SQL은 데이터를 추출하는 것, 파이썬은
주피터 노트북을 이용해 데이터를 직접 표로 그릴 것이다!(언젠가는,,,)
PowerShell을 이용해서 주피터 노트북을 설치하면 웹에서 이용할 수 있다.
가장 기본이 되는, 필요한 패키지 설치하기
pip install을 이용하여 패키지를 먼저 설치한다.
pip install pandas
pip install numpy
pip install matplotlib
으로 설치!
time함수도 쓸거라 설치했는데 에러가 떴다..
time, math, random과 같은 내장함수는 기본모듈로 원래 내장되어 있기 때문에 설치하지 않고 import로 바로 불러서 쓴다!

불러오기 실패
파이썬에서 쓸 수 있는 불러오기는 다음 둘 중에 하나여야 한다.
import A as B -> 주로 사용
from A import B
import pandas as pd # pandas는 pd로 줄여 사용
import numpy as np
import time
import matplotlib.pyplot as plt또는
import pandas as pd
import numpy as np
import time
from matplotlib import pyplot as plt을 사용하기!
다음은 리스트와 딕셔너리 형식으로 된 데이터를 표로 만들어내는 작업
1. 리스트 형식
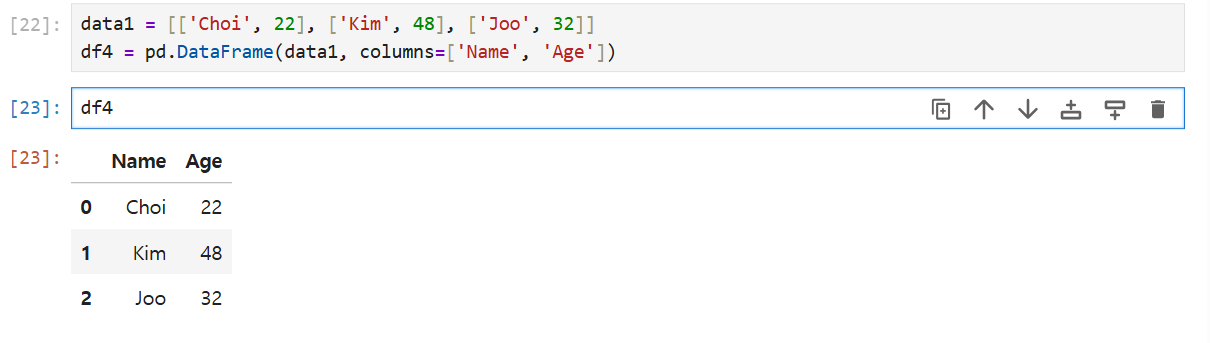
data1 = [['Choi', 22], ['Kim', 48], ['Joo', 32]]
df4 = pd.DataFrame(data1, columns=['Name', 'Age'])data1은 세 개의 리스트로 구성되어 있고, 각 리스트는 두 개의 속성을 가진다.
pd의 DataFrame이라는 함수를 이용할건데 data1을 불러올거고, 각 컬럼의 이름은 'Name', 'Age'로 할거다.
이 표의 이름을 df4라고 하겠다. 라고 입력한 후
df4를 불러오면 Name과 Age로 구성된 표를 출력한다.
- 딕셔너리 형식
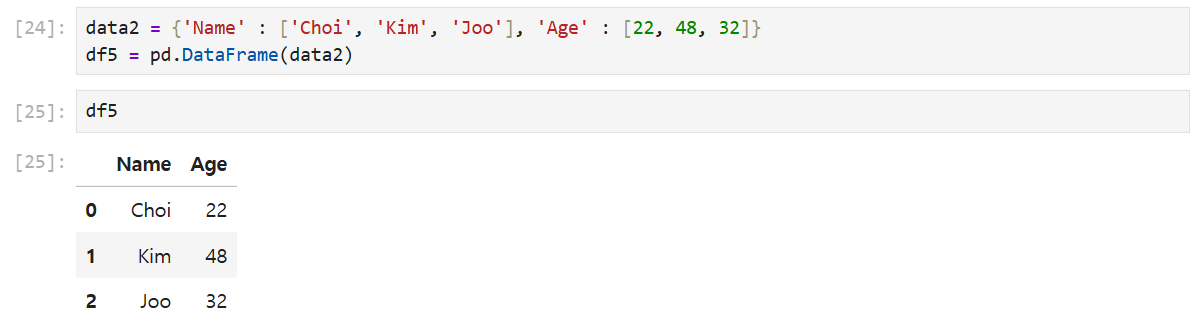
data2 = {'Name' : ['Choi', 'Kim', 'Joo'], 'Age' : [22, 48, 32]}
df5 = pd.DataFrame(data2)data2는 인덱스 'Name'인 것의 값들이 'Choi', 'Kim', 'Joo'이고 'Age'인 것의 값들이 22, 48, 32이다.
딕셔너리 형식은 이미 인덱스 이름이 지정되어 있기 때문에 ()안에 불러올 데이터만 넣어주면 된다.
Jupyter Notebook Home에 업로드한 cvs 파일을 불러올 수 있다.
내장함수 display를 쓰면 여러 파일을 한 번에 불러올 수 있다.
