유일값, 값 세기
Series에서
Series에 담긴 값의 정보를 추출하는 메서드도 있다.
예를 들어,

이렇게 생긴 Series 객체가 있다고 했을 때,
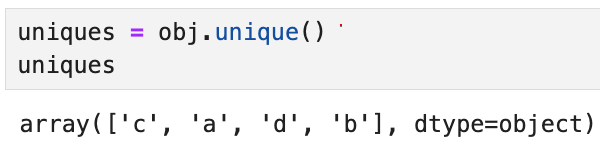
unique() 함수를 쓰면 Series에서
중복되는 값을 제거하고 고유값만 남은 Series를 반환한다.
이 때 고유값들이 정렬된 순서로 반환되지는 않지만,
필요하다면 .sort()를 써서 정렬할 수도 있다. 즉,

이렇게 나오는 셈인데, sort()는 결과를 반환하지 않고
그냥 원본의 순서만 변경하므로
결과를 보고 싶으면 따로 print를 해 줘야 한다.

sorted 함수를 쓰면 원본을 변경하지 않고
정렬된 새 리스트를 얻을 수 있다. 편한 걸 골라 쓰면 될 듯.
한편, value_counts() 메서드는
Series에서 도수(frequency)를 계산해 반환한다. 예를 들어,
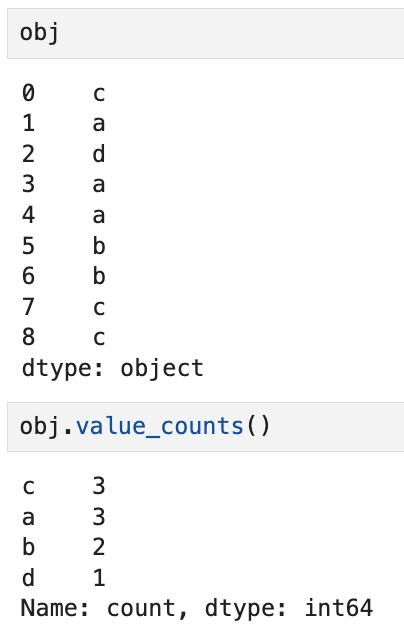
위의 Series에서는
c가 3번, a가 3번, b가 2번, d가 1번 등장했음을 알 수 있다.
이 때 value_count() 메서드에서 반환하는 Series는
담고 있는 값을 내림차순 정렬하는 것이 기본이고,
판다스의 최상위 메서드이기 때문에 어떤 배열이나 순차 자료구조에도 사용할 수 있다.
즉,
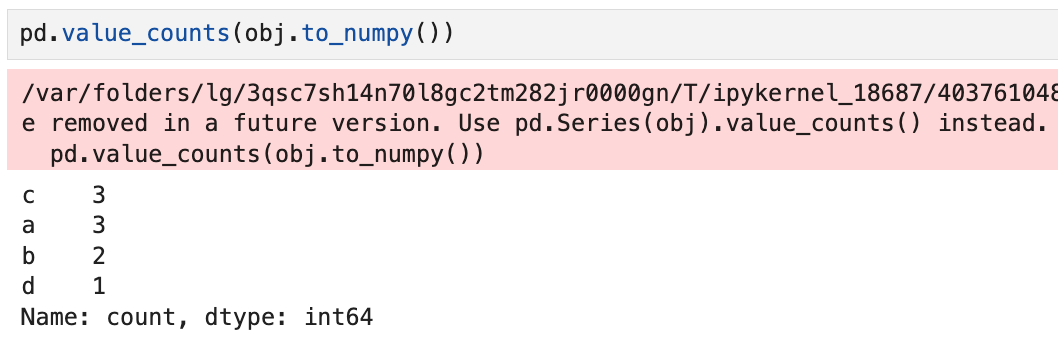
이렇게 쓰는 것도 가능은 하다.
다만 위의 경고 메시지에서도 보이는 것처럼,
앞으로는 판다스에서 이런 형태의 사용법은 사라질 예정이고
위에서 본 것처럼 obj.value_counts()로만 사용해야 한다.
isin 메서드는 어떤 값이 Series에 존재하는지를 나타내는
불리언 벡터를 반환해 준다. Series나 DataFrame의 열에서
어떤 값을 골라내고 싶을 때 유용하게 쓰인다. 예를 들어,

위에서 본 obj가 이렇게 생겼다고 했을 때,
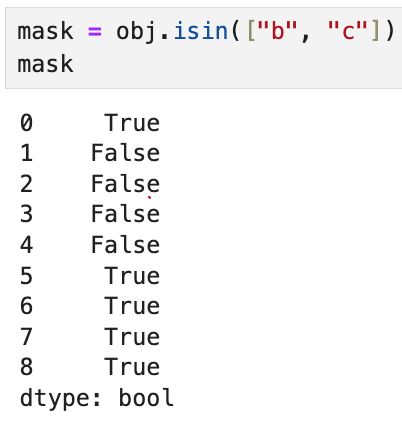
mask는 "b" 혹은 "c"가 obj안에 있는지를 나타내므로,
mask를 실행한 결과는 위와 같다.

