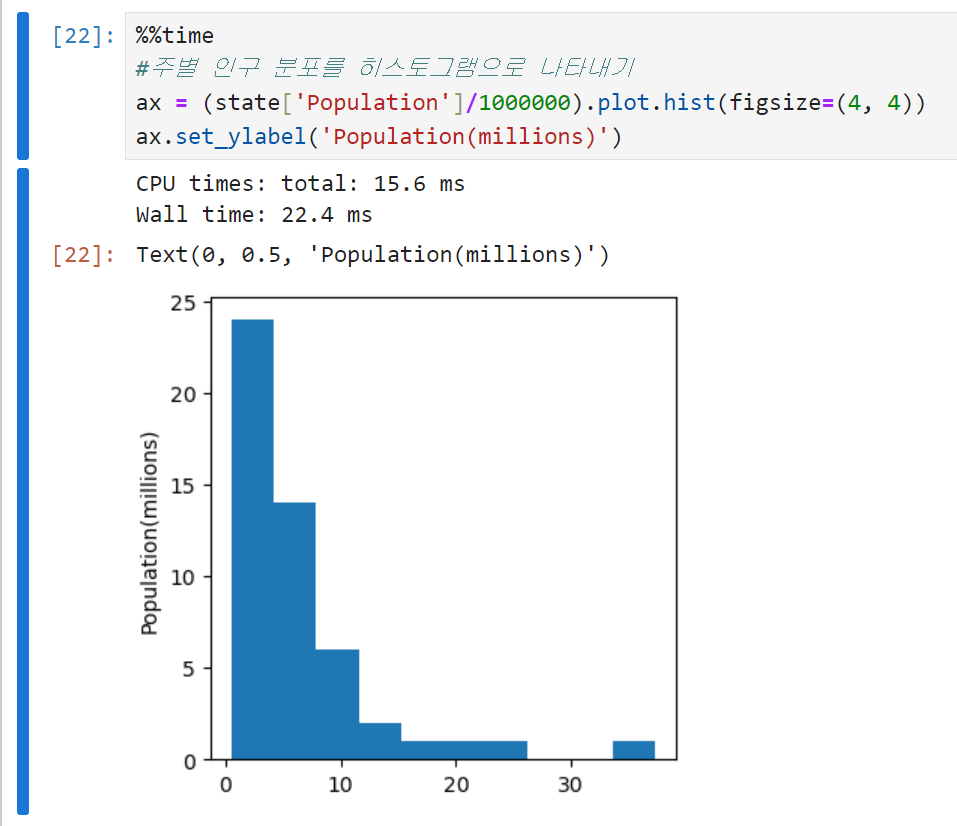
위에서 만든 도수분포표를 시각화하면 히스토그램이 된다. x축에는 구간 정보만 표시하고 y축에는 해당 구간별 데이터의 갯수를 표시한다.
-
보통 히스토그램에는 아래의 정보가 담겨 있다.
- 그래프에 빈 구간들이 있을 수 있다. (구간의 크기를 조금씩 바꿔보는 것도 방법임. bins 인수로 조절할 수 있음)
- 각 구간은 동일한 크기를 갖는다.
- 구간의 수(크기)는 사용자가 결정할 수 있다.
- 빈 구간이 있지 않은 이상, 각 막대는 공간 없이 서로 붙어있다.
밀도 그림과 추정
-
밀도 그림은 데이터의 분포를 연속된 선으로 보여준다. 좀 더 부드러운 버전의 히스토그램이라고 생각하면 될 듯. 밀도는 커널밀도추정을 통해 데이터로부터 직접 계산한다.