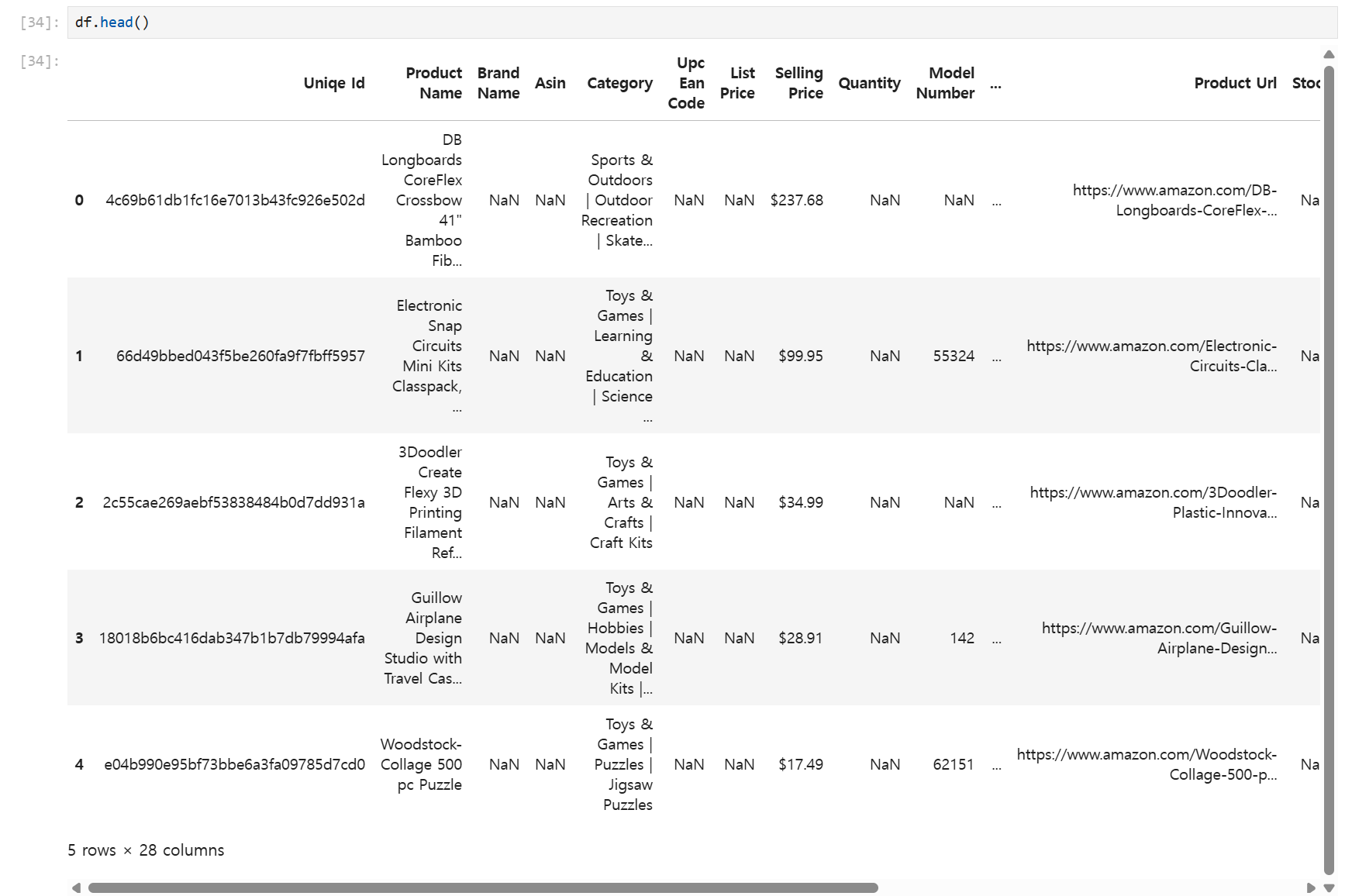
테이블을 일부만 보고 싶을 땐 head나 tail을 이용한다.
df.head()제일 위부터 ()에 입력받은 수만큼 행을 출력한다.
