중복 색인
판다스의 많은 함수들에서 인덱스 값은 유일해야 하지만
이 조건이 반드시 지켜져야 하는 것은 아니다.
(즉, 중복되는 인덱스 값이 있을 수도 있단 얘기)
예를 들어,
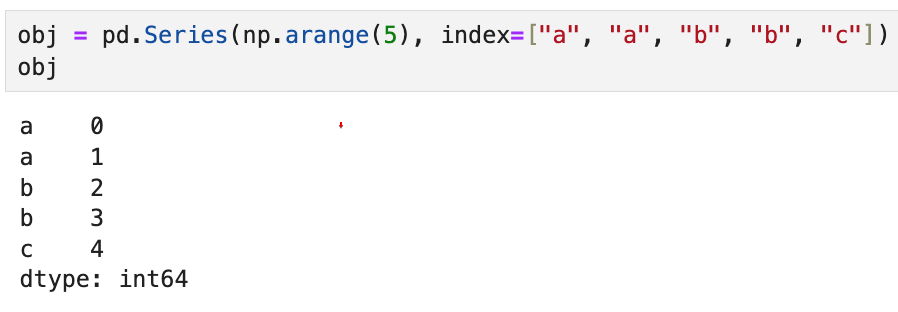
이렇게 생긴 Series가 있다고 하자.
index 객체의 is_unique 속성은 해당 값의 중복 여부를 알려준다.
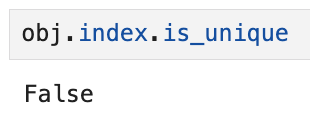
이렇게 is_unique로 검사하면 False가 나온다.
즉, index중에 고유하지 않은 중복값이 있다는 뜻이다.
만약 인덱스에 중복된 값이 있다면
인덱스를 이용해 데이터를 선택하는 것도 다르게 작동한다.
인덱스가 고유한 값이라면 스칼라를 반환하고,
중복되는 값이라면 Series 객체를 반환하는 식이다.
위의 예를 이어서 보면


인덱스 a에 해당하는 데이터를 불러온 결과
Series 객체가 반환된 것을 볼 수 있다.

반면 인덱스가 고유한 값일 경우 하나의 스칼라 값이 반환된다.
한편 DataFrame에서는 행이나 열을 선택하는 것도 동일하다.
예를 들어
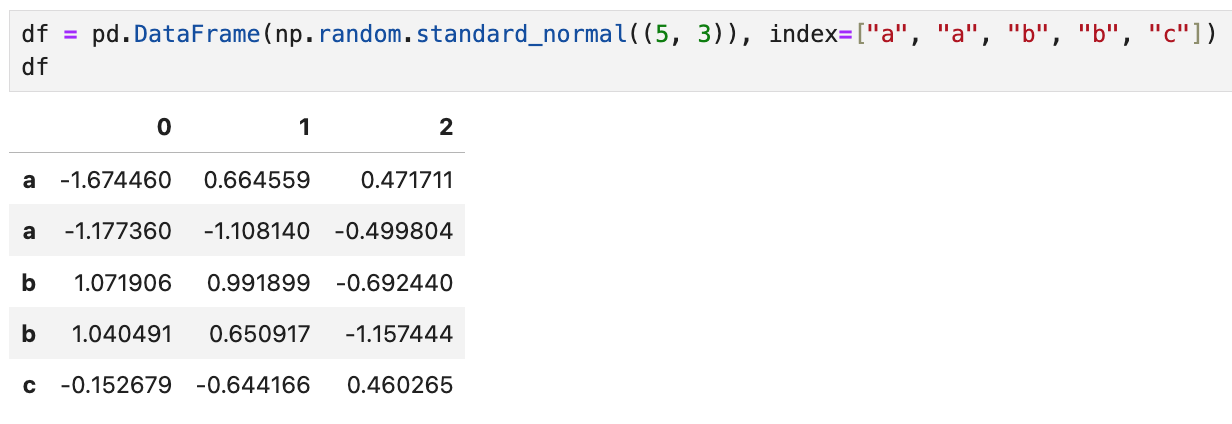
이렇게 생긴 데이터프레임이 있다고 했을 때,

중복되는 인덱스 b에 해당하는 데이터들이 모두 불러와지고,
df.loc["b"]의 결과도 데이터프레임이 된다.
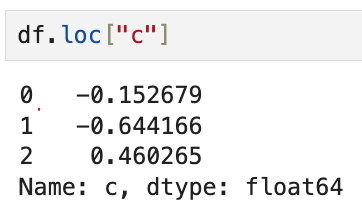
반면 고유한 인덱스 값인 c에 해당하는 데이터를 불러오면
열을 새로운 인덱스로 하는 Series 형태로 결과가 반환된다.
이렇게 보는 게 불편해서 위의 데이터프레임처럼 보이는 결과를 얻고 싶으면
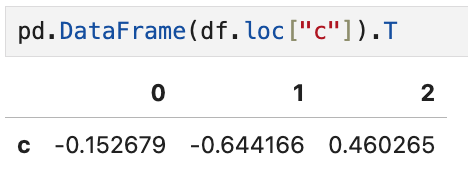
이렇게 하면 된다.

기본기를 소홀히 하지 말자