기술 통계 계산과 요약
판다스 객체는 일반적인 수학 메서드와 통계 메서드를 갖고 있다.
이 메서드들은 대부분 하나의 Series나 DataFrame의
행과 열에서 단일 값(합이나 평균 등)을 뽑아내는
축소reduction, 혹은 요약 통계summary statistics에 속한다.
넘파이 배열에서 제공하는 메서드와는 다르게
판다스의 수학/통계 메서드는 처음부터
누락된 데이터, 즉 결측치는 제외하도록 설계되었다.
예를 들어,

이렇게 생긴 데이터프레임이 있다고 했을 때,
데이터프레임의 sum 메서드를 호출하면
각 열의 합을 담은 Series를 반환한다. 즉,
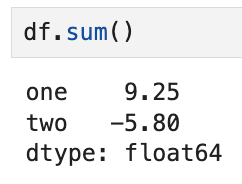

one열에 해당하는 모든 행의 sum,
two열에 해당하는 모든 행의 sum을 뽑아주게 된다. (결측치는 제외하고)
만약 각 행에 해당하는 모든 열의 sum을 뽑고 싶으면
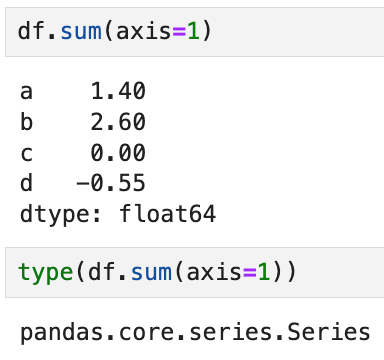
이렇게 axis 인자를 넣어서 구분해 주면 된다.
결과는 마찬가지로 Series 형태로 반환된다.
전체 행과 열의 모든 값이 NA 값이면 그 합은 0이 되고,
값이 하나라도 NA라면 결과값은 NA가 된다.
skipna 옵션을 써서 비활성화할 수 있고,
이 경우 행과 열의 NA값은 해당 결과도 NA로 지정한다.
위의 예를 다시 보면
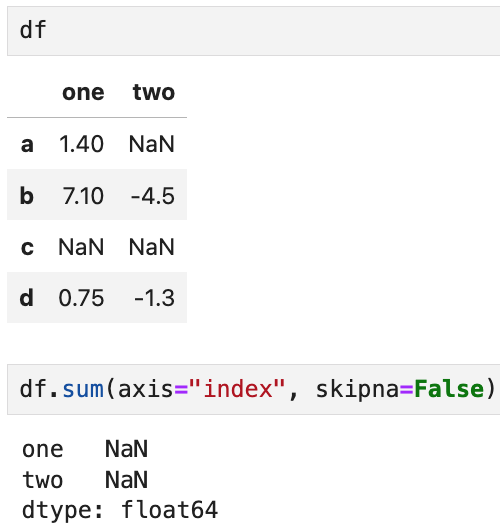
처음 예시와 동일하게 열끼리의 sum을 수행했는데,
skipna = False 옵션 때문에 NaN이 끼어있는 열의 연산 결과도 NaN이 되었다.
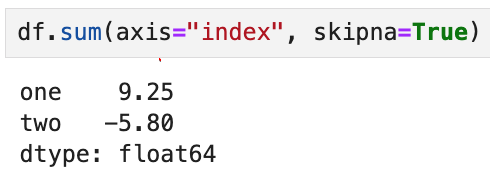
skipna = True로 변경하면 맨 처음 df.sum()을 한 것과 동일한 결과가 나온다.
즉, skipna = True가 디폴트임을 알 수 있다.
행 방향 연산에서도 skipna에 따라 결과가 달라지는 것은 동일하다.
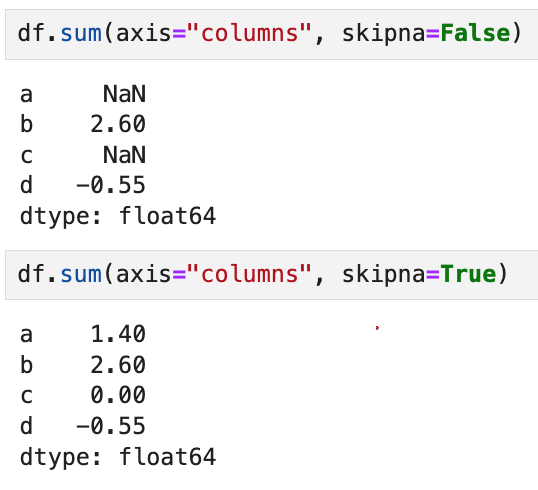
하나라도 결측치가 끼어있을 때
결과를 NaN으로 받아보고 싶다면 skipna = False로 지정하면 되겠다.
다만 isna()가 있으므로 결측치의 존재 유무를
굳이 이런 방식으로 확인할 필요까지는 없을 듯.
평균과 같은 일부 집계 연산에서는
결과값을 생성하기 위해 최소 하나 이상의 NA가 아닌 값이 필요하다.
즉, 계산하고자 하는 행이나 열의 모든 값이 NA라면 평균을 구할 수 없다.