없다면 기본 값인 5행을 출력
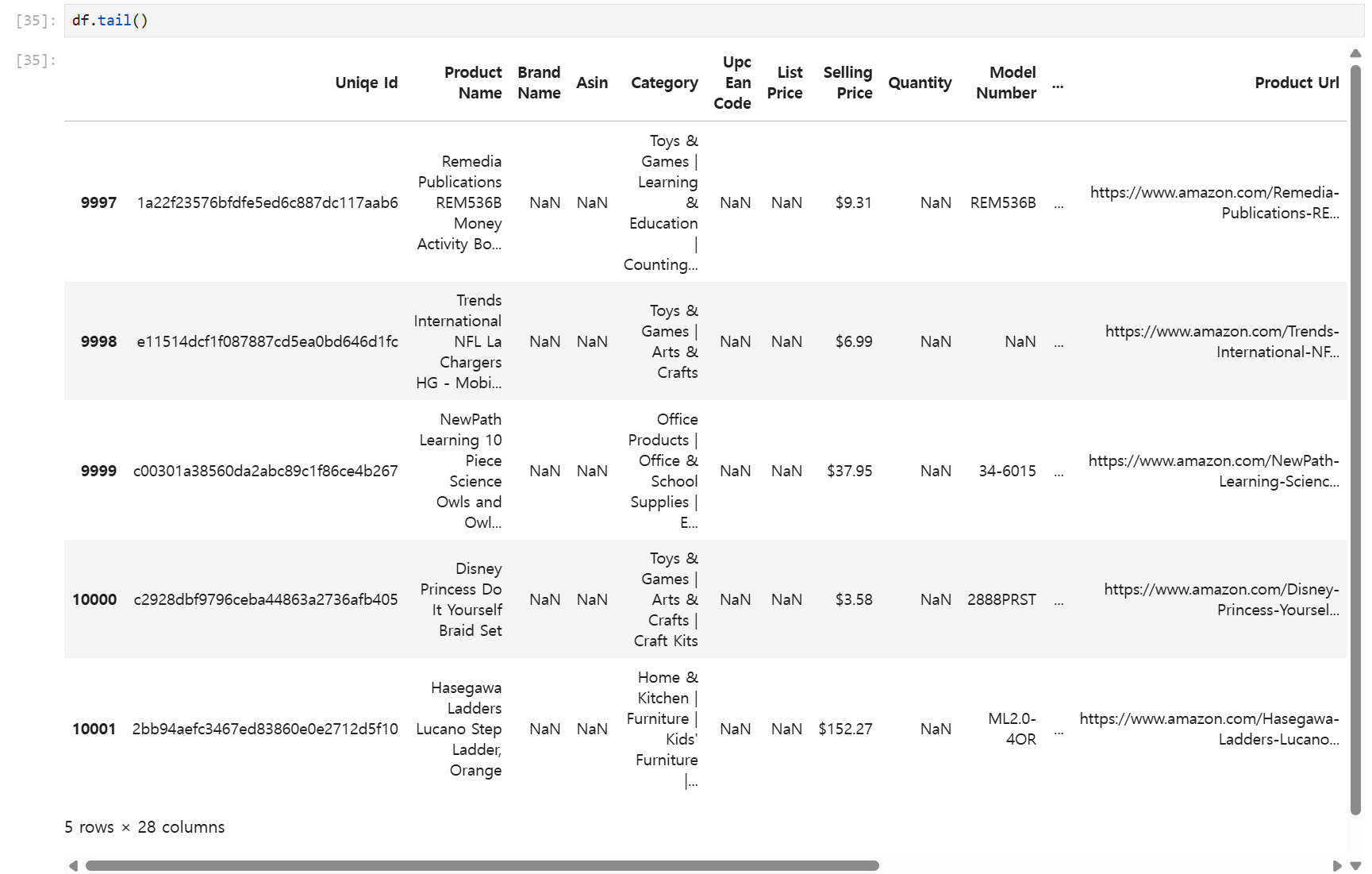
df.tail()tail은 아래에서부터 지정된 수의 행을 출력

len함수를 써서 행의 개수도 확인할 수 있다.

shape #행과 열의 개수 출력
