9.2.4 산포도
산포도scatter plot는 두 개의 "1차원" 데이터 묶음간의
관계를 나타낼 때 특히 유용한 그래프다.
예를 들어,
macrodata 데이터셋에서
몇 가지 변수만 불러서 data로 구성한 다음,
로그를 취하고 차이를 계산한 결과다.
- log(data) : data에 있는 모든 컬럼에 자연로그를 취한다. 로그를 취하는 이유는 비율 변화율을 해석하기 쉬워지고 데이터의 분포를 정규분포에 보다 근접하게 만들 수 있기 때문. exponential 패턴을 linear로 변환하는 데 유용하다.
- diff() : 현재 값에서 직전 값을 빼는 연산을 수행한다. 로그변환된 값에 대해 차분을 구하면 각 시점간의 로그'변화율'을 구할 수 있다.
- dropna() : diff 연산을 수행하면 첫 번째 행은 (뺄 수 있는 직전 행이 없으므로) NaN이 된다. 따라서 dropna를 통해 이 결측치들을 깔끔하게 제거해 주는 것.
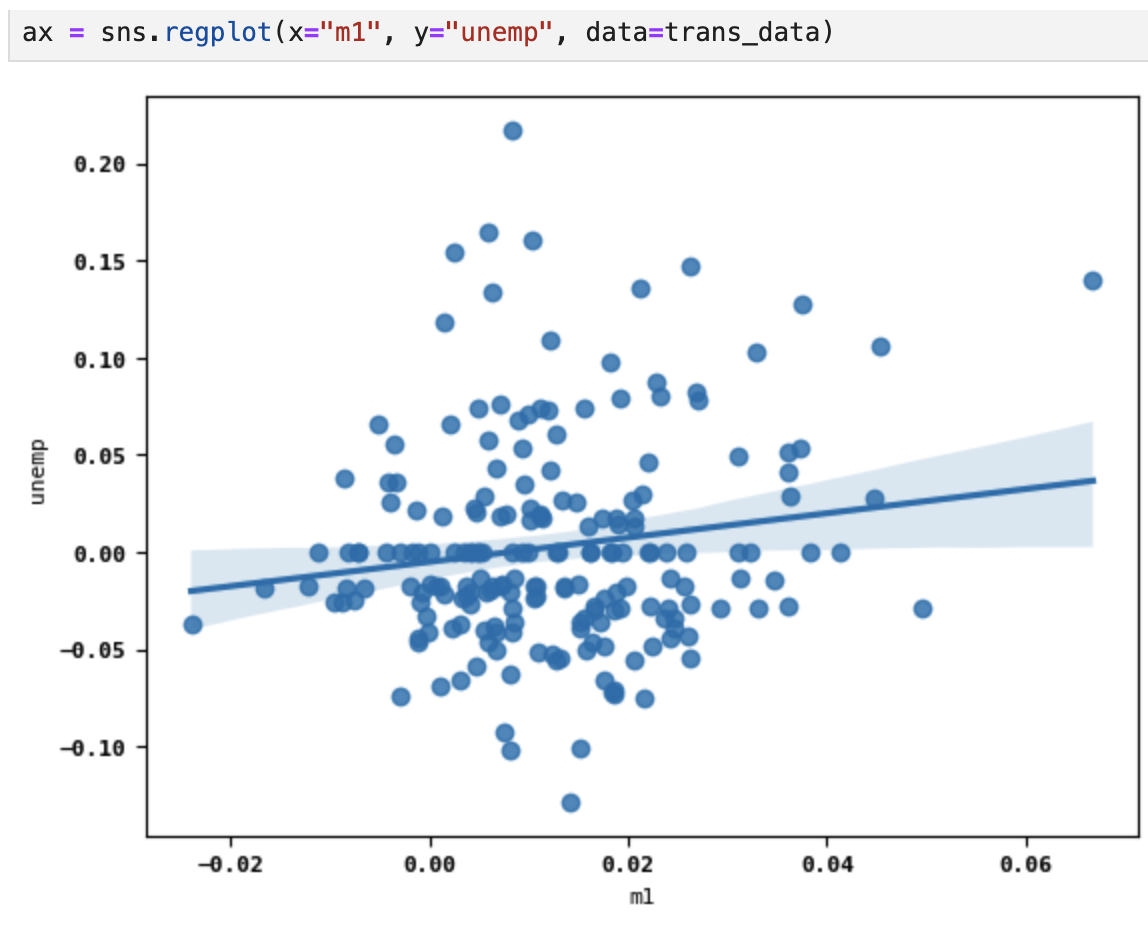
이제 시본 라이브러리의 regplot 메서드를 이용해
산포도와 선형회귀선(regression line)을 함께 그려볼 수 있다.
탐색적 데이터분석(EDA)에서는
변수그룹 간의 모든 산포도를 살펴보는 일이 매우 유용한데
이를 pairplot, 또는 산포도 행렬scatterplot matrix이라고 부른다.
이런 그래프를 직접 그리려면 다소 복잡해질 수 있으나
시본에서는 pairplot 함수를 제공한다.
이 함수를 쓰면 대각선을 따라 각 변수에 대한 히스토그램이나 밀도 그래프를 생성할 수 있다.
