정렬과 순위
정렬
sort_index
Series의 경우
sort_index 메서드를 사용하면
행과 열의 인덱스를 알파벳 순으로 정렬할 수 있다. 예를 들어
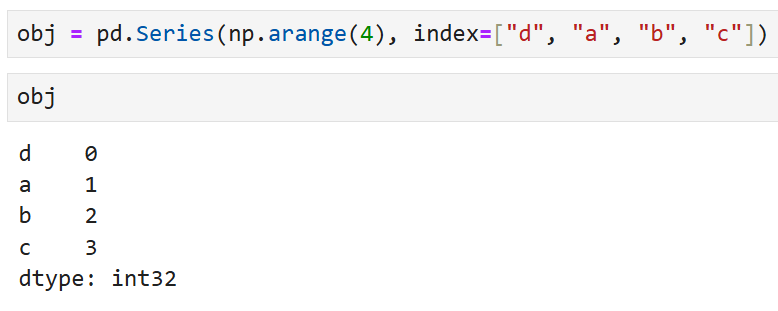
이렇게 생긴 Series가 있다고 했을 때,

sort_index를 쓰면 알파벳 순으로 인덱스가 정렬된다.
DataFrame의 경우
데이터프레임에서는 행과 열 중 하나의 인덱스를
기준으로 잡아서 정렬할 수 있다. 예를 들어,

이렇게 생긴 데이터프레임이 있을 때,
그냥 sort_index()를 적용하면
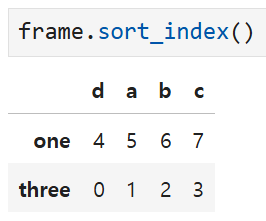
디폴트는 행 기준으로 오름차순 정렬이다.
만약 열 기준으로 정렬하고 싶다면
axis 인자에 값을 넣어서 지정해 주면 된다.
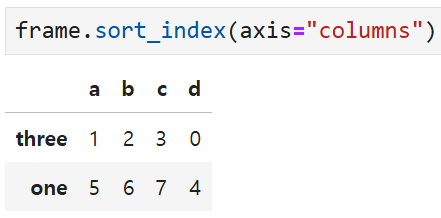
한편 내림차순으로 정렬하고 싶으면
axis 외에 ascending 인자를 추가로 넣어주면 된다.
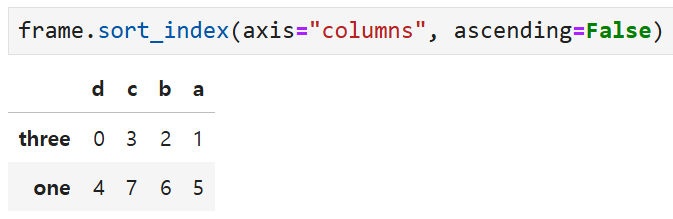
위의 코드에 ascending = False를 추가해 주면
d, c, b, a 순으로 내림차순 정렬된다.
※ False 쓸 때 대소문자 구분 주의
sort_value
sort_index는 행이나 열의 인덱스에 따라 정렬해주는 메서드고,
값에 따라 정렬하고 싶으면 sort_value 메서드를 쓰면 된다.
Series의 경우
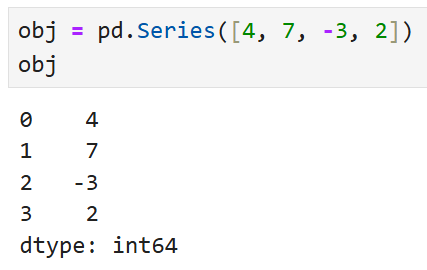
예컨대 이렇게 생긴 Series 객체가 있다고 했을 때,
(인덱스는 지정하지 않았기 때문에 자동으로 숫자로 붙음)
이 Series를 값의 대소에 따라 오름차순/내림차순으로
정렬하고 싶다면
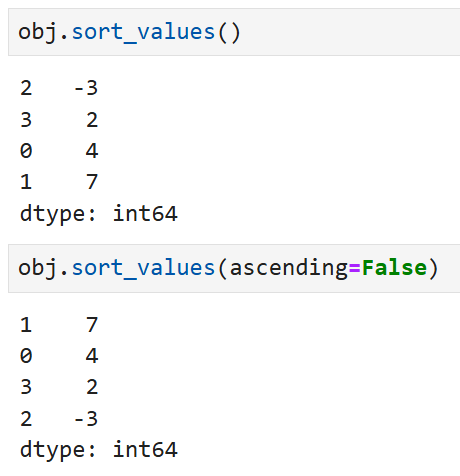
이렇게 쓸 수 있다.
