7.2.6 이상치를 찾고 제외하기
배열 연산할 때는 이상치outlier를 제외하거나
적당한 값으로 대체하는 것이 중요하다.
예를 들어,
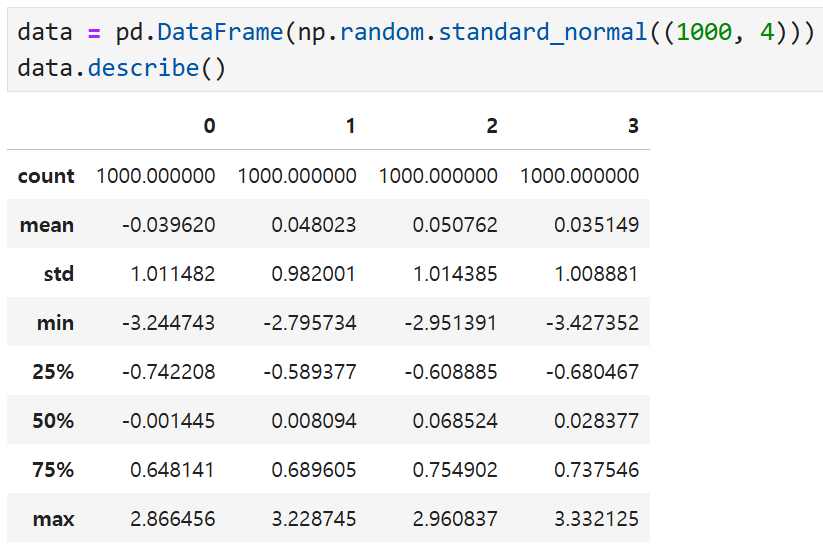
이렇게 적절히 분산된 값들로만 이루어진
데이터프레임에서도 이상치로 간주할 만한 것들이 있을 수 있다.
이 데이터프레임의 2열에서
절대값 3을 초과하는 값을 찾아내 보면

이렇게 3개가 나오는 것을 확인할 수 있다.
절대값 3을 초과하는 값이 들어있는
모든 "행"을 선택하려면 불리언 DataFrame에서
any 메서드를 사용하면 된다. 즉,
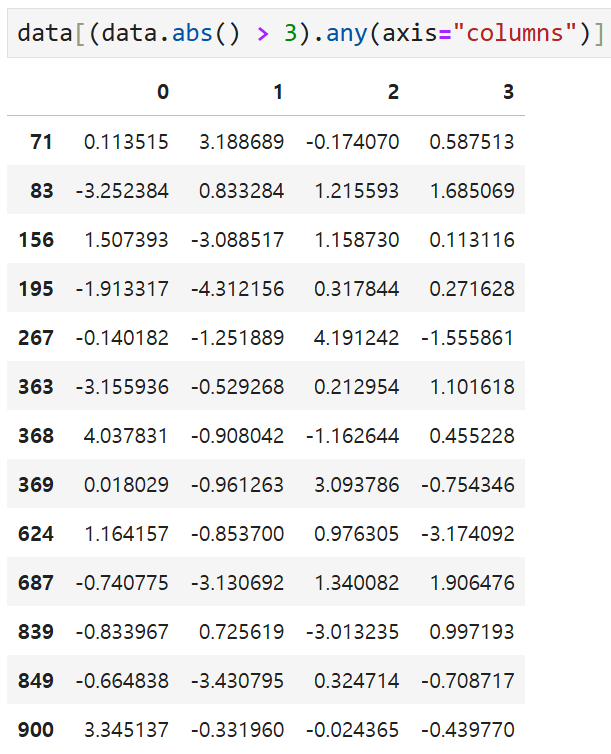
이렇게 하면 axis = "columns"에 따라
0, 1, 2, 3 열을 따라가면서 절대값이 3을 넘는 값이 있는
행들을 선택하게 된다.
※ 행을 선택하는 데 axis="columns"라고 쓰는 게
직관적으로 외우기 어렵지만 익숙해져야 한다.
any 메서드를 쓰려면
data.abs()>3 이 부분을 소괄호로 감싸야 한다.
그리고 절대값이 3이 넘는 값들을
이상치outlier로 판단하게 되면,
아래 코드를 써서 -3이나 3을 초과하는 값들을
-3 또는 3으로 지정할 수 있다.
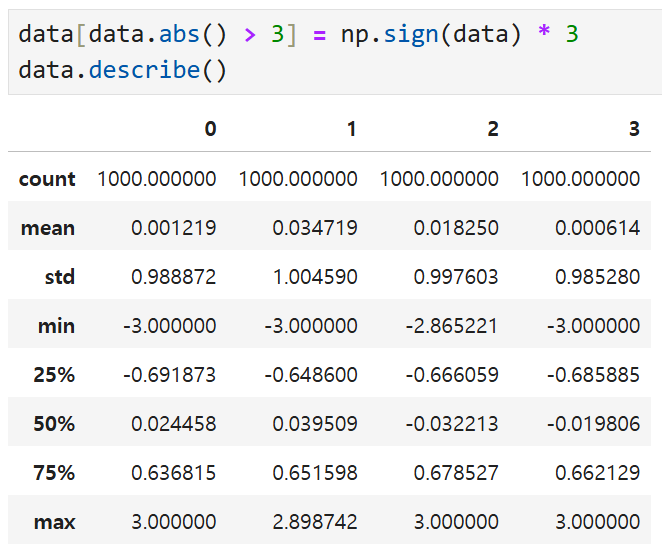
np.sign은 해당 값들의 부호를
-1, 또는 1의 형태로 반환하는데, 여기에 다시 3을 곱하게 되므로
자동적으로 -3이나 3을 초과하는 값들이 -3이나 3으로
고정되게 되는 것.
여기서의 np.sign(data)만 떼어 놓고 보면
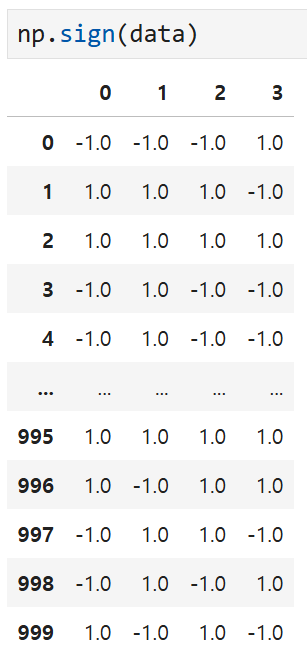
이렇게 실제 값들이 아니라
각 값들의 부호만 양수/음수인지를 -1, 1로 나타내고 있다.
그 동안은 이상치를 처리하는 방식으로
아예 제외해 버리는 것밖에 쓰지 않았던 것 같은데,
(전체 데이터의 몇 %를 차지하는지 정도만 고려해서)
이렇게 다루는 방법도 있다는 건 처음 알았다.
이상치로 판별된 데이터를 아예 버리는 것과
위에서 본 예처럼 일정 정도의 범위로 값을 제한하는 것에는
각각의 장단점이 있을 텐데,
결론적으로는 어떤 방법이 더 우월하냐의 문제는 아니고
분석의 맥락과 데이터의 특성을 고려해 결정하기 나름의 문제인 듯.