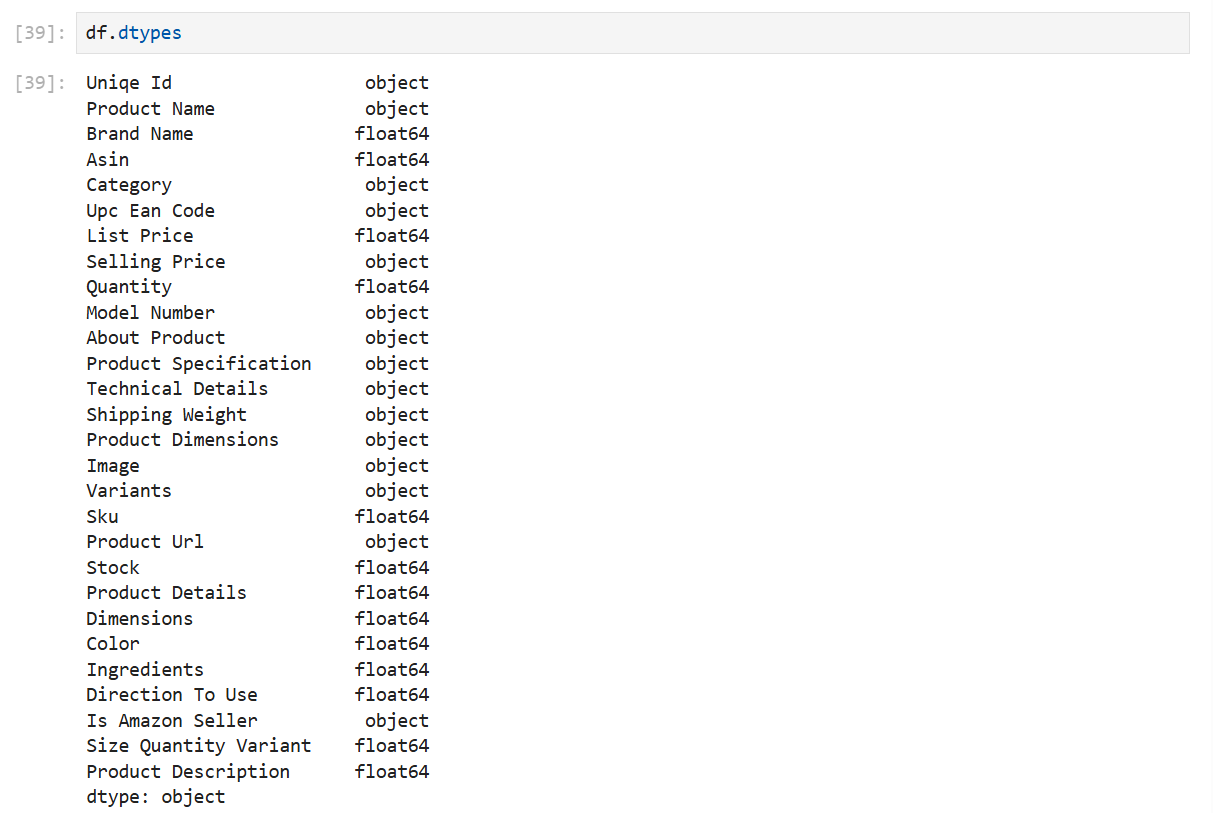
dtypes #데이터 타입 출력

columns #컬럼명 출력
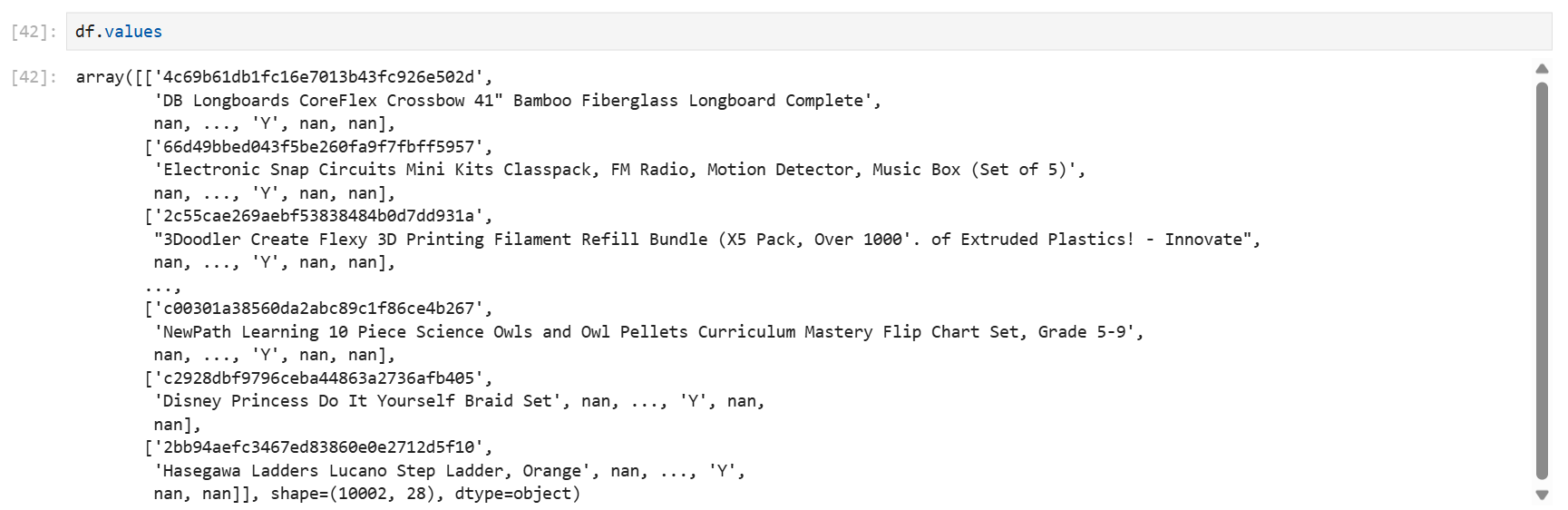
values #각 컬럼에 들어 있는 값들을 실제로 출력
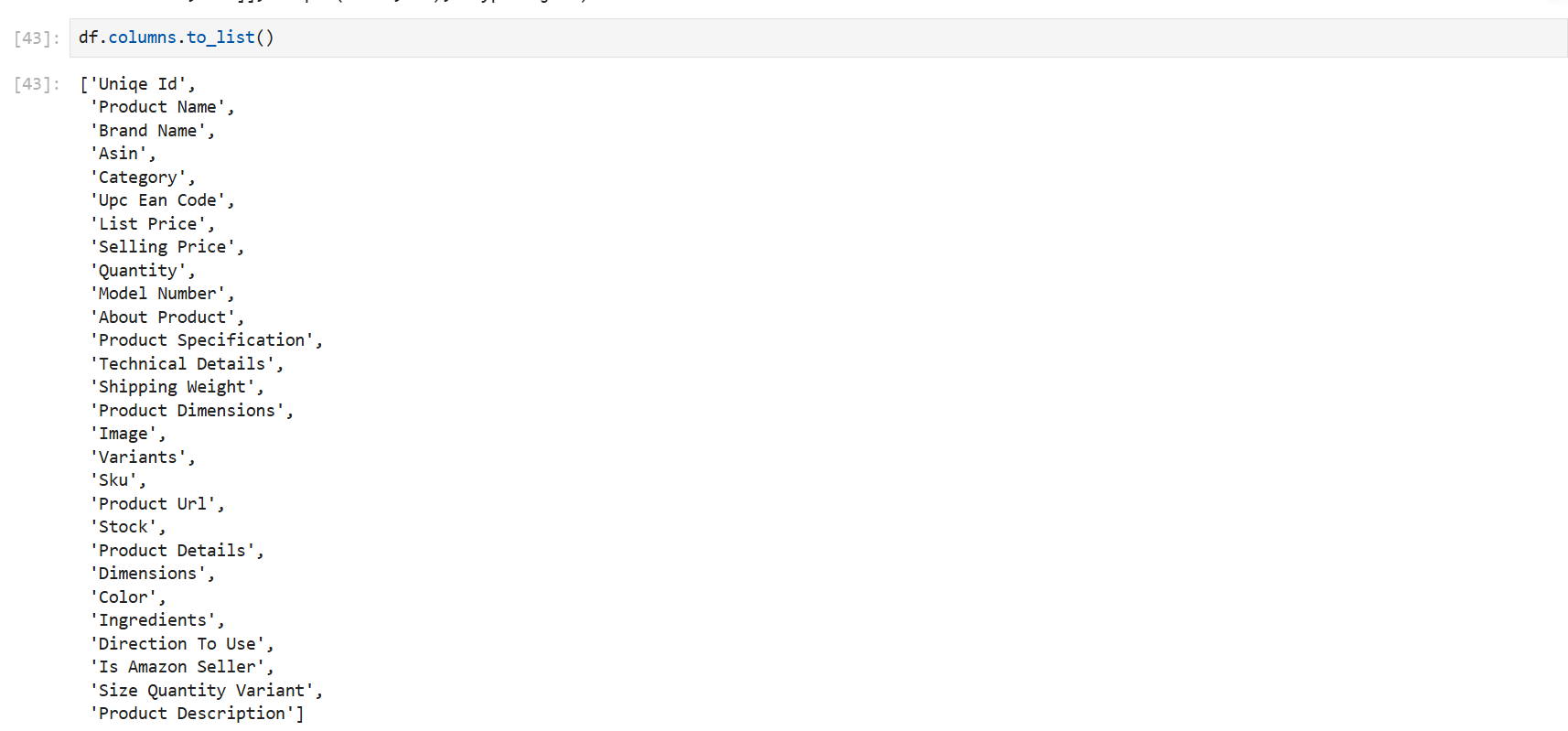
