7.2.7 뒤섞기와 임의 샘플링
numpy의 random.permutation 함수를 사용하면
Series나 DataFrame의 행이나 열을 임의의 순서대로
재배치할 수 있다. 순서를 바꾸고 싶은 만큼의 길이를
permutation함수에 전달하면 되는데, 예를 들어
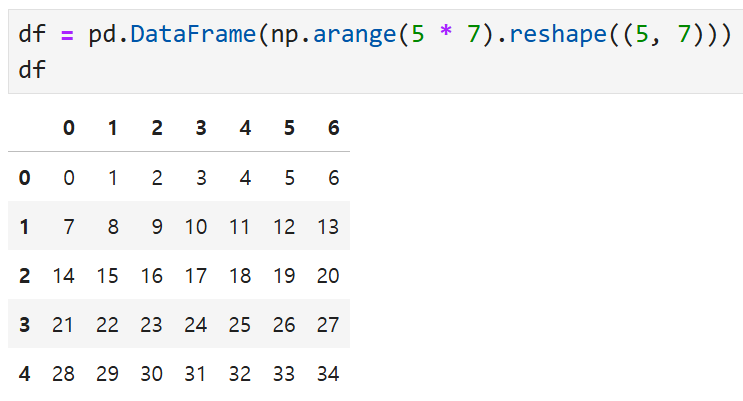
이렇게 생긴 데이터프레임이 있다고 하자.
여기서

이렇게 sampler를 만들어 주면
random.permutation에 따라 5개의 행 인덱스가
무작위로 다시 배열된다.
그리고 이 배열을 iloc 기반의 색인이나
take 함수에서도 사용할 수 있다. 즉,

sampler에서 나온 결과에 따라
df의 행 인덱스 순서가 1,3,0,2,4로 바뀐 것을 확인할 수 있다.

이렇게 코드를 실행해도 결과는 같다.
iloc는 정수 기반 인덱싱이 가능하기 때문에
보통 슬라이싱에 많이 썼지만,
이처럼 리스트나 배열을 이용한 특정 행 선택도 가능하다.
다른 메서드나 함수를 쓸 때와 마찬가지로,
take를 호출할 때 axis=1을 넘기면 열에 대해 작동한다. 즉,
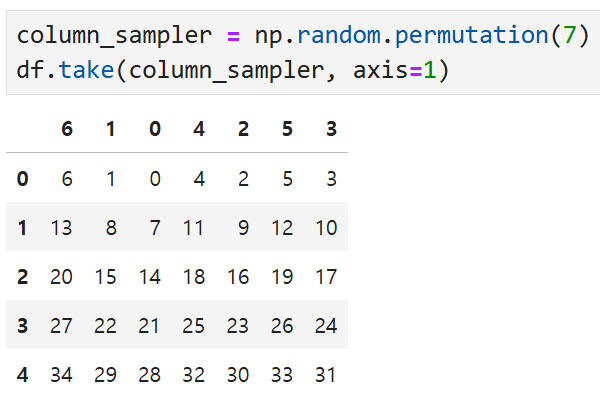
이번에는 행의 순서는 그대로 두고
열의 순서만 무작위로 재배열 된 다음
df에 그 결과(column_sampler)를 적용한 버전이다.
다만, 여기서 iloc를 사용하려면
iloc와 loc를 다룬 예전 포스팅에서도 알아봤듯이
'모든 행을 선택한다'라는 명령이 먼저 들어가야 한다.
(loc와 iloc는 모두 행 단위를 기준으로 작동하므로)
따라서,

이렇게 써 주면 문제가 없다.
지금까지 알아본 것은
원본 데이터의 행과 열을 랜덤으로 치환하는 작업이었는데,
만약 치환 없이 일부만 임의로 선택하려면
(기본적으로 sample의 결과는 비복원추출이므로 같은 행이나 열이 두 번 나타날 수 없다)
Series나 DataFrame의 sample 메서드를 이용한다.
예를 들어,
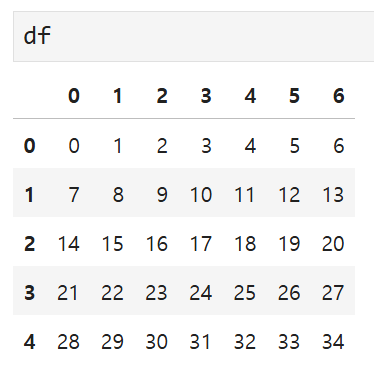
위의 예시에서 보았던 df가 똑같이 있을 때

이렇게 sample의 크기를 지정하면
5개의 행 중 무작위로 3개를 골라서 결과를 반환한다.
그리고 이 결과는 코드를 실행할 때마다 달라진다.
여기서 반복 선택을 허용하기 위해
(즉 복원추출로 변경하기 위해)
replace라는 인자를 넣어서 제어해 줄 수 있다. 예를 들어,

이렇게 코드를 짜면
10개의 데이터를 복원추출로 뽑아준다.
그렇다면 위의 df, 즉 DataFrame에서
복원추출로 행이나 열을 무작위로 뽑으려면 어떻게 할까?
다시 df의 예를 보자.

여기서 5개의 행을 임의로 뒤섞을 건데,
중복되는 경우도 있을 수 있다고 치자.
즉, 복원추출을 허용해서 5개를 뒤섞는 방식이다.
이럴 경우의 코드는

이렇게 짜면 된다.
Series에서와는 다르게, DataFrame에서는
sampler2를 만들 때 인자가 추가된다.
- 최초의 5는 데이터프레임의 행의 갯수다.
- size = 5는 선택할 행의 갯수가 된다. 즉, 모집단 0,1,2,3,4로부터 몇 개의 값을 뽑을 것인가? 가 된다.
- 복원추출을 허용해야 하니 replace=True로 써야 한다.

만약 size를 3으로 바꾸면 0에서 4까지의 5개 숫자 중
무작위로 3개의 숫자가 반환되고, replace=True이므로
복원추출이 허용된다.
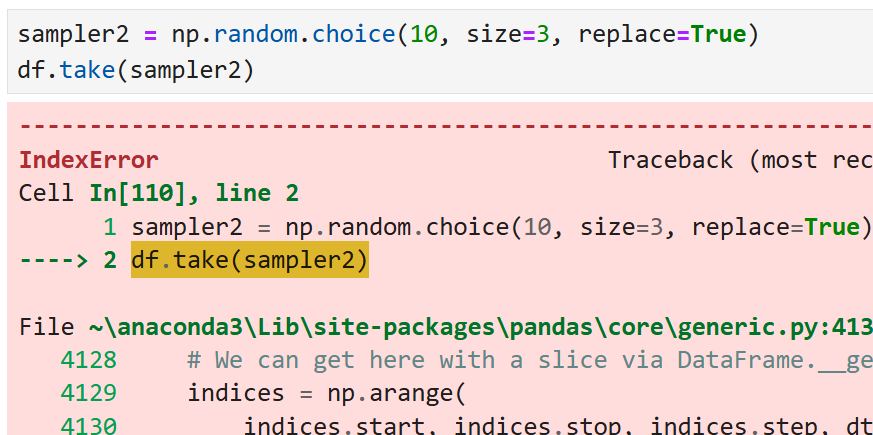
데이터프레임의 행의 갯수보다 최초 인자를 더 크게 넣으면
사이즈가 맞지 않는다는 오류가 난다.
즉, 뒤섞으려는 원본 데이터프레임의 행(또는 열) 수는
똑같이 맞춰줘야 한다.
