상관관계와 공분산
상관관계correlation나 공분산covariance과 같은 요약통계 계산에는
두 쌍의 인수가 필요하다. 예를 들어,

이렇게 2개의 데이터를 데이터프레임 형태로 불러온다고 생각해 보자.
(pkl은 파이썬 피클 바이너리 파일이다)
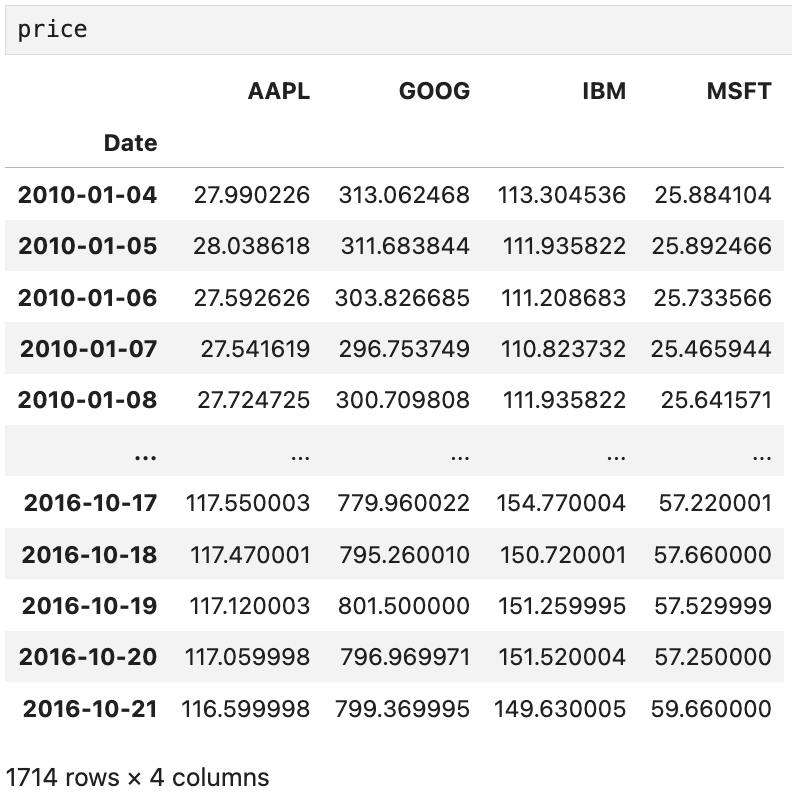
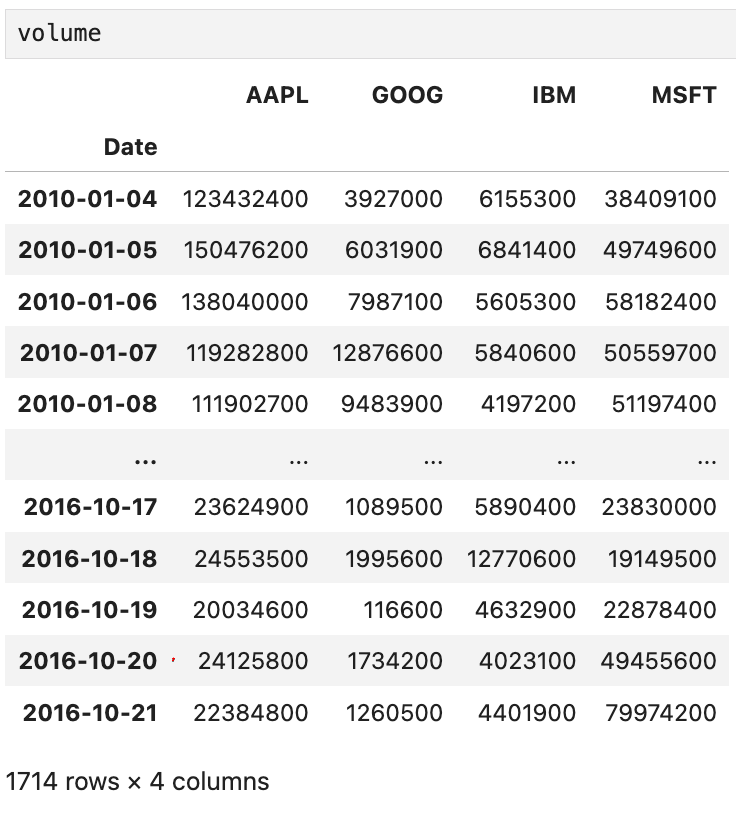
price와 volume은 각각 이렇게 생겼고,
애플, 구글, IBM, 마이크로소프트의 거래 정보를 담고 있다.
이제 각 주식의 가격 변화를 백분율로 계산해 보면
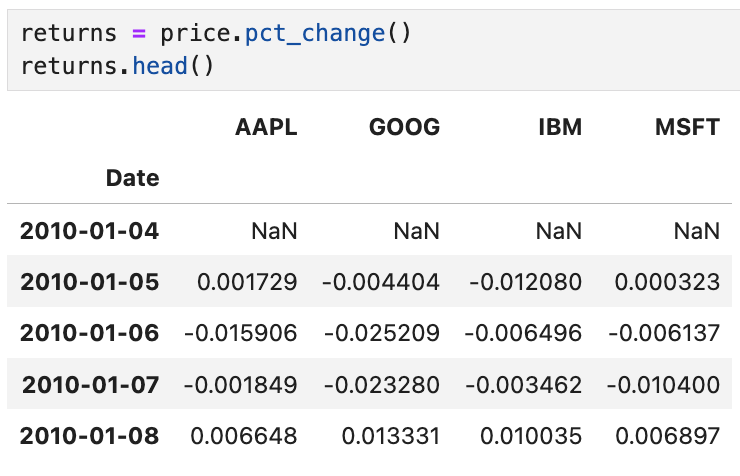
앞에서 소개한 적이 있는 pct_change()를 써서
바로 직전 행과의 차이를 %로 나타낸 결과다.
