함수 적용과 매핑
넘파이 함수를 적용하는 경우
판다스 객체(Series, DataFrame)에도
넘파이의 유니버설 함수를 적용할 수 있다. 예를 들어,
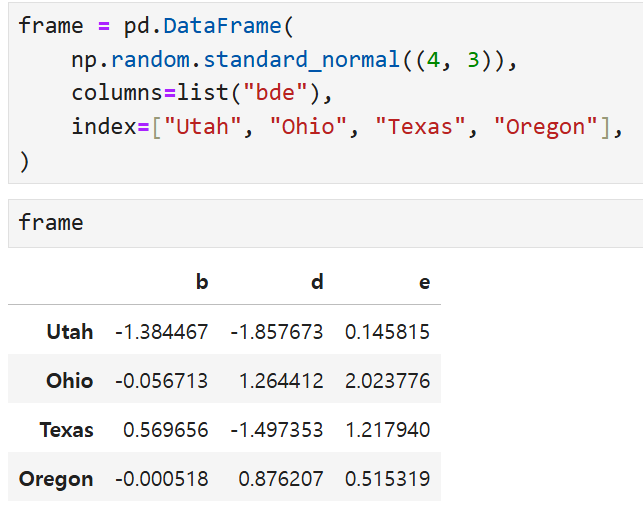
이렇게 생긴 데이터프레임이 있다고 했을 때
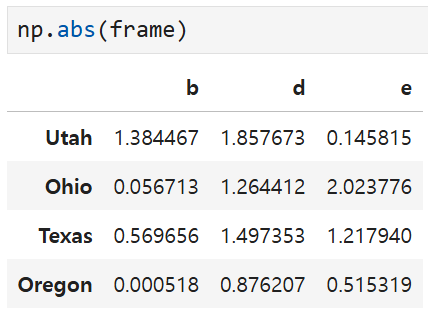
넘파이 함수 중 하나인 abs를 쓰면
frame 안에 있는 모든 원소들에 해당 함수가 적용되고,
절대값을 취한 결과가 도출된다.
행 또는 열에 함수를 적용하는 경우(apply)
또 다른 예로
각 행이나 열의 1차원 배열(Series)에 함수를 적용하는 경우,
DataFrame의 apply 메서드를 쓸 수 있다. 예를 들어
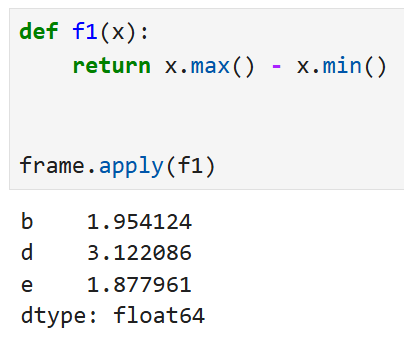
각 열의 최대값, 최소값의 차이를 구하는 함수 f1을 만들고
frame.apply를 써서 함수를 적용하면
- b열
최대값(0.569656)에서 최소값(-1.384467)을 뺀 1.954124가 나온다. - d열
최대값(1.264412)에서 최소값(-1.857673)을 뺀 3.122086이 나온다. - e열
최대값(2.023776)에서 최소값(0.145815)를 뺀 1.877961이 나온다.
이 함수는 frame의 각 열에 대해 한번씩만 수행되고,
결과값은 계산을 적용한 열을 색인으로 하는 Series 형태로 반환된다.
이와 반대로 각 행에 대해서만 연산을 수행하려면
apply 안에 인수를 넣어서 설정해 주면 된다.
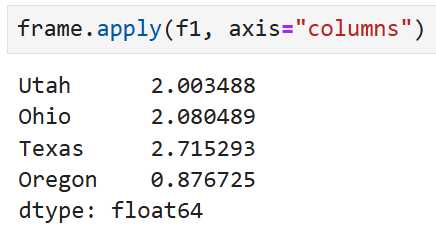
axis를 columns로 넣어주면
매 행에 대해서 동일한 연산이 수행된다.
이 때 주의할 점은
"axis를 columns로 넣었으니 결과도 columns 단위로 나오는 거 아닌가" 라는 생각인데, "열끼리 연산한다"라고 생각하는 게 정확하다. 즉, 같은 Utah 행에 대해 b열, d열, e열끼리의
최대값, 최소값을 비교해 연산하는 것.