위의 예에서,
각 행별로 평균을 구했을 때
-
a행에서는 two열에 해당하는 값이 NaN이지만, 평균을 구한다고 해서 0.7이 되는 게 아니고 그대로 1.4로 결과가 출력된다.
- NaN은 계산할 때 아예 skip되는 것이 디폴트라고 했는데, 이 말은 평균을 구할 때도 똑같이 적용된다.
- 그냥 없는 값처럼 취급하기 때문에 산술평균을 구할 때도 2가 아니라 1로 나누게 되어 1.4가 나오는 것.
-
c행에서는 one, two열에 해당하는 값들이 모두 NaN이기 때문에 평균이 구해지지 않고 NaN으로 출력됐다. 이 때 결과가 NaN이라고 해서 아예 출력되지 않는 건 아니라는 점에도 주의할 것.
idxmin이나 idxmax와 같은 메서드는
최소, 혹은 최대값을 가진 인덱스 값이 누구인지를 알려주는
간접통계 indirect statistics를 반환한다. 예를 들어,
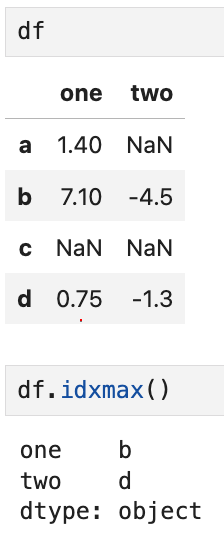
one열에서는 가장 큰 값(7.1)의 인덱스가 b이므로 b가,
two열에서는 가장 큰 값(-1.3)의 인덱스가 d이므로 d가 반환되었다.
idxmin도 최소값을 찾아준다는 점만 다를 뿐 로직은 동일하다.
또 다른 메서드로 누산accumulation이 있다.
SQL 문제풀이에서도 몇 번 해봤던 '누적 합'인데,
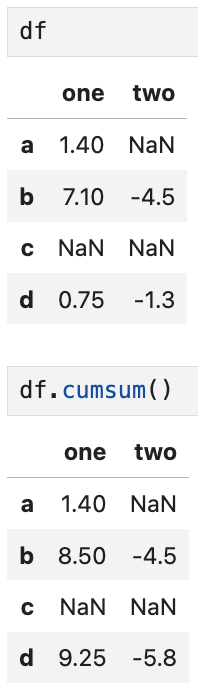
결과는 이렇게 된다.
열을 따라 쭉 내려오면서 (NaN은 없는 값이니 스킵하고) 합을 구해준다.