즉,
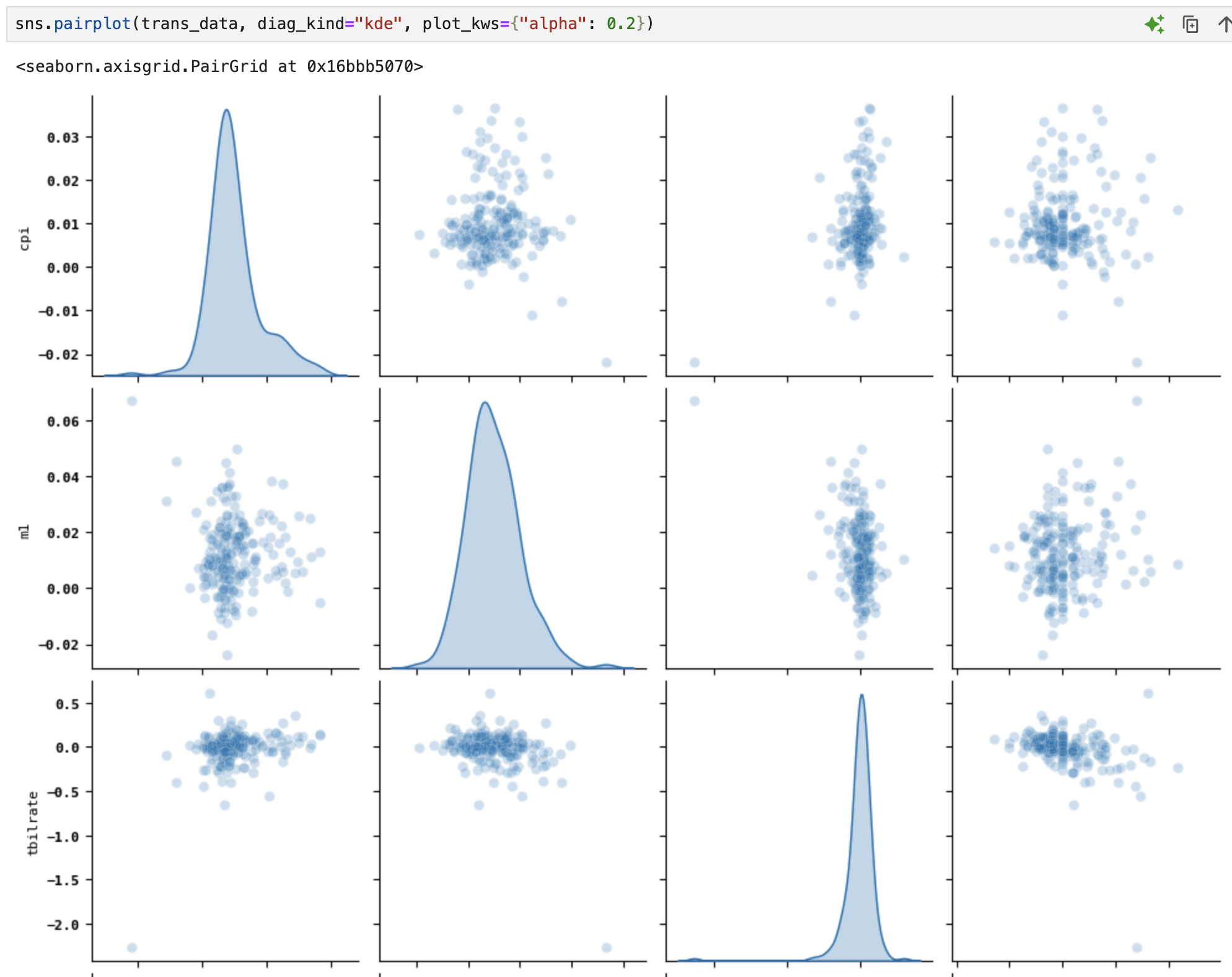
이런 형태의 그래프가 만들어진다. 코드의 요소들을 하나씩 살펴보면,
- diag_kind : 대각선(diagonal)에는 KDE(Kernel Density Estimation) 플롯을 표시한다. 기본적으로 대각선 방향에는 히스토그램이 나오지만, kde를 지정하면 저렇게 곡선의 분포가 찍힌다.
- kind : 여기서는 쓰이지 않았지만, 비대각선 방향의 그래프 모양도 지정할 수 있다. 기본적으로는 산점도가 나오는데, 다른 형태로의 변경도 가능하다.
- kind = "reg" : 선형회귀선Linear Regression Line이 추가된다.
- kind = "kde" : 등고선이 나타난다. (변수가 로그변환율이라 그런 듯)
- kind = "hex" : 육각형으로 데이터의 밀도가 표현된다. (이 예에서는 뜨지 않는다)
- kind = "scatter" : 디폴트 옵션. 산포도가 나타난다.
- plot_kws : 산점도의 속성을 설정하는 딕셔너리다. 여기서는 투명도(alpha)만 0.2로 지정했다.
- 이 외에 다른 요소들을 설정하는 방법은 공식 문서를 참고하자. 예컨대 비대각선 방향의 그래프를 한 쪽 사이드만 나오게 설정할 수도 있다. (corner=True)
이렇게 그려진 산포도 행렬을 통해
대각선 방향으로는 각각의 분포 모양(정규성, 비대칭성, 첨도 등)을 파악할 수 있고,
비대각에 대해서는 각 변수간의 상관관계를 시각적으로 탐색할 수 있게 된다.

기본기를 소홀히 하지 말자