산술 연산과 데이터 정렬
Series에서
판다스에서는 서로 다른 인덱스를 갖고 있는
객체 간의 산술 연산도 간단하게 처리할 수 있다.
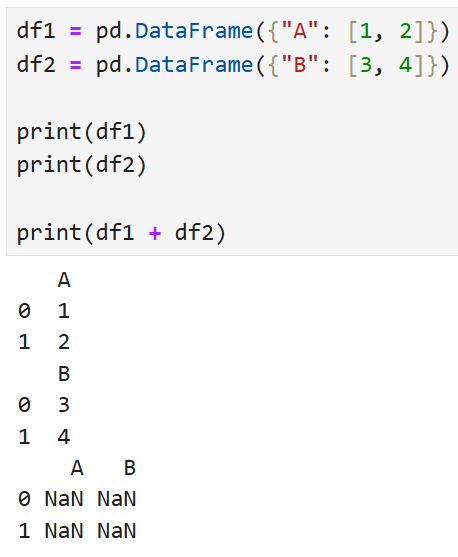
예를 들어,
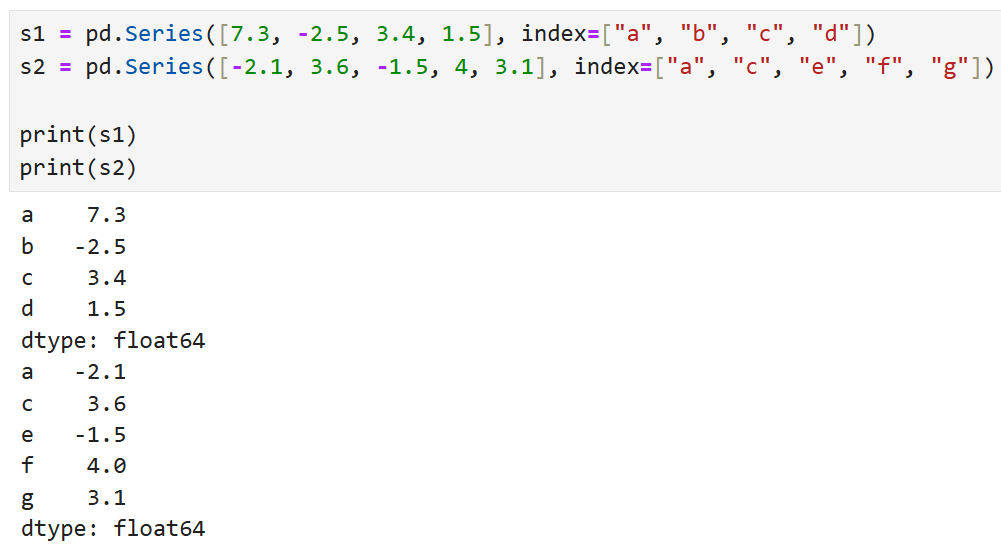
이렇게 생긴 두 개의 Series가 있다고 했을 때,
s1 + s2를 수행하면
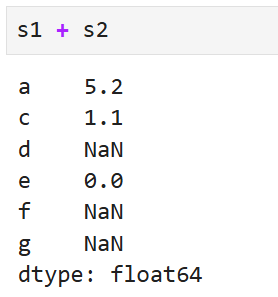
이런 결과를 얻는다. 즉,
- 객체를 더할 때 짝이 맞지 않는 인덱스가 있으면 결과에 두 인덱스가 통합되고
- 서로 겹치는 인덱스가 없을 경우에는 값이 결측치가 된다.
