0. 들어가며
Machine Learning이란
인간이 개발한 알고리즘을 컴퓨터 언어를 통해서 기계에게 학습하는 행위
아래 이미지는 시간이 지날수록 구글에서 어떤 키워드가 가장 많이 검색되고 있는지를 보여준다.
보이는 것과 같이 Machine Learning 이란 키워드는 시간이 지날수록 다른 키워드들에 비하여 압도적으로 검색량이 늘어남을 알 수 있다.
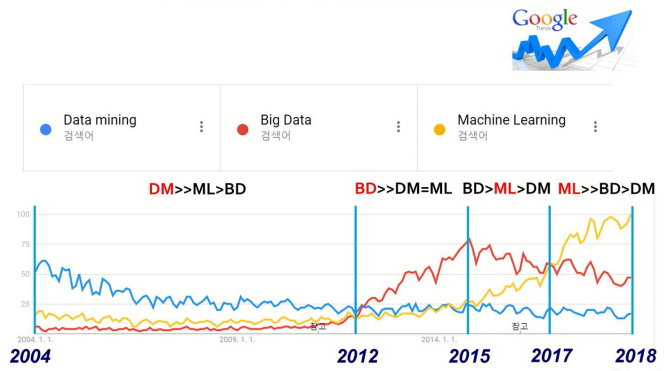
한 장의 이미지만으로도 Machine Learning 의 중요성을 확실히 느낄 수 있다.
1. 데이터 구조
기본적으로 Machine Learning 이나 Deep Learning 은 주어진 데이터를 분석하여 새로운 결과물을 예측하는 과정을 목표로 한다.
따라서 Machine Learning 을 공부하기 위해서는 기본적인 데이터의 구조를 알아야 한다.
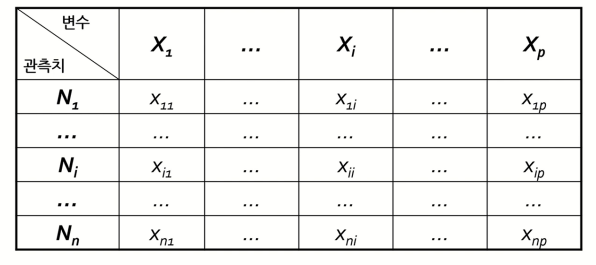
기본적으로 데이터는 위와 같은 2x2 행렬로 이루어지고 각각 관측치와 변수로 구성된다.
- 관측치 : Sample(고객, 제품, 청구건, 환자 등)
- 변수: 각 Sample의 특성치(Feature라고도 불리운다)
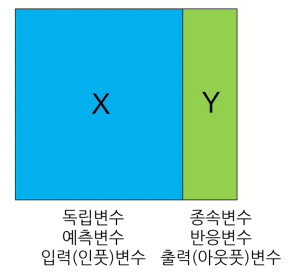
변수는 다시 X와 Y로 나뉘어지는데 다음과 같이 불리운다.
- X : 독립변수, 예측변수, 입력변수
- Y : 종속변수, 반응변수, 출력변수
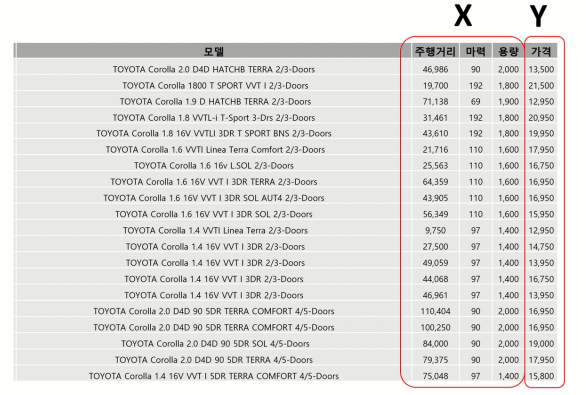
위 사진은 중고차 데이터의 일부이고, 보이는 것처럼 주행거리, 마력, 용량은 X, 가격은 Y로 나타낼 수 있다.
2. 머신러닝 모델링
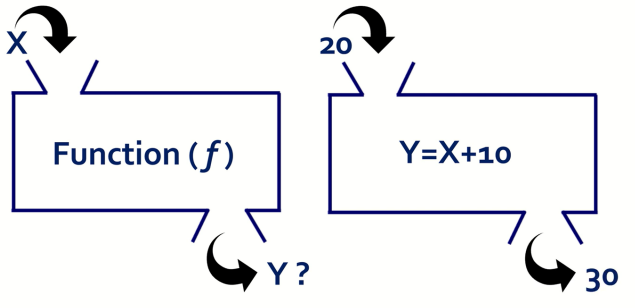
일반적으로 우리는 주어진 입력 X와 함수 F(x)를 이용하여 출력 Y를 얻는 과정을 거친다.