sort_index()와 동일하게 ascending을 써서
오름차순/내림차순 여부를 조절할 수 있다 (디폴트는 오름차순)
만약 객체 안에 결측치가 섞여있다면
정렬할 때 가장 마지막에 위치하게 된다. 예를 들어,

이렇게 생긴 Series가 있다고 했을 때
sort_value()를 써서 정렬하면
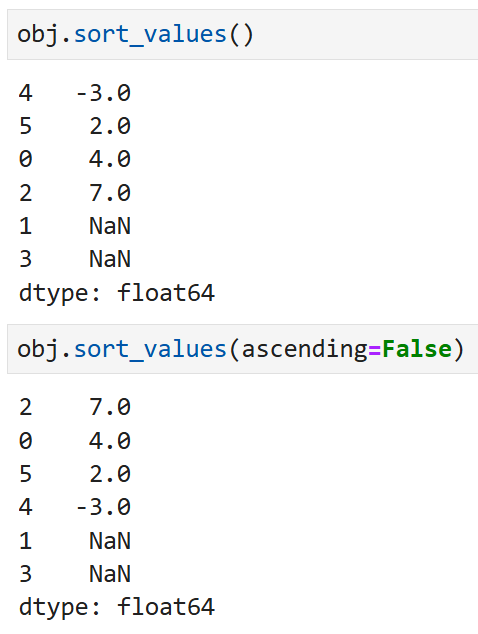
오름차순/내림차순 여부에 관계없이
결측치는 정렬의 영향을 받지 않고 제일 마지막에 위치한다.
이 때 결측치를 마지막이 아니라 제일 먼저 정렬할 수도 있는데,
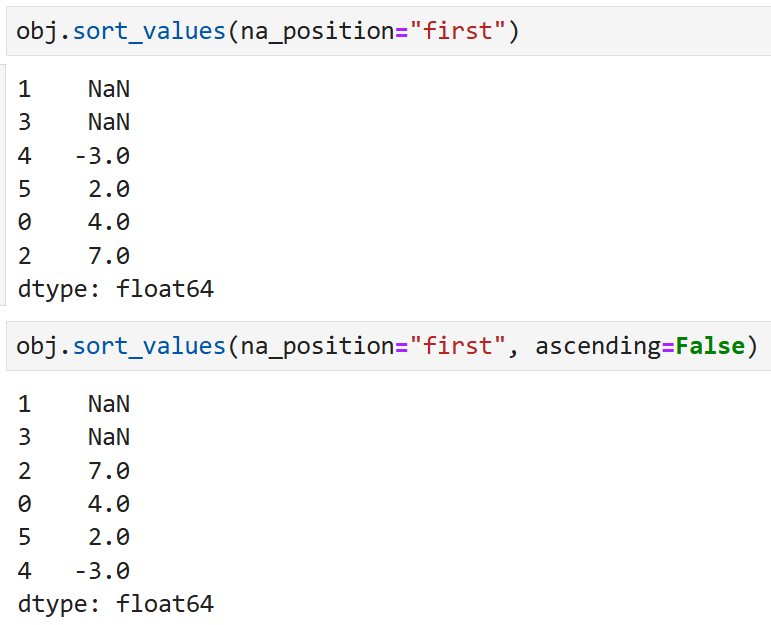
na_position을 써서 first로 자리를 지정해 주면
오름차순/내림차순의 여부와 관계없이
결측치가 가장 먼저 오고 그 뒤에 값들이 정렬된다.