DataFrame에서
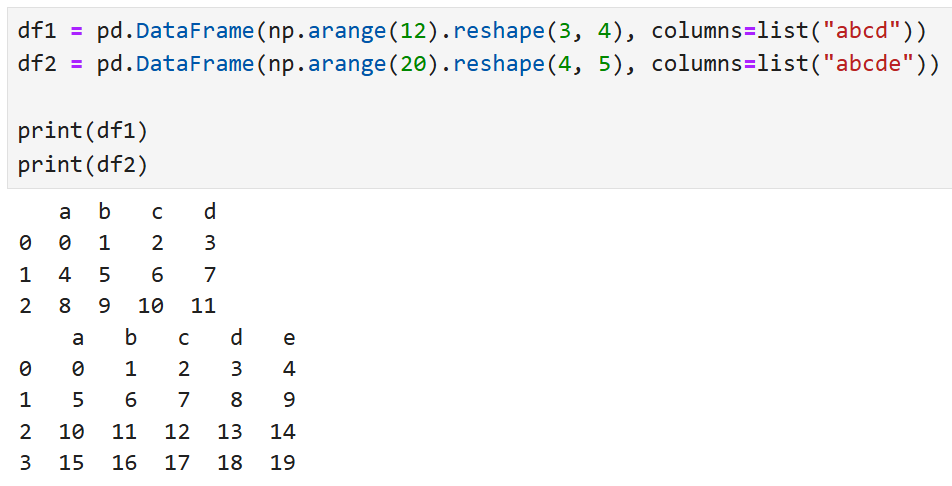
DataFrame의 경우 행과 열 모두에 정렬이 적용된다. 예를 들어
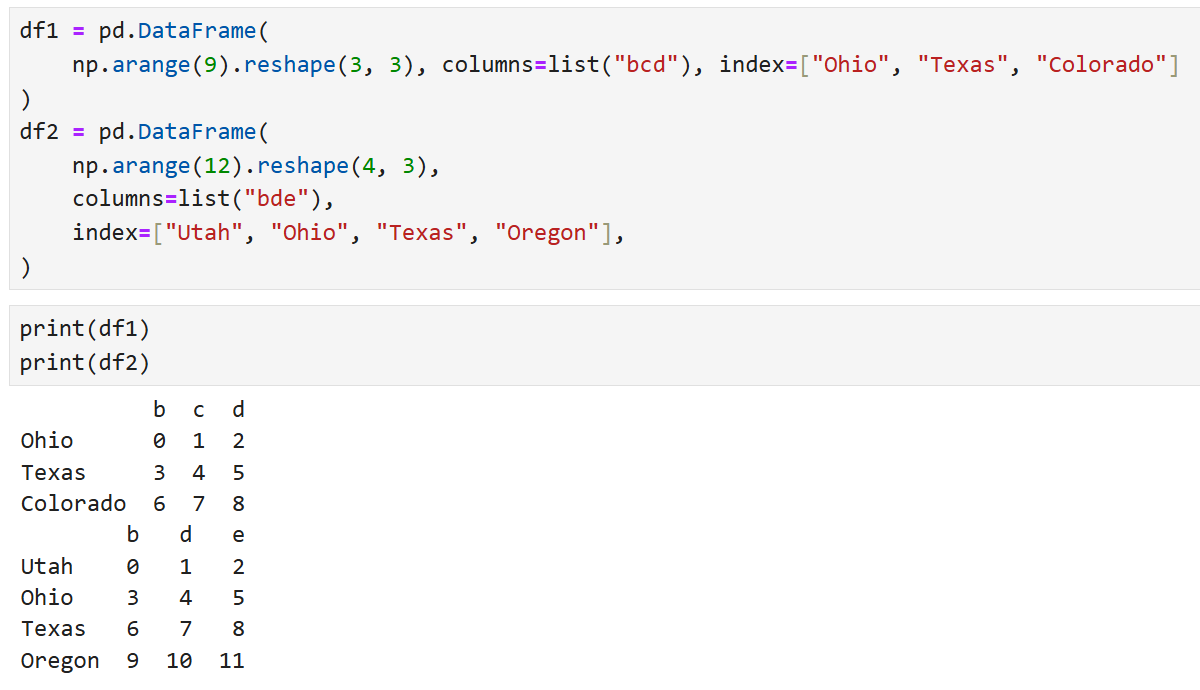
이렇게 생긴 두 개의 DataFrame이 있다고 했을 때,
df1 + df2를 수행하면
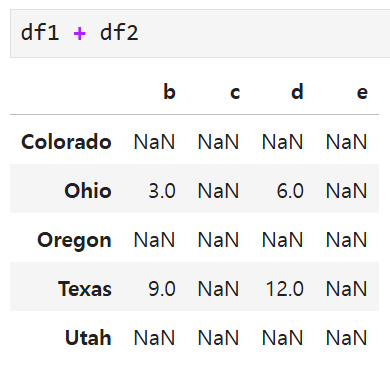
각 DataFrame에 있는 인덱스와 열이 하나로 합쳐진다.
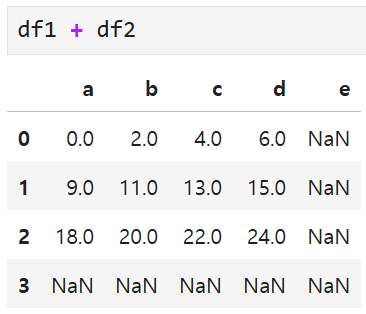
공통된 인덱스와 열을 보유한 경우에만 합 연산이 수행되고,
인덱스나 열이 겹치지 않는 경우에는 모두 NaN이 뜬다.