-
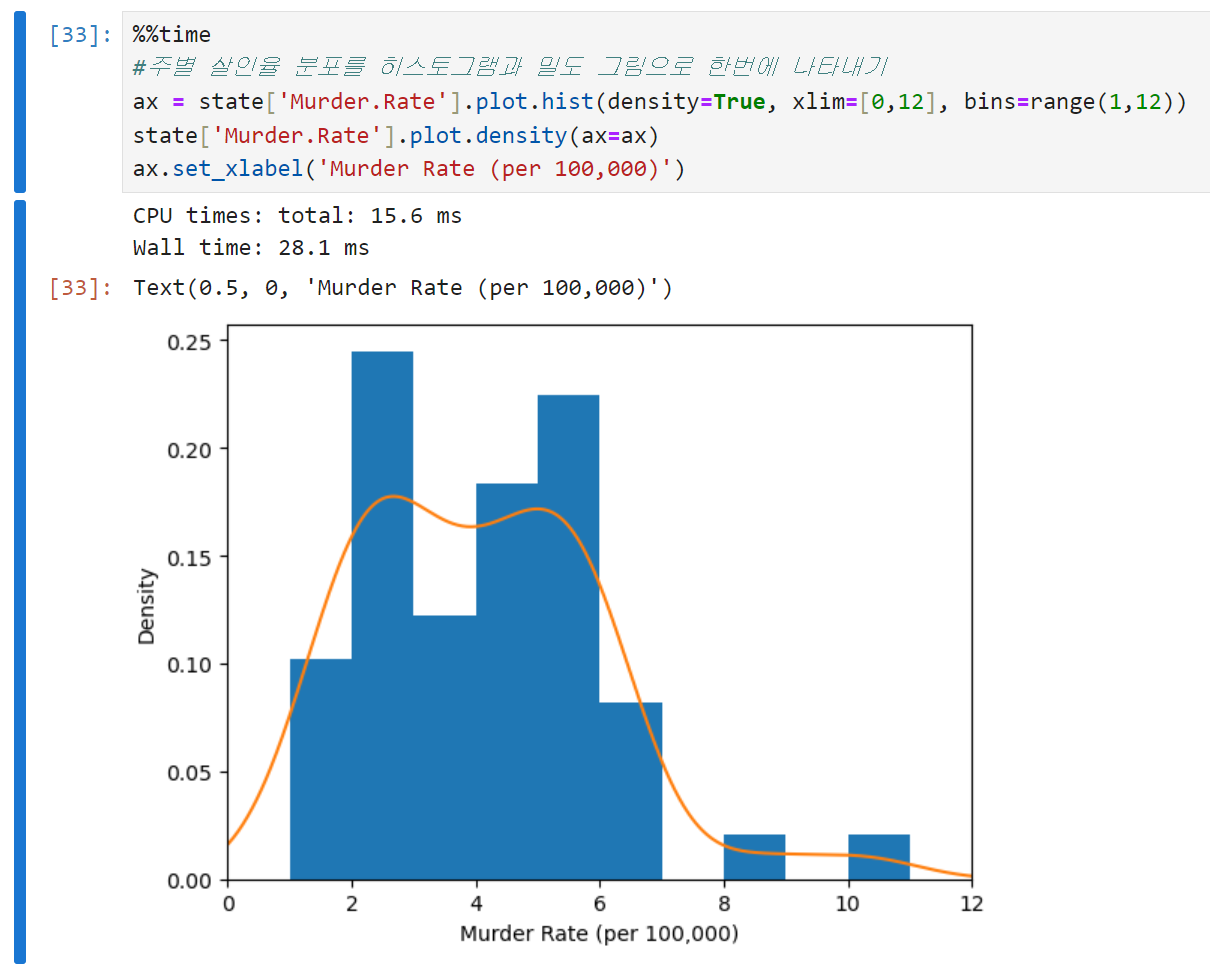
판다스에서는 밀도 그림을 생성하기 위해 density 메서드를 제공한다. 아래는 코드와 출력 결과 예시.
-
각 코드의 의미는 아래와 같다.
- density = True
밀도 그림을 그리기 위해 설정한 인수. 히스토그램을 정규화한다고 보면 된다. 여기서 density를 False로 바꾸면 밀도 그림을 그리지 못한다. 히스토그램의 y축 단위가 바뀐다는 점에도 유의. - xlim = [0,12]
x축의 범위를 0에서 12까지로 제한한다는 의미. 꼭 얼마로 해야 한다는 정답은 없지만, 데이터의 분포를 가장 잘 표현할 수 있는 값을 찾아주는 것이 바람직. - bins = range(1,12)
히스토그램의 구간(bin)을 1에서 11까지 정수로 지정한다. 만약 저 인수를 range(1,5)로 바꾸면 5를 넘어가는 구간에서는 출력되지 않는다. - density(ax=ax)
density plot을 히스토그램(ax)과 겹치기 위해 설정한 인수. 같은 그래프에 밀도 그림을 추가하기 위해 설정해 주었다.
- density = True
-
위에서 그렸던 히스토그램과의 가장 큰 차이는 y축의 스케일. 밀도 그림에서는 갯수가 아닌 비율을 나타낸다. (density=True) 밀도 곡선 아래의 총 면적은 1이고, 구간의 갯수 대신 x축의 두 점 사이의 곡선 아래 면적을 계산한다.
세 줄 요약
- 도수 히스토그램은 y축에 횟수를, x축에 변숫값들을 표시하고 한 눈에 데이터의 분포를 볼 수 있게 만든 것이다. 이 히스토그램에 보이는 횟수들을 표 형태로 나타내면 도수분포표가 된다.
- 박스플롯에서 상자의 위와 아래 경계는 각각 75%, 25% 백분위수를 의미하며, 이 역시 데이터의 분포를 한눈에 파악할 수 있게 한다.
- 밀도 그림은 히스토그램의 부드러운 버전이라고 할 수 있다. 데이터로부터 이 차트를 얻기 위해서는 어떤 함수를 구해야 하는데, 가능한 추정 방법은 여러 가지가 있다.