DataFrame의 경우
데이터프레임에서 하나 이상의 열에 있는 값으로 정렬할 경우
sort_value의 인자로 열의 이름을 넘기면 된다. 예를 들어,
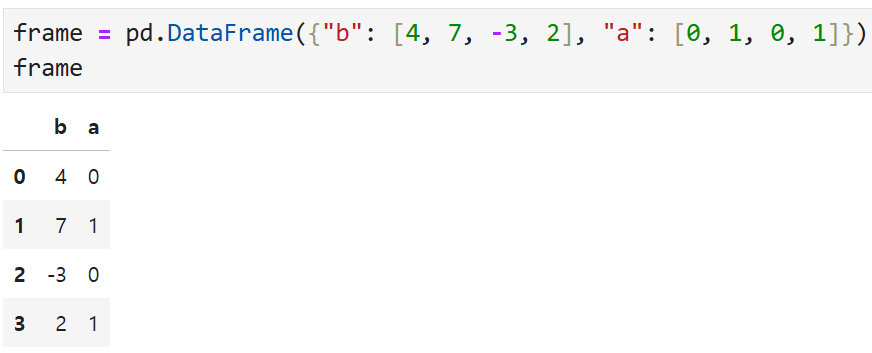
이렇게 생긴 데이터프레임이 있다고 했을 때,
만약 b열의 값을 기준으로 오름차순/내림차순 정렬하려면
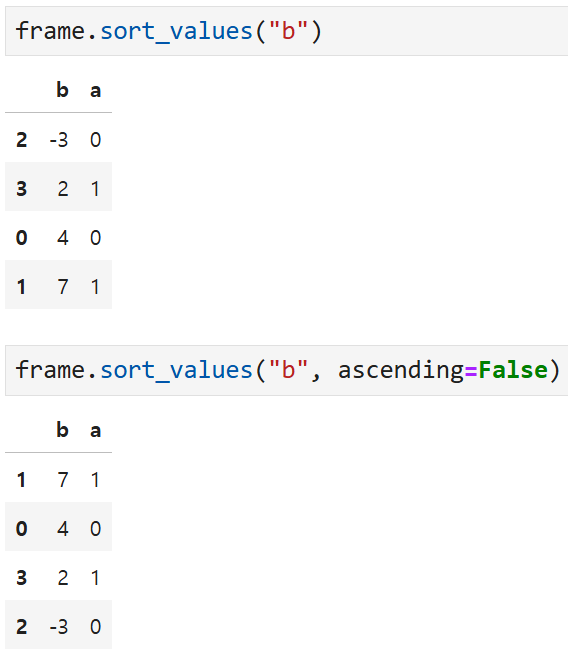
이렇게 열 이름 "b"를 바로 넣어주면 된다.
만약 여러 개의 열 기준으로 정렬하려면
열 이름들을 리스트 형태로 만들어서 전달하면 되는데,
이 때 정렬이 적용되는 기준은 마치 SQL의 order by와 같아서
앞에 있는 열을 기준으로 먼저 정렬하고
그 뒤에 뒤에 있는 열을 기준으로 정렬하게 된다.
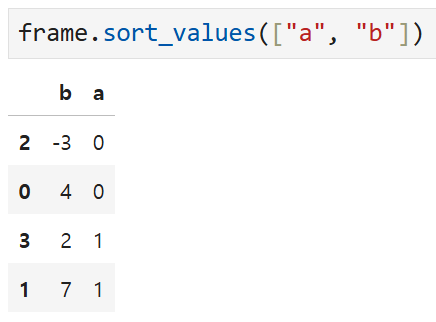
a를 기준으로 오름차순 정렬되고 (0과 1 순으로)
그 뒤에 0을 기준으로 -3, 4로 오름차순 정렬,
1을 기준으로 2,7로 오름차순 정렬됨을 확인할 수 있다.
즉, order by a asc, b asc와 동일하게 작동한다.

리스트로 전달하는 열의 순서를 바꿔서
b를 먼저 전달하면 b를 기준으로 오름차순 정렬이 먼저 되고
그 뒤에 a가 오는 것을 확인할 수 있다.
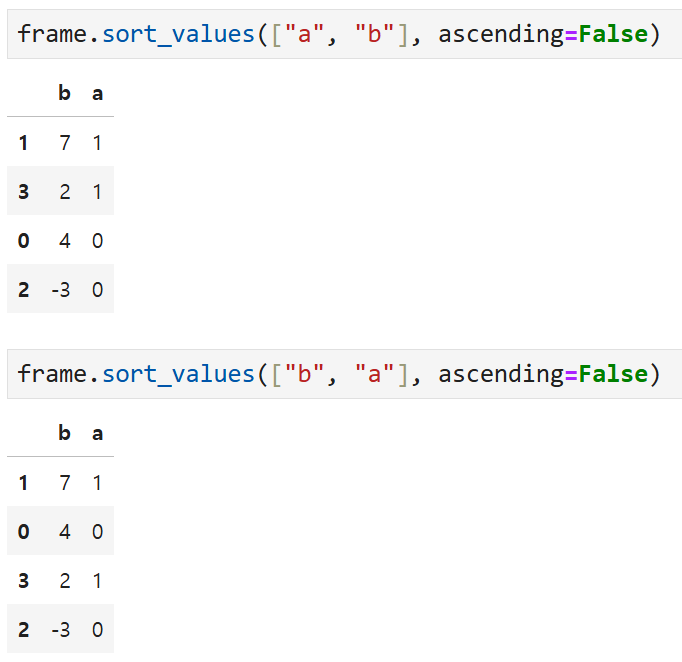
만약 위의 결과에서 ascending = False를 넣어서
내림차순으로 정렬하게 되면
a 기준으로 먼저 내림차순 정렬되고
그 이후 a의 값이 동일하다면 b 기준으로 내림차순 정렬된다.