비슷하게,
공통된 열이나 행 레이블이 없는 DataFrame끼리 더하면
결과에는 아무것도 나타나지 않는다. (모두 NaN)
산술 연산 메서드에 채워넣을 값 지정하기
만약 인덱스가 서로 다른 객체 간의 산술 연산을 수행하려면
존재하지 않는 축의 값을 0이나 다른 특수한 값으로 지정해 줄 필요가 있다.
예를 들어,
이렇게 생긴 두 개의 DataFrame이 있다고 했을 때,
위에서 살펴본 것처럼 두 개의 객체를 그냥 더하면
공통된 인덱스를 보유하고 있는 행이나 열에 대해서만 연산이 수행되고
겹치지 않는 부분은 NaN으로 표시된다.
여기서 df1에 add 메서드를 사용해
df2와 fill_value를 인수로 전달해서 덧셈을 수행할 수도 있는데,
이렇게 하면 연산에서 누락된 값들을 fill_value 값으로 자동으로 대체할 수 있다.
즉,
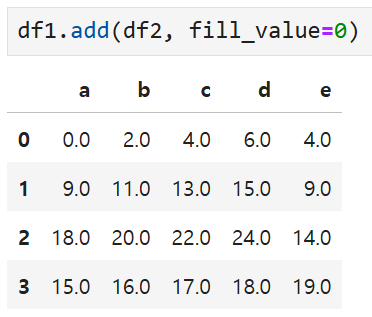
결과가 이렇게 나온다.
3행과 e열은 NaN 대신 0으로 대체되어 원래 값 + 0이 수행된 것.
예를 들어 fill_value를 10으로 바꾸면 다른 결과가 나온다.

add와 비슷한 형태로 쓸 수 있는 산술 연산 메서드로는
- add / radd : 덧셈
- sub / rsub : 뺄셈
- div / rdiv : 나눗셈
- floordiv / rfloordiv : 소숫점 내림
- mul / rmul : 곱셈
- pow / rpow : 거듭제곱
등이 있는데, 각 산술 연산자 옆에 r이 붙는 메서드는
계산 인수를 뒤집어서 계산하는 메서드다. 예를 들어,
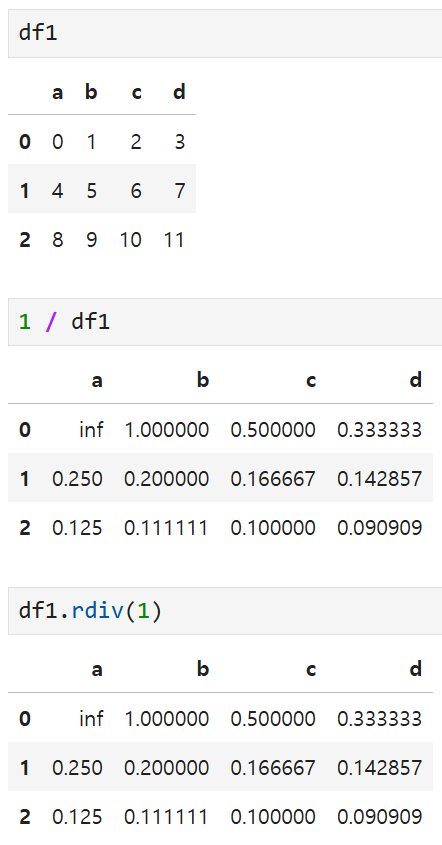
이렇게 두 코드의 계산 결과가 같다.
Series나 DataFrame을 재색인할 때에도
fill_value를 지정할 수 있다. 예를 들어,
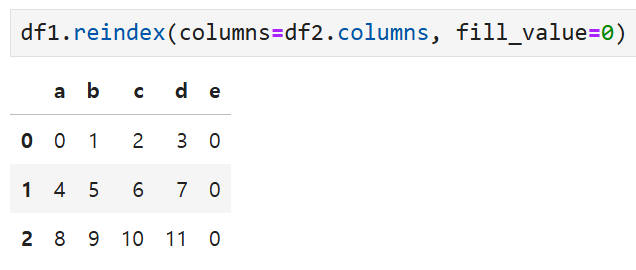
df1을 재색인하여 df2의 컬럼들(a, b, c, d, e)로
새롭게 컬럼을 만들 경우 fill_value를 0으로 설정해 두면
e열에 해당하는 값들이 0으로 채워져서 출력된다. 만약 이 인수를 빼면
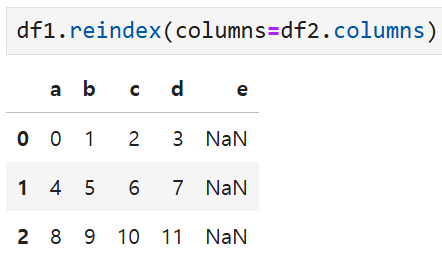
지금까지 살펴봤던 것처럼 NaN이 출력될 것.