이는 X값과 F(x)만 주어진다면 결과를 알 수 있다는 뜻이다.
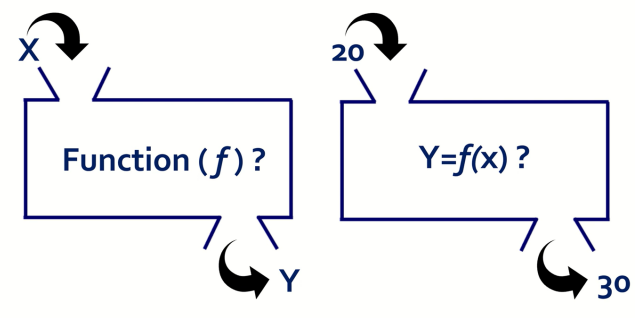
반대로 Machine Learning 은 주어진 입력 X와 출력 Y를 이용하여 함수 F(x)를 얻는 과정을 거친다.
cf.
Machine Learning에서는 함수 F(x)를 모델이라고 부른다.
따라서 X와 Y값을 많이 알면 알 수록 보다 정교하게 모델 F(x)를 찾을 수 있다.
이는 X와 Y 데이터가 많을 수록 Machine Learning Model 을 정확하게 만들 수 있다는 뜻이다.
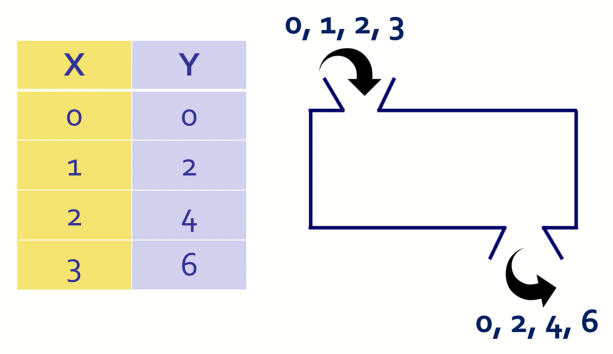
X와 Y가 다음과 같이 주어졌을 때 함수 F(x)를 구한다면
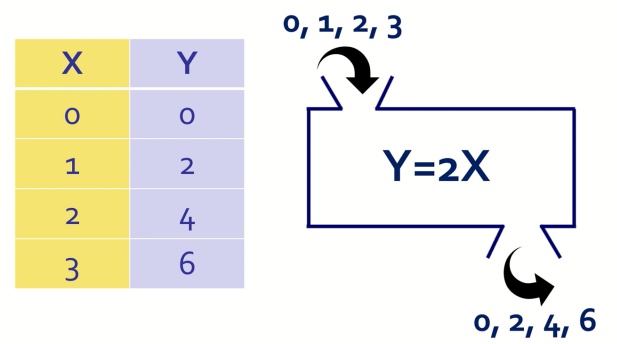
F(x) => Y=2X 와 같은 형태일 것이다.
3. 학습 데이터, 검증 데이터
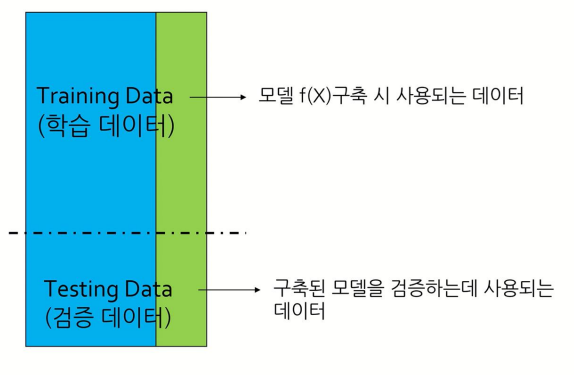
데이터는 Training Data 와 Testing Data 로 나눌 수 있다.
- Training Data : 모델 F(x)를 학습시키기 위한 데이터
- Testing Data : Training Data를 이용해서 구축한 모델 F(x)가 제대로 만들어졌는지 검증하기 위해 사용되는 데이터
4. 모델 F(x)의 종류
Machine Learning 에서 사용하는 모델은 Linear Regression, Logistic Regression, Random Forest 등 무수히 많다.
5. 마치며
오늘은 Machine Learning 을 들어가기에 앞서 기본적인 내용들을 간단하게 알아보았다.
다음은 Machine Learning 으로 예측해야 할 Y값의 종류에 따라 달라지는 예측 방법에 대하여 포스팅 할 예정이다.
또한 필자는 고려대학교 김성범 교수님이 운영하시는 유튜브 채널을 보고 공부한 내용을 포스팅 하였으므로 아래 출처를 남긴다.
https://www.youtube.com/@user-yu5qs4ct2b