행 단위의 누적합을 구하고 싶으면
axis=1로 바꿔주면 된다는 점은 동일하고,
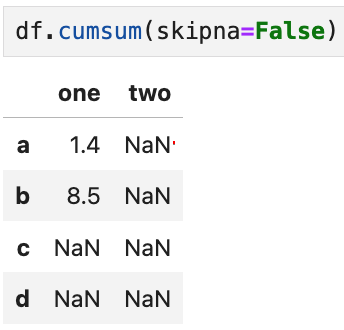
위에서 살펴본 skipna를 False로 두면 결과가 이렇게 된다.
- one열은 시작값이 NaN이 아니었기 때문에 b행까지는 연산이 정상적으로 됐지만, NaN이 있는 c행부터는 연산이 되지 않아 계속 NaN으로 출력되고
- two열은 시작값부터 NaN이었기 때문에 아예 누산이 되지 않았다.
행 단위의 누적합을 구할 때 skipna=False로 놓아도 로직은 동일하다.
축소나 누산이 아닌 다른 종류의 메서드인 describe는
한 번에 여러 개의 요약통계를 만들어주는 메서드다 (개중 여러 번 써봄)
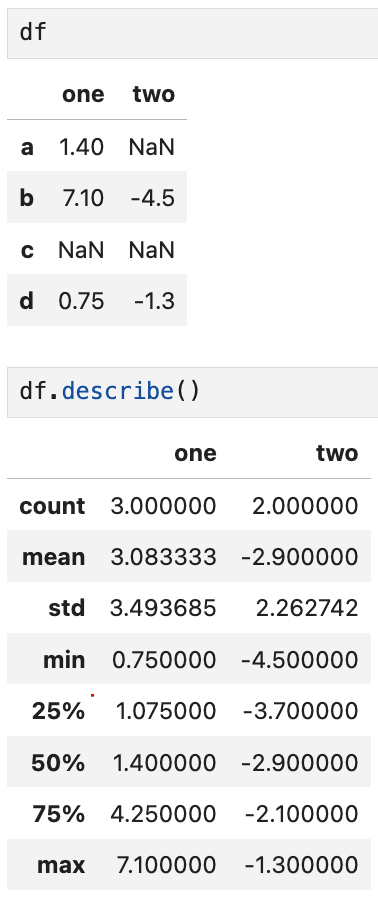
여기서도 눈여겨봐야 할 포인트는
NaN은 '아예 없는 값'이기 때문에 count나 mean은 물론이고
다른 요약통계를 구할 때도 아예 안 잡힌다는 점.
만약 수치 데이터가 아닐 경우에는 describe가
다른 요약 통계를 생성한다. 예를 들어,

이렇게 생긴 Series가 있다고 했을 때,
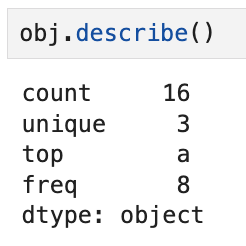
describe를 쓰면 결과가 이렇게 나온다. 여기서
- count는 전체 데이터의 길이,
- unique는 고유값의 수(a, b, c의 3개),
- top은 가장 빈도가 높은 값 (a),
- freq은 top이 나온 빈도 수를 의미한다. (a는 8번 나옴)
요약 통계와 관련된 메서드는 이 외에도 굉장히 많다.
- count
- describe
- min/max
- argmin/argmax
- idxmin/idxmax
- quantile
- sum
- mean
- median
- mad : 평균절대편차
- prod : 모든 값의 곱
- var
- std
- skew : 왜도(표준 비대칭도, 3차 적률)
- kurt : 표본 첨도(4차 적률)
- cumsum : 누계
- cummin/cummax : 누적 최소값, 누적 최대값
- cumprod : 누적곱
- diff : 1차 산술차(바로 직전값과의 차이를 계산하는데, 시계열 데이터를 처리할 때 유용하다)
- pct_change : 퍼센트 변화율