columns.to_list() #컬럼을 리스트 형식으로 출력
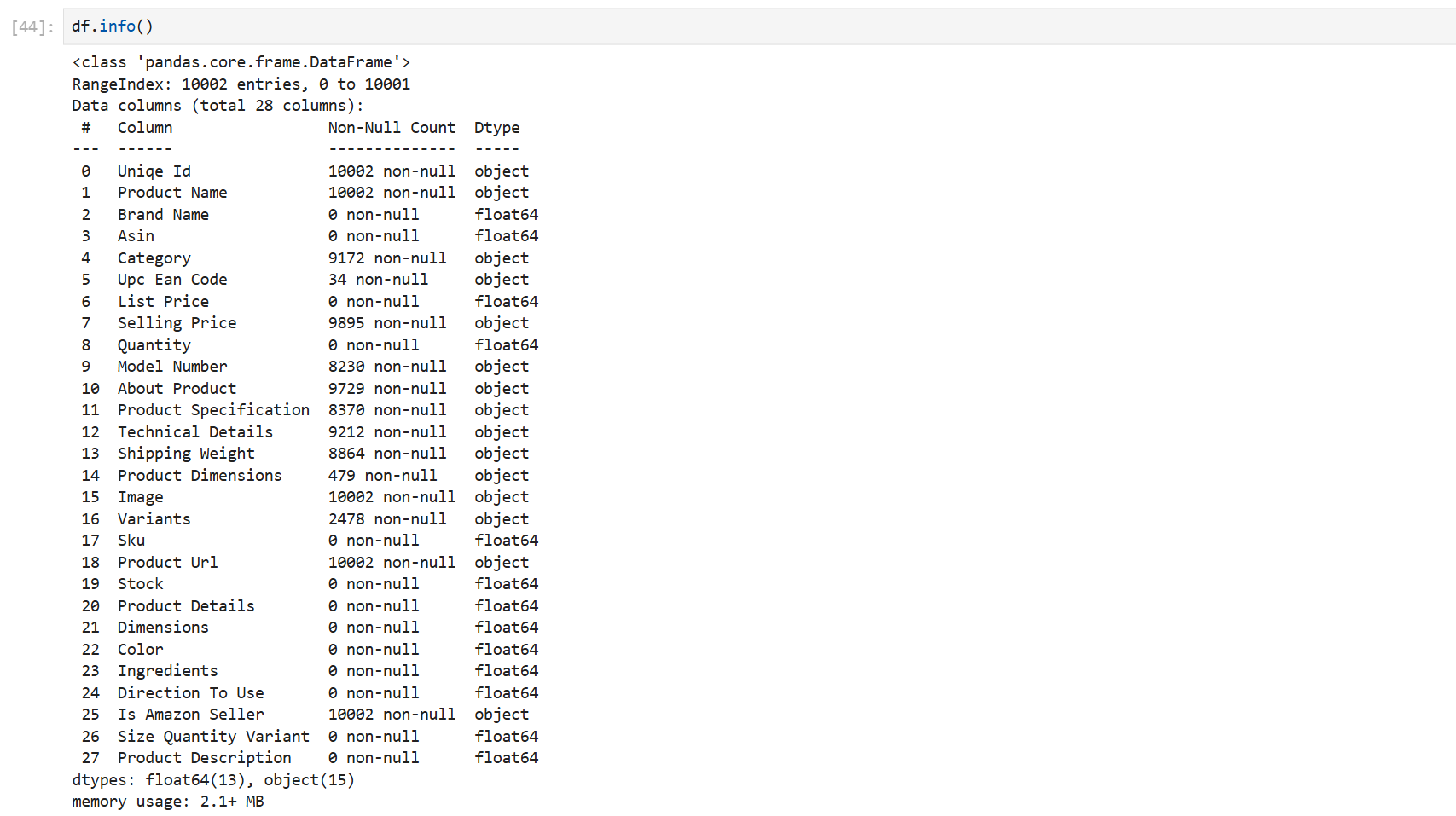
info() #위의 테이블 정보를 다 합쳐서 출력
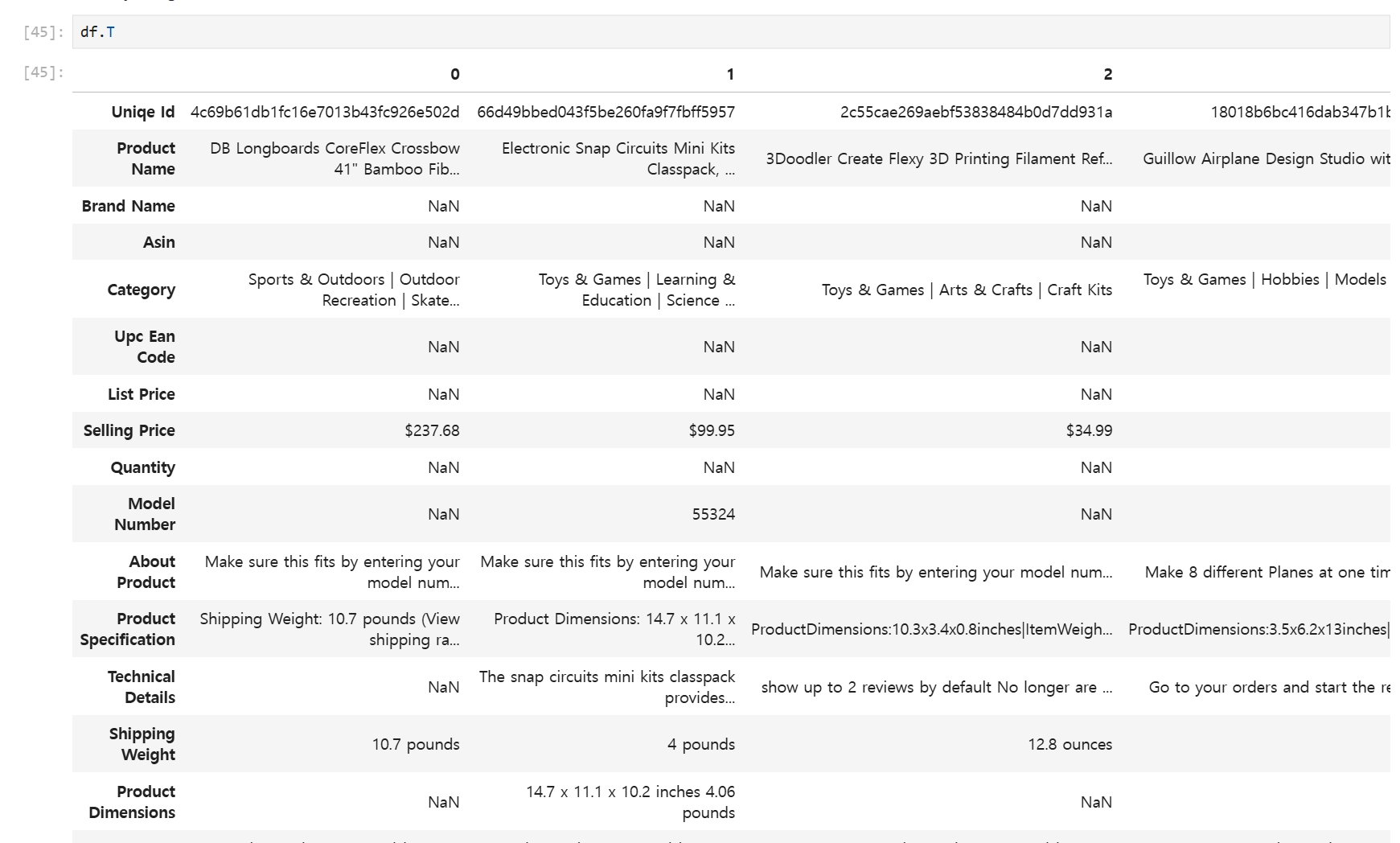