위의 예에서는 b가 모두 고윳값을 갖고 있으므로
a의 정렬에 영향을 주지 않기 때문에
마치 a가 그냥 b에 딸려오는 것처럼 보일 수 있지만,
ascending의 기준은 리스트로 전달하는 열에
순차적으로, 모두 적용된다.
순위
순위는 가장 낮은 값부터 시작해
유효한 데이터 개수까지의 순서를 매겨준다.
rank 메서드는 Series든 DataFrame이든
동점인 항목에는 평균 순위를 매겨서 책정한다.
예를 들어,
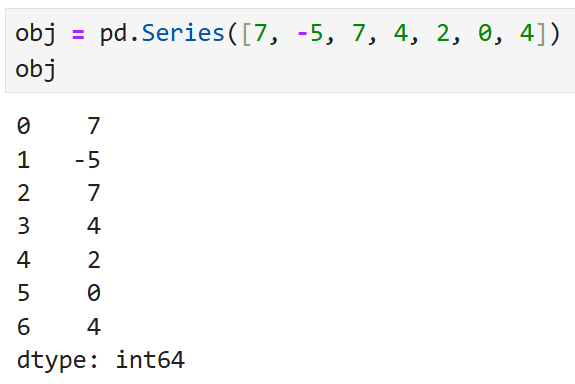
이렇게 생긴 Series가 있다고 했을 때
rank를 적용하면

이렇게 된다.
오름차순이 기본이므로
- 가장 작은 값이었던 -5가 1위,
- 0이 2위
- 2가 3위
- 그리고 그 다음 값인 4는 2개이므로 4위와 5위의 평균값인 4.5위,
- 4 다음 값인 7도 2개이므로 6위와 7위의 평균값인 6.5위
이렇게 되는 식이다.
다만 '순위의 평균'이라는 게 직관적으로 이해하기 쉽진 않은데,
같은 값이더라도 데이터상에 빨리 나타나는 쪽에게
높은 순위를 부여해주는 방법도 있다.

이렇게 method = "first"로 표기해 주면
1, 2, 3위까지는 동일하고 먼저 나온 행 인덱스 3의 4가 4위,
나중에 나온 행 인덱스 6의 4가 5위로 매겨진다. 7도 마찬가지.
순위의 동률을 처리하는 method에 들어갈 수 있는 값은
first를 포함하여
- average : 디폴트. 같은 값은 평균 순위를 낸다.
- min : 같은 값을 갖는 그룹을 낮은 순위로 매김
- 이 메서드를 쓰면 1~3위까지는 동일하고
- 4가 공동 4위, 7이 공동 6위가 됨
- max : 같은 값을 갖는 그룹을 높은 순위로 매김
- 이 메서드를 쓰면 1~3위까지는 동일하고
- 4가 공동 5위, 7이 공동 7위가 됨
- first : 위의 예에서 본 대로 같은 값이면 먼저 나온 쪽이 높은 순위를 부여받게 됨
- dense : SQL에서 dense_rank를 쓸 때와 비슷함. 공동 순위는 인정하지만 건너뛰지 않고 1씩 증가시킴.
- 즉, 4가 공동 4위, 7이 공동 5위가 됨.
이런 종류들이 있다.
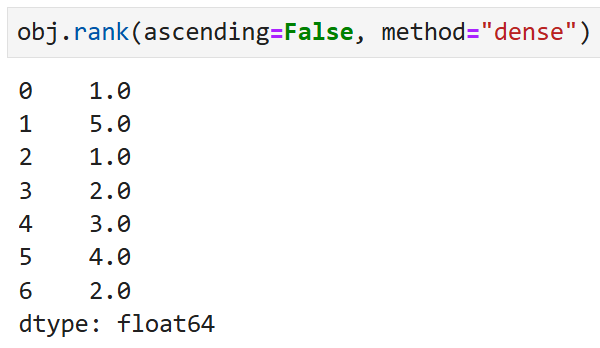
이런 식으로 ascending을 써서
오름차순/내림차순을 정렬하는 것은 정렬할 때와 똑같다.