mask를 obj에 적용하면 (보통 '씌운다'고 많이들 표현했었다)
obj 중에서도 mask의 조건이 True인,
즉 b나 c를 값으로 갖는 인덱스와 값이 출력된다.
isin과 관련 있는 Index.get_indexer 메서드는
여러 값이 들어있는 배열에서 고유값의 배열을 구할 수 있다. 예를 들어,

unique_vals의 인덱스 순서는 c가 0, b가 1, a가 2다.
이걸 Index(unique_vals)에 넣은 다음 .get_indexer를 써서
to_match라는 객체에 적용하면
to_match의 각 요소들에 대해 unique_vals의 인덱스대로 출력해 준다.
※ 만약 unique_vals의 값 중 to_match와 매칭되지 않는 값이 있다면 -1이 출력된다.
DataFrame에서
DataFrame에서 여러 열에 대해
히스토그램을 그리기 위해 빈도를 세야 하는 경우가 있다.
예를 들어,

이렇게 생긴 DataFrame이 있다고 해 보자.
위에서 살펴본 value_counts() 메서드는
Series에 종속된 메서드이므로, value_counts를 쓰려면
반드시 Series 형태로 만들어서 추출해야 한다. 즉,
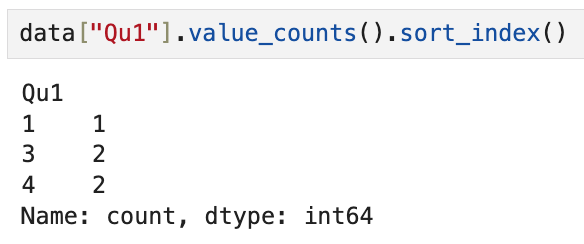
data["Qu1"]이라고 써서 하나의 Series만 불러온 후에
value_counts()를 써야 한다.
하지만 필요에 따라 모든 열에서 빈도를 구해야 할 수도 있는데,
매번 Series 형태로 추출하는 것은 비효율적일 수 있다.
DataFrame의 모든 열에서 위와 같은 계산을 하려면,
즉 DataFrame 전역적으로 사용하려면 DataFrame에 종속된
apply 메서드에 value_counts()를 넘기면 된다. 예를 들어,
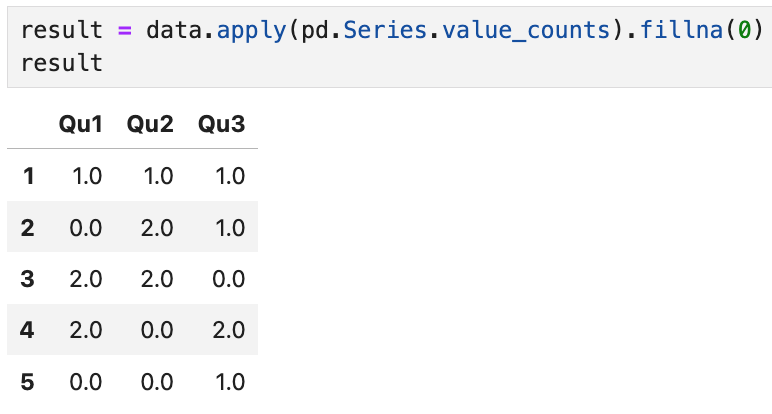
전체 열의 고유값(1,2,3,4,5)이
결과값의 행 인덱스가 된다. 그리고 각각의 값들은
각 열에서 해당 값이 몇 번 출현했는지를 나타낸다.
예를 들어 Qu1 열에는 1이 1번, 3이 2번, 4가 2번 등장했음을 알 수 있다.
빈도수가 없는(NaN) 경우는 fillna 인자에 의해 0으로 채워진다.
책에서는 원래
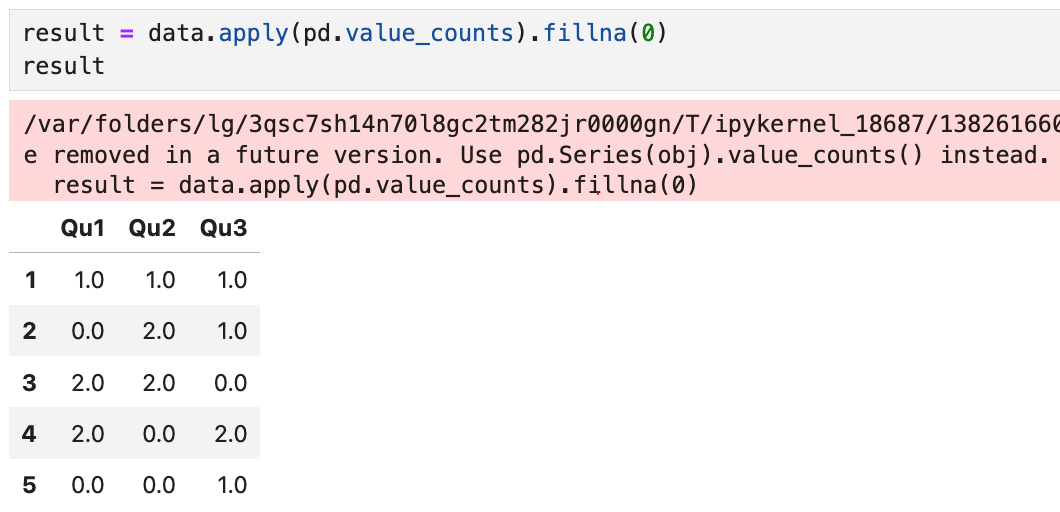
이렇게 pd.value_counts로만 썼는데,
앞으로 판다스에서 해당 문법은 사라질 예정이라는 경고창이 뜬다.
대신 pd.Series.value_counts를 쓰라고 해서
위에서는 Series.를 통해 value_counts가 독립적인 함수가 아니라
Series에 종속된 메서드임을 명시했다.
코딩의 일관성을 유지하고 혼동을 방지하려는 의도로 보인다.
헷갈리기 쉬운 게,
DataFrame에도 value_counts 메서드가 있다!
근데 작동 방식은 약간 다르다. 어떻게 다르냐면