DataFrame과 Series간의 연산
먼저 서로 차원이 다른 넘파이 배열의 연산부터 살펴보자.
예를 들어

이렇게 생긴 arr이 있다고 치면

arr[0]은 arr의 첫 번째 행이므로 [0, 1, 2, 3]이 나온다.
이제 arr에서 arr[0]을 빼면
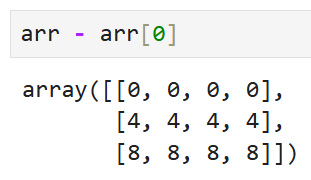
이런 결과가 나온다.
직관적으로 보면 이해가 안 되는 결과인데,
(첫 행끼리만 연산이 되어서 첫 행만 [0, 0, 0, 0]으로 나오고
나머지 두 행은 그대로일 거라고 생각하는 경우가 가장 많을 듯)
이건 넘파이의 브로드캐스팅Broadcasting 규칙 때문이다.
넘파이는 두 배열의 크기가 다를 때
자동으로 브로드캐스팅을 수행해서 계산이 가능하도록 만든다.
이 경우, [0,1,2,3]을 세 번 확장하여

이렇게 연산이 가능하게끔 같은 크기로 만들어준다.
따라서 뺄셈의 결과가 위와 같이 나올 수 있는 것.
브로드캐스팅이 있기 때문에 배열간의 크기가 달라도 편하게 계산할 수 있게 된다.
DataFrame과 Series간의 연산도 이와 유사하다. 예를 들어
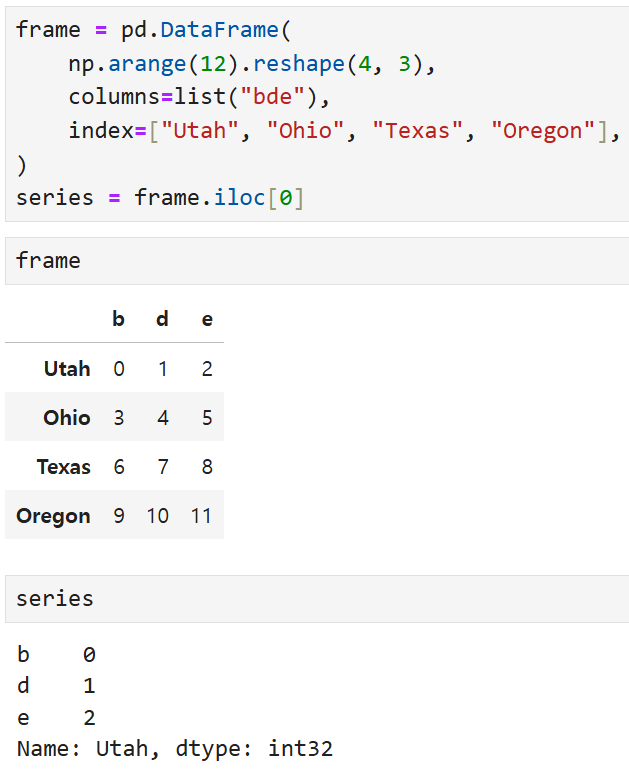
이렇게 생긴 DataFrame과 Series가 있다고 가정하고
두 객체간의 뺄셈을 수행하면 결과는 아래와 같다.
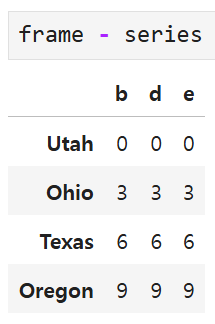
기본적으로 DataFrame과 Series간의 산술연산은
Series의 색인(즉, b, d, e)를 DataFrame의 열에 맞추고
아래 행 방향으로 브로드캐스팅한다.