(직관적으로 이해하려면 헷갈릴 수 있으나 알고 있어야 함)
apply 메서드에 전달된 함수가
반드시 스칼라를 반환할 필요는 없고,
여러 개의 값을 갖는 Series를 반환해도 된다. 예를 들어,
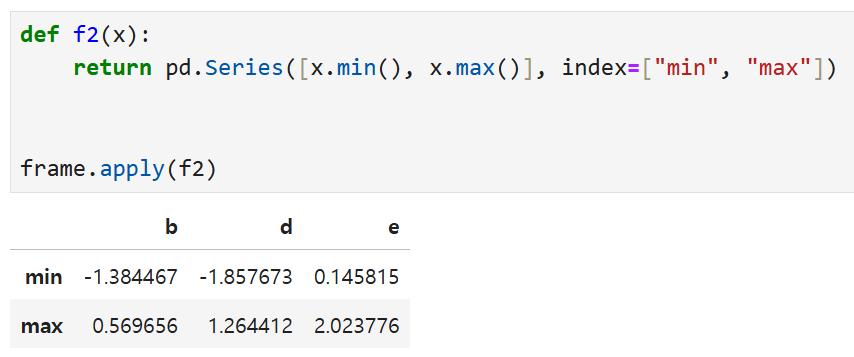
이런 함수가 있다고 했을 때
x 자리에 차례로 b, d, e 열이 오면서
최소값과 최대값을 구한 다음 DataFrame으로 바꿔서 반환한다.
(Series가 여러 개 붙어서 데이터프레임으로 나오는 것)
객체 전체에 함수를 적용하는 경우(map)
또, 배열의 각 원소에 적용되는 파이썬 함수를 쓸 수도 있다.
예를 들어 위에서 정의한 frame이라는 객체에서
부동소수점을 문자열 포맷으로 변환하고 싶으면
아래와 같은 함수를 만들어서 적용하면 된다.
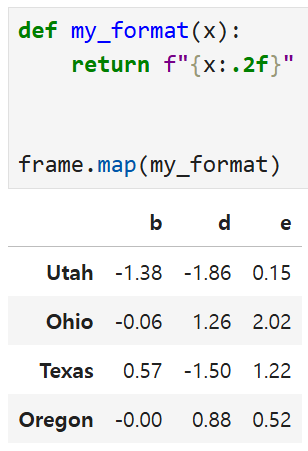
my_format 함수를 만들어서
이 함수를 통과하는 객체들의 모든 요소를 소수점 둘째자리까지만
표시되게끔 만들고 frame.map으로 적용해 주면 된다.
이 때 apply가 아니라 map을 쓰는 이유는
각 원소마다 독립적으로 함수를 적용해줘야 하기 때문.
※ apply는 행 또는 열 단위로만 동작한다.
만약 map을 쓰면서도
특정 열에만 함수를 적용하고 싶으면
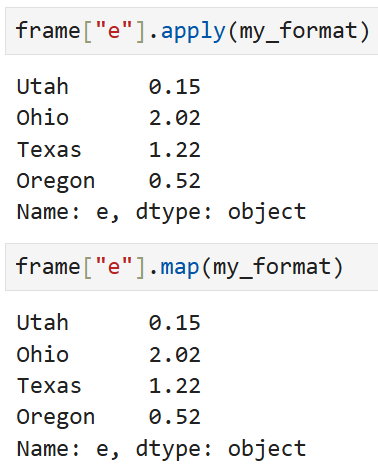
이렇게 쓰면 된다.
frame의 e열만 불러와서(frame["e"])
함수를 적용할 것이기 때문에 이 때는 apply든 map이든 상관없다.

물론 복수의 열을 불러와서 함수를 적용하는 것도 가능하다.
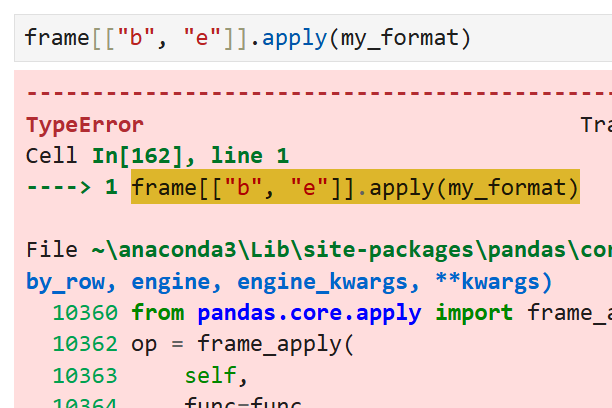
다만 위에서 언급한 대로
복수의 행, 또는 열에 함수를 적용하는데
그냥 apply를 쓰면 오류가 발생한다.
(apply는 행, 또는 열 단위로만 작동하므로)
책에는 객체의 원소 전체에 함수를 적용할 때
applymap을 쓰라고 되어 있는데, 판다스 업데이트에 따라
향후에는 applymap이 제거되고 map으로 통일될 예정이다. (applymap을 쓰면 경고 메시지가 뜸)
applymap도 아직 작동하긴 하지만 유지보수 측면에서 미리부터 map으로 대체해 두는 게 나은 듯. 다만 map은 특정 행이나 열 단위의 연산은 커버하지 못하므로 apply와 map의 사용법을 모두 알아두는 것이 필요.