예를 들어 이렇게 생긴 데이터프레임이 있다고 했을 때,
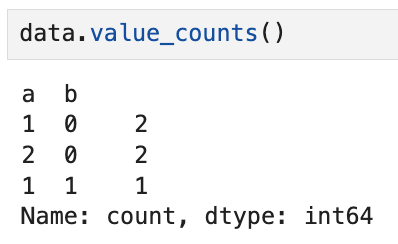
value_counts를 적용하면 결과가 이렇게 나온다.
이게 무슨 뜻이냐면,
DataFrame에서의 value_counts()는
DataFrame 전체에 대해 고유한 행(row)의 조합을 기준으로 빈도를 계산한다.
즉 위의 결과는 a, b 순으로 (1,0) 조합이 2번,
(2,0) 조합이 2번, 그리고 (1,1) 조합이 1번 나왔다는 뜻이다.
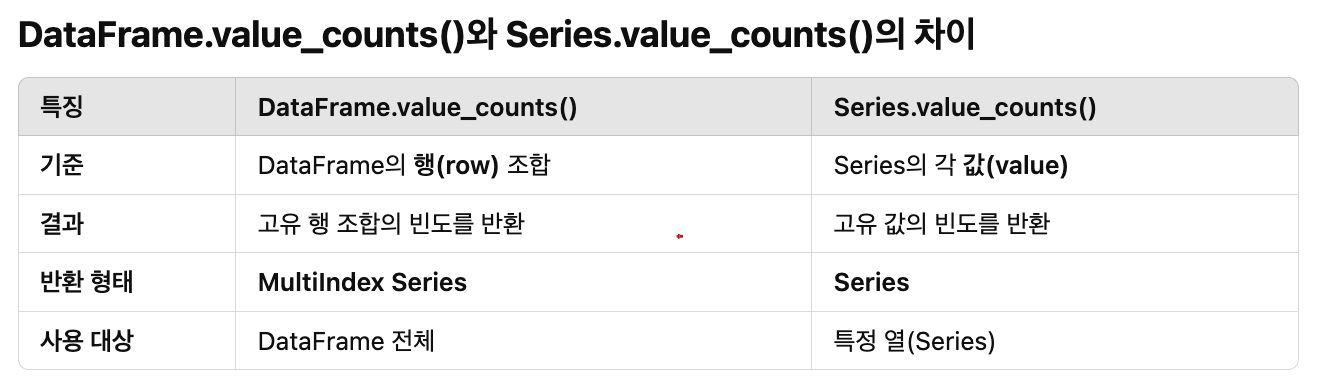
따라서 DataFrame에서의 value_counts는
고유한 데이터 조합이 얼마나 자주 발생했느냐를 파악할 때 유용하다.
그 목적이 아니라면 Series형태로 추출해서 Series에 종속된 value_counts를 쓰든가,
아니면 apply를 써서 빈도수 세기를 전역 적용하는 방식을 써야 한다.
