7.5.2 판다스의 Categorical 확장형
판다스에는 정수 기반의
범주형 데이터를 표현할 수 있는 특수한 데이터 유형인
Categorical 확장형이 있다.
주로 문자열 데이터에서 유사한 값이 다수 존재하는 경우
데이터를 효과적으로 압축해 적은 메모리에서도
빠른 성능을 낼 수 있게 하는 기법이다.
예를 들어,

이렇게 생긴 데이터프레임이 있다고 하자.
- 변수 rng는 Numpy의 난수 생성기(random number generator) 인데, 여기서 seed를 12345로 고정함에 따라 코드를 반복해서 실행해도 숫자가 바뀌지 않게 된다.
- df에서 basket_id는 np.arange이고, 사전에 df의 길이를 N으로 지정해 두었기 때문에 딱 길이에 맞게 0부터 7까지의 정수가 반환된다.
- count는 rng.integers에 따라 3에서 15까지의 정수를 반환하는데, 이 역시 size = N이므로 8개만 나온다.
- weight는 uniform, 즉 균등분포를 전제하고 0부터 4까지 임의의 값을 뽑는다. (균등분포는 모든 값의 뽑힐 확률이 동일하다는 의미) 역시 size = N이므로 8개만 나온다.
여기서 df['fruit']는 파이썬 문자열 객체의 배열Series인데,
아래와 같은 방법으로 범주형 데이터로 쉽게 변경할 수 있다.
즉,
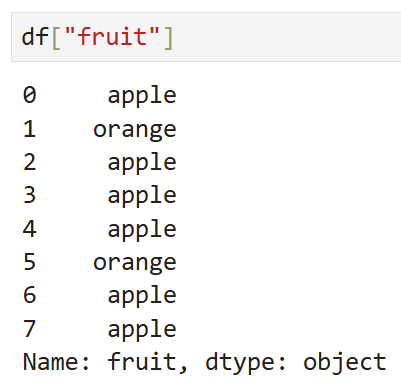
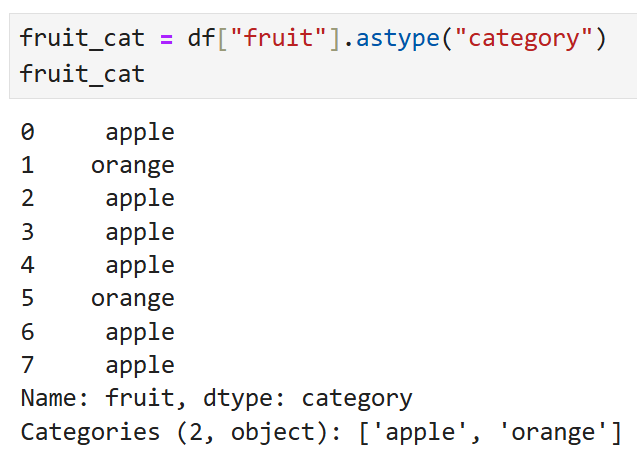
출력 결과의 생김새는 똑같지만
두 Series의 dtype은 다르다.
원본 df의 df['fruit']은 object,
즉 넘파이에서의 파이썬 일반 객체지만
새롭게 변환한 fruit_cat은 category,
즉 Pandas의 특수 데이터 타입으로 변경된다.
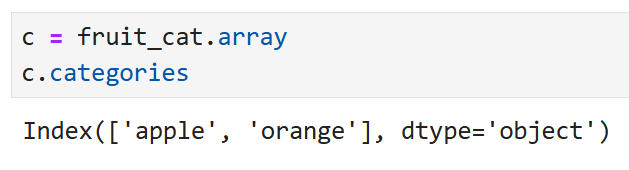
판다스의 array 속성은
Series 객체의 저장된 데이터(값)에 직접 접근할 수 있는 속성이다.
따라서, fruit_cat의 type은 Series지만
fruit_cat.array의 type은 Categorical로 나오는 것.


Categorical 객체에는 categories 속성과 codes 속성이 있다.

앞선 포스팅에서 이러한 범주형 표기법을
딕셔너리형 표기법이라고도 부른다고 했었는데,
다음과 같은 codes 속성과 categories 속성을 매핑할 수도 있다.
출력된 결과의 type이 딕셔너리임을 확인할 수 있다.

이렇게 변환이 완료된 값을
DataFrame의 열로 대체해 줄 수도 있다.
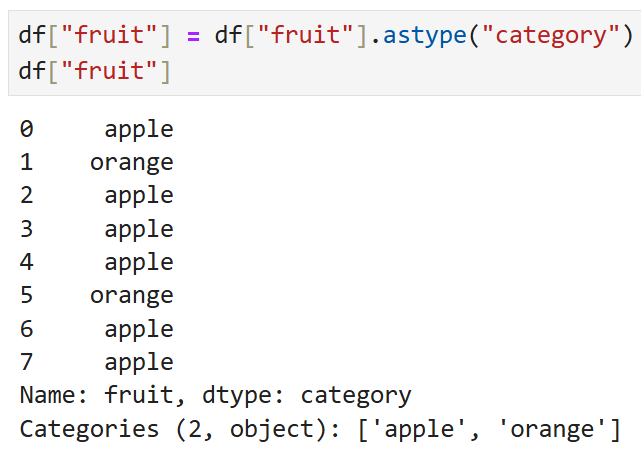
아니면 파이썬 시퀀스에서
pandas.Categorical을 직접 생성해 줄 수도 있다.

기존에 정의된 범주와 범주 코드가 있다면
from_codes로 범주형 데이터를 생성할 수도 있다. 예를 들어,

이렇게 써 주면
from_codes에 의하여 Categorical이 생성되는데,
categories의 순서대로 codes가 매칭된다.
즉 foo가 0, bar가 1, baz가 2기 때문에
codes로부터 생성한 Categorical이 저렇게 나오는 것.
범주형으로 변경하는 경우
명시적으로 순서를 지정하지 않는 한
입력 데이터의 순서에 따라 순서가 지정된다.
따라서 만약 일정 순서를 지정해 주고 싶으면
from_codes 안에 인자를 넣어서 제어해 줄 수 있다. 즉,

foo < bar < baz라고 되어있는 부분은
foo, bar, baz 순으로 순서를 갖는다는 의미다.
순서가 없는 범주형 인스턴스는 as_ordered를 이용해
정렬해 줄 수 있다. 예를 들어,
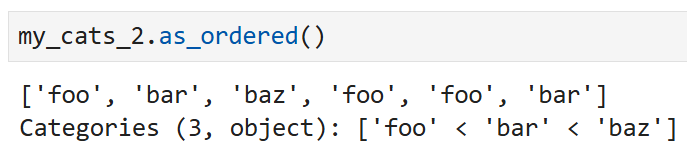
이렇게 써 놔도 결과는 같다.
여기서는 문자열로만 예를 들었지만
범주형 데이터가 반드시 문자형일 필요는 없다.
범주형 배열은 변경이 불가능한 값이라면
어떤 자료형이라도 포함할 수 있다.