T #테이블의 행과 열을 바꿔서 출력
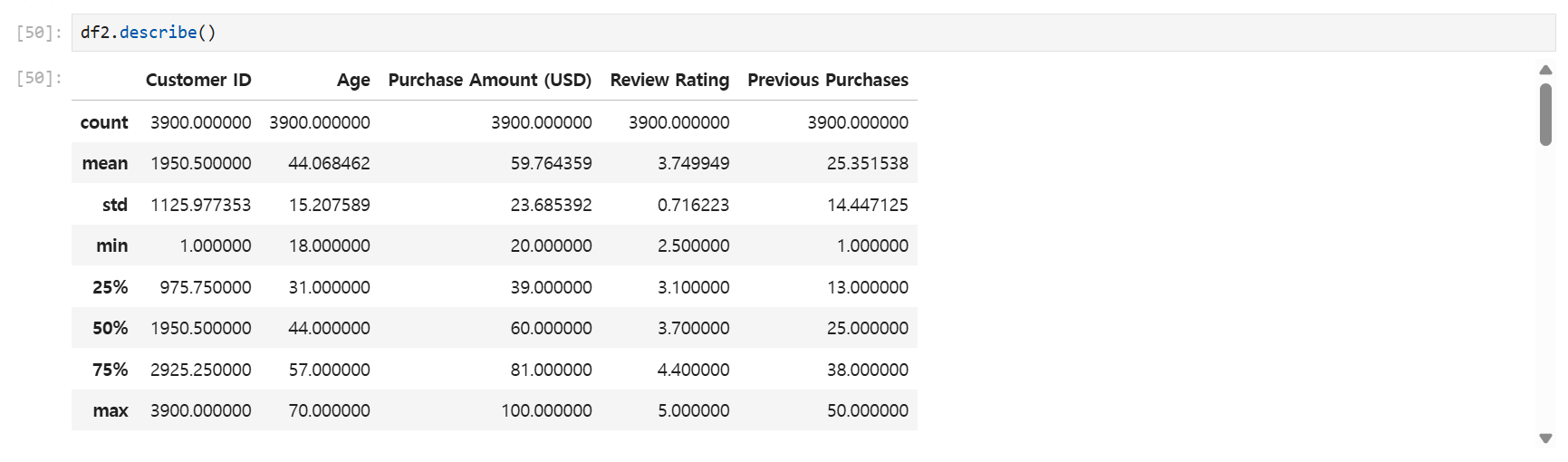
describe() # 전체 행 갯수, 평균, 표준편차, 최솟값, 사분위수, 최댓값 출력
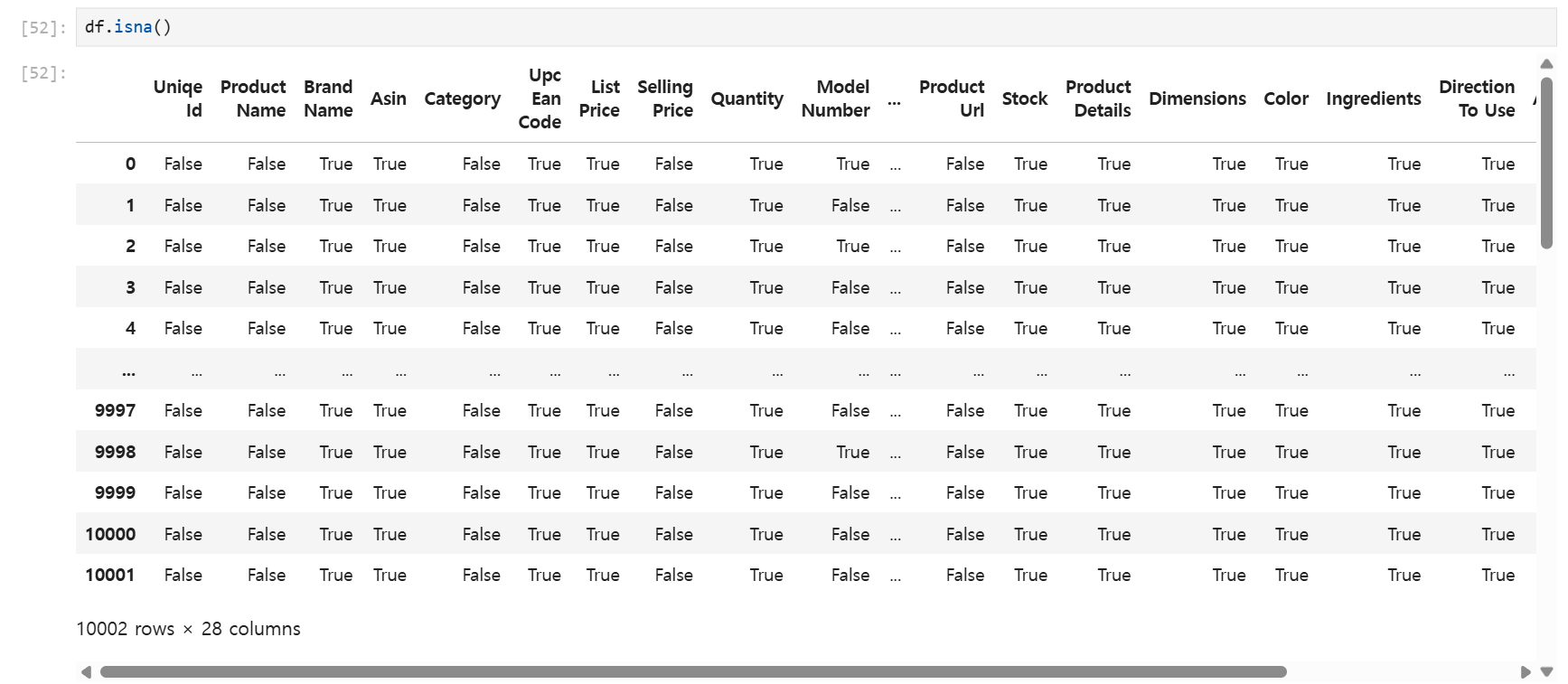