DataFrame에서는 행과 열에 대해 순위를 정할 수 있다.
예를 들어,
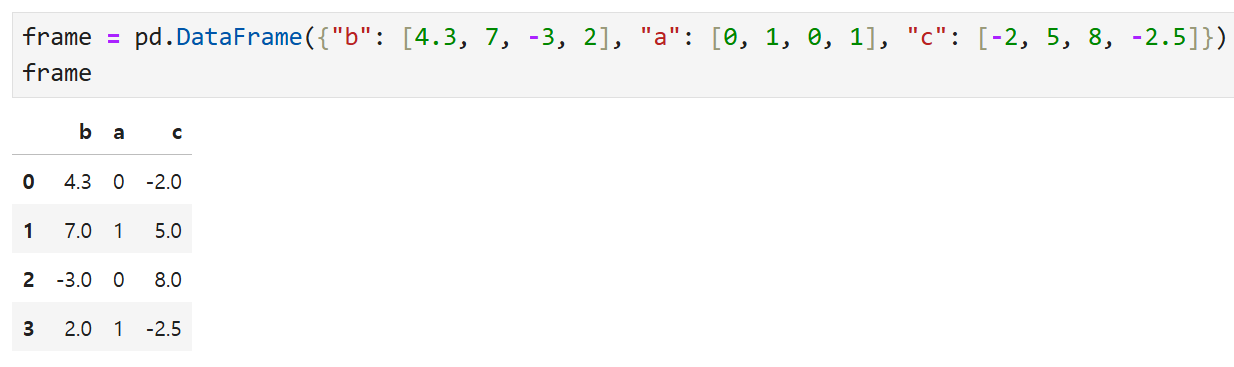
이렇게 생긴 데이터프레임이 있다고 했을 때
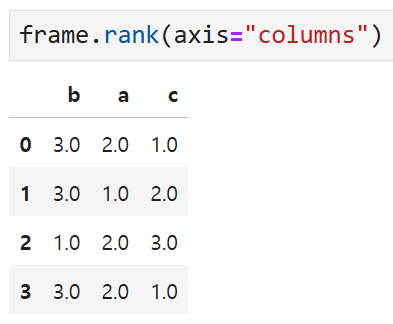
axis="columns"로 설정해서 순위를 매기면
각 행을 기준으로, 열끼리의 순위가 매겨지게 된다.
즉, 0번째 행을 기준으로 b, a, c의 순서를 매기기 때문에
-2인 c가 1순위, 0인 a가 2순위, 4.3인 b가 3순위가 되는 것.
★columns를 쓰면 행을 고정하고 열 단위로 순위 계산!
반대로 열을 고정하고 행 단위로 순위를 매기려면

이렇게 하면 된다.
b열과 c열에는 겹치는 값이 없기 때문에
1위부터 4위까지의 순서가 값의 오름차순에 의해 나왔고
a열에는 0과 1이 겹치기 때문에 1위와 2위의 평균인 1.5위,
3위와 4위의 평균인 3.5위가 각각 2개씩 나온 것.
여기서 a열의 순위가 직관적이지 않아서 불편하다면
위에서 언급한 method 중 하나를 써 주면 된다.
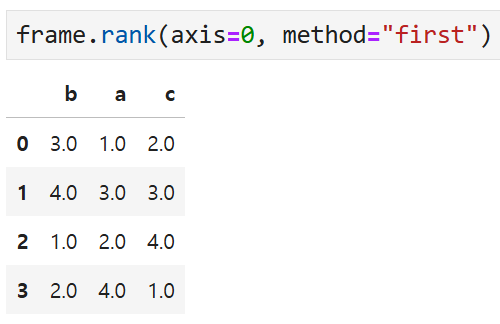
예를 들어 method를 first로 넣어주면
등장한 순서에 따라 순서가 들어가기 때문에
a열에서도 값은 겹칠지라도 순서는 겹치지 않게 된다.
참고로 axis = 0으로 쓰나 axis = "index"로 쓰나 결과는 같다.
axis = "columns"와 axis = 1도 마찬가지.
