범주형 데이터
7.5.1 개발 배경과 동기
하나의 열에서 특정 값이 반복되는 경우가 많다.
앞서 배열 내의 고유한 값을 추출하거나
특정 값이 얼마나 많이 존재하는지를 확인하는
unique와 value_counts를 살펴봤었다. 예를 들어,
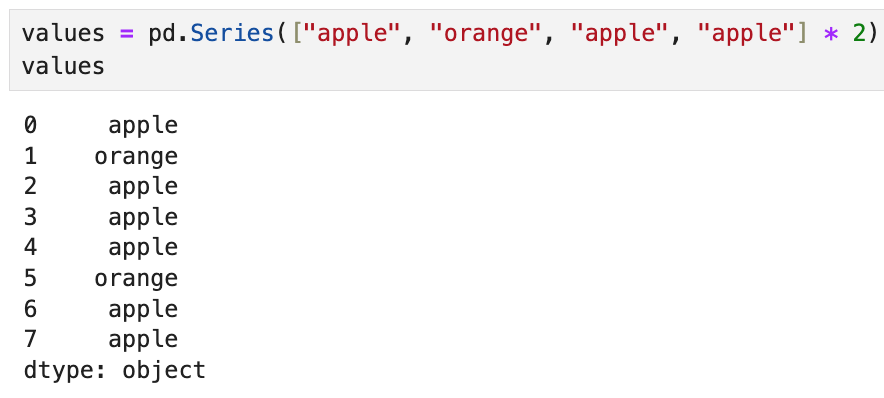
이렇게 생긴 series가 있다고 했을 때,
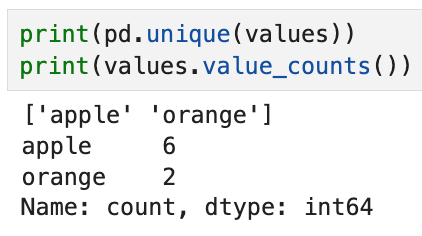
고유값은 apple과 orange,
그리고 각 고유값의 갯수는 6개와 2개가 있음을 쉽게 구할 수 있다.
다만 데이터 웨어하우스, 통계 컴퓨팅 등 다양한 시스템에서는
중복된 데이터를 얼마나 효율적으로 저장하고 계산할 수 있느냐가 관건이다.
따라서 데이터 웨어하우스에서는 구별되는 값을 담은
차원 테이블dimension table과 이를 참조하는 정수 키를 사용한다.
예를 들어,
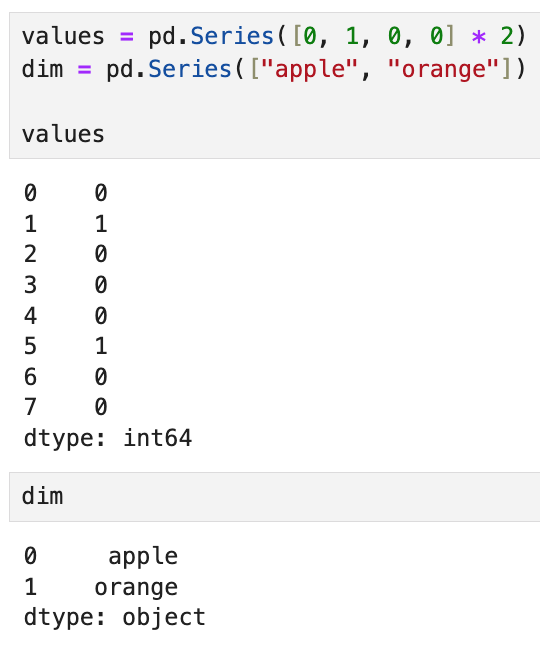
똑같은 결과지만 이렇게 표현하는 것이다.
take 메서드를 사용하면 Series에 저장된
원래 문자열을 구할 수도 있다. 즉,

이렇게도 쓸 수 있다.
예시는 데이터 갯수가 너무 작아서
별 차이 없어보일 수도 있는데,
대규모 데이터에서는 첫 번째 방식으로 표기할 경우
메모리 낭비가 생길 수 있다.
이러한 정수 표현을 범주형, 또는 딕셔너리형 표기법이라고 부르고,
별개의 값을 담은 배열은 범주형, 딕셔너리형,
혹은 단계별 데이터라고 부른다.
(Categorical이라고도 부른다.)
범주형 표현을 사용하면
데이터 분석 작업에서 큰 성능 향상을 얻을 수 있는데,
범주 코드(범주형 데이터를 가리키는 정수값)를 변경하지 않은 채로
범주형 데이터를 변경할 수 있다.
비교적 간단하게 할 수 있는 변환은 아래와 같다.
- 범주형 데이터의 이름 변경하기
- 기존 범주형 데이터의 순서를 바꾸지 않고 새로운 범주 추가하기

기본기를 소홀히 하지 말자