2010-01-04는 이전 열이 없으므로 모두 NaN이 뜬다.
이 때, corr메서드는 상관관계를,
cov메서드는 공분산을 계산한다.
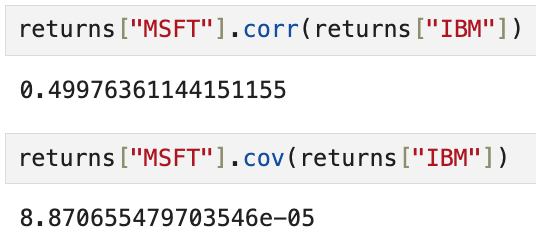
이렇게 쓰면 MSFT라는 열과 IBM열 전체의 상관관계/공분산을 계산한다.
즉, 연속하는 두 Series의 상관관계/공분산을 계산해주는 것.
반면,
DataFrame에서의 corr과 cov는
각 DataFrame 행렬상의 상관관계와 공분산을 계산한다.
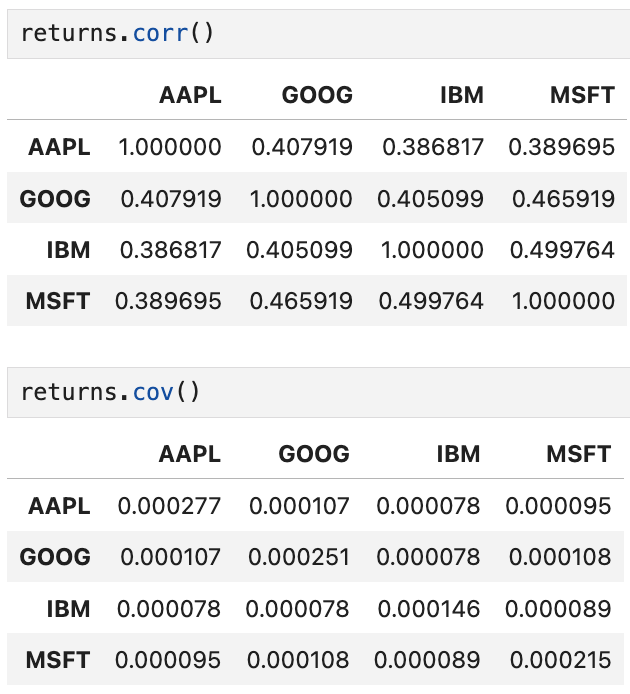
각 행과 열에 대응하는 상관계수가 공분산이 계산되었다.
AAPL과 AAPL의 예에서 볼 수 있듯, 자기 자신과의 상관계수는 1이다.
DataFrame의 corrwith 메서드를 사용하면
다른 Series나 DataFrame과의 상관관계도 계산할 수 있다.
Series를 넘기면 각 열에 대해 계산한 상관계수가 담긴 Series가 반환된다.
예를 들어,
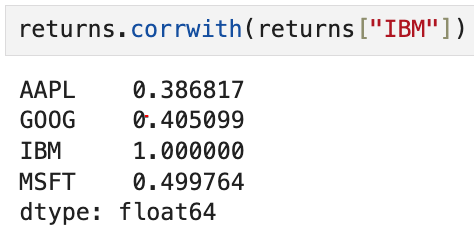
returns["IBM"]이라는 Series를
corrwith의 인수로 넘긴 결과,
AAPL, GOOG, IBM, MSFT와의 상관계수가 계산된 Series가 반환되었다.
이 결과는 위에서 returns.corr()를 계산했을 때의 IBM 열의 결과와 동일하다.
corrwith의 인수로 DataFrame을 넘기면
맞아떨어지는 열 이름에 대한 상관계수를 계산한다.
이 예에서는 거래량(volume)과 백분율 변화(returns)에 대한
상관계수가 계산된다. 즉,
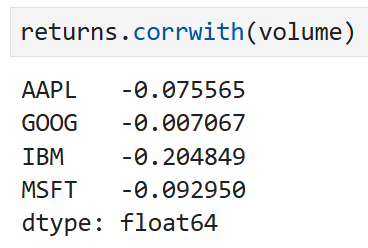
- AAPL의 백분율 변화와 AAPL의 거래량의 상관계수
- GOOG의 백분율 변화와 GOOG의 거래량의 상관계수
- IBM의 백분율 변화와 IBM의 거래량의 상관계수
- MSFT의 백분율 변화와 MSFT의 거래량의 상관계수
이렇게 일치하는 이름의 열들끼리 상관계수가 계산되어
Series 형태로 반환되는 것이다.
만약 axis = "columns"나 axis = 1을 넣어서
옵션을 넘기면 각 행마다 상관계수나 공분산이 계산된다.
즉, 이 경우는 각 날짜마다 returns와 volume의
상관계수가 계산되는 것이다.
모든 경우 데이터는 상관관계를 계산하기 전에
인덱스의 이름순으로 정렬된다 (행, 열 무관하게)