만약 인덱스 값을 DataFrame의 열이나
Series의 인덱스에서 찾을 수 없다면 그 객체는 형식을 맞추기 위해 재색인된다. 즉,
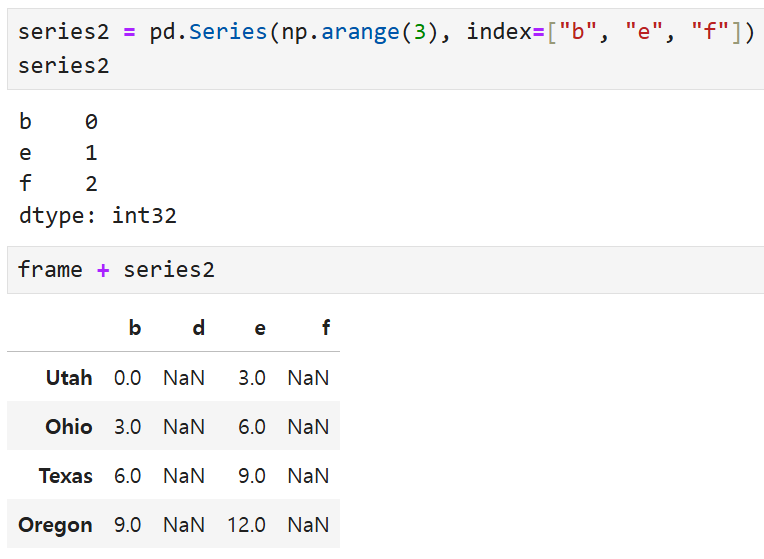
이렇게 생긴 series2와 frame을 더하면
위에서 살펴봤던 바와 같이
- 공통으로 보유한 열(b와 e)에 대해서만 덧셈 연산이 수행되고
- series2만 보유한 f열이 연산 결과에 추가되며
- 공통되지 않은 열(frame이 갖고 있던 d와 새롭게 추가된 f)의 연산 결과는 NaN이 된다.
브로드캐스팅 대신 각 행에 연산을 수항하고 싶다면
(즉, 열 방향으로 연산을 수행하고 싶다면)
산술 연산 메서드를 써서 인덱스가 일치하도록 지정하면 된다. 예를 들어,
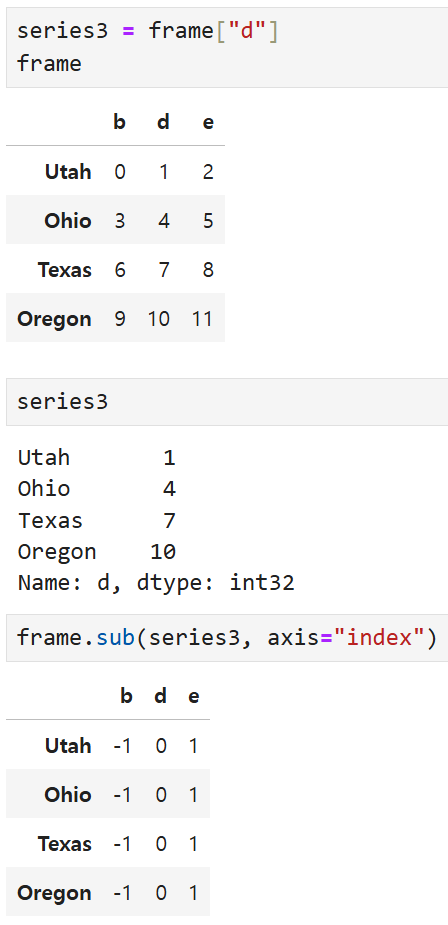
frame3에서 series3을 빼되,
인수로 넘기는 axis 값, 즉 연산을 적용할 축 번호가 행(index)을 따라 가므로
※ 열 방향으로 적용하려면 axis = columns
- Utah 행에 대해서는 일괄적으로 1을 빼고
- Ohio 행에 대해서는 일괄적으로 4를 빼고
- Texas 행에 대해서는 일괄적으로 7을 빼고
- Oregon 행에 대해서는 일괄적으로 10을 빼는
결과가 나오게 된다.
정리하자면,
넘파이에서는 차원을 자동으로 확장하지만
판다스에서는 인덱스, 혹은 열 이름의 매칭에 의존한다.
※ 책에는 "예제 코드에서 axis = "index"는 DataFrame의 열을 따라 연산을 수행하라는 의미다." 라고 되어있는데, 혼동을 줄 수 있는 설명이다.
정확하게는 "행을 따라 연산을 수행하"는 것이 맞고, 다만 그 결과가 마치 열을 따라 연산이 수행된 것처럼 보일 뿐이다.