isna() 또는 isnull() #데이터가 null인지 아닌지 확인(null이면 True)
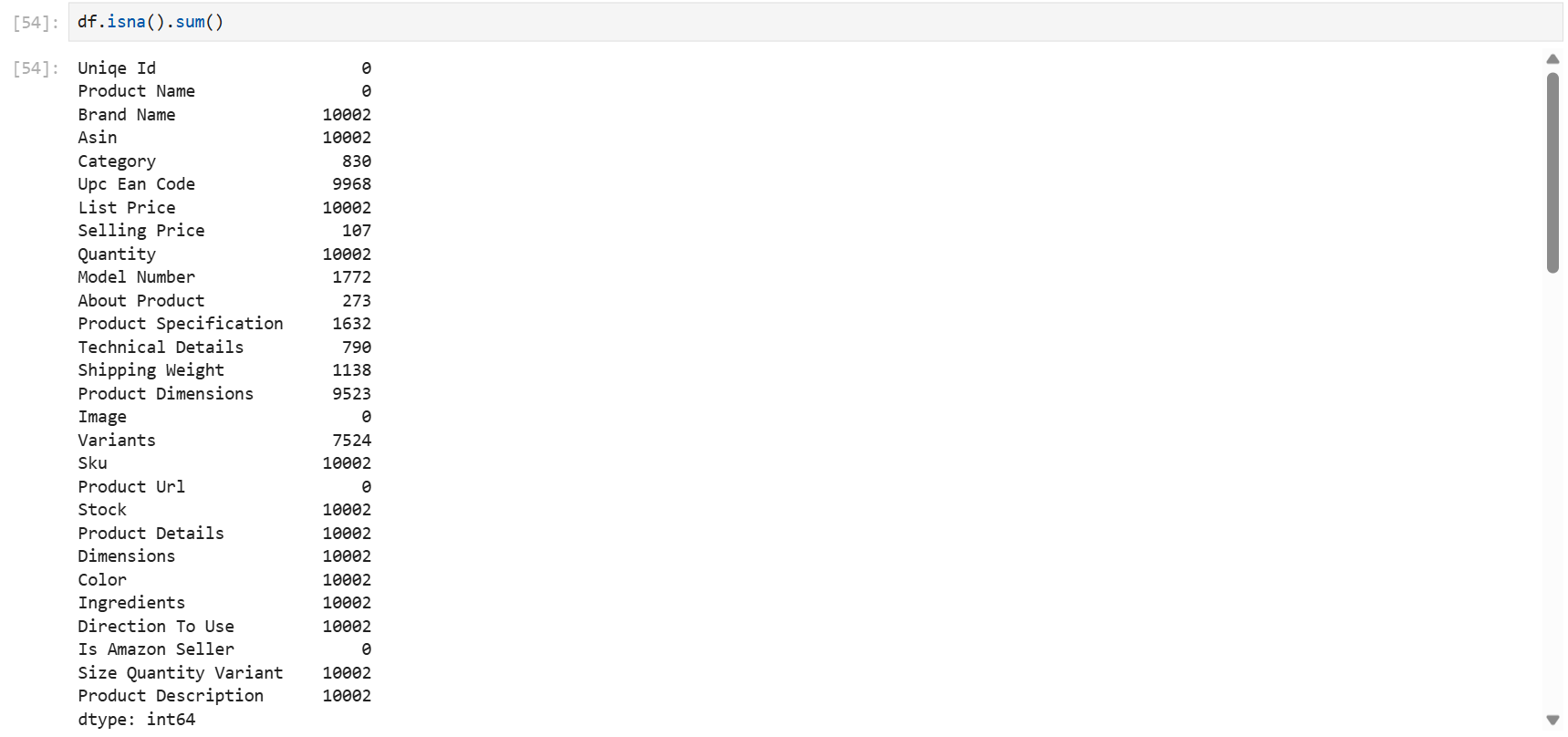
isna().sum() 또는 isnull().sum() #null인 데이터 개수 출력
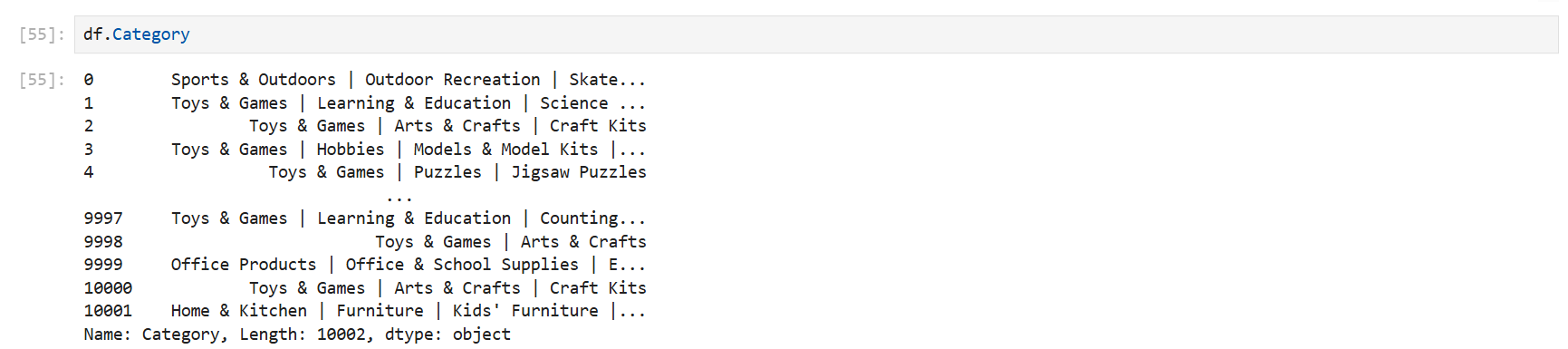
df.Category
df['Category'] #가장 많이 사용
df.iloc[:4] #':'은 모든 행을 다 가져오라는 의미. :4는 4번째 컬럼의 모든 행을 다 가져오라는 의미Category라는 컬럼에 입력된 데이터를 출력하는 세 가지 방법
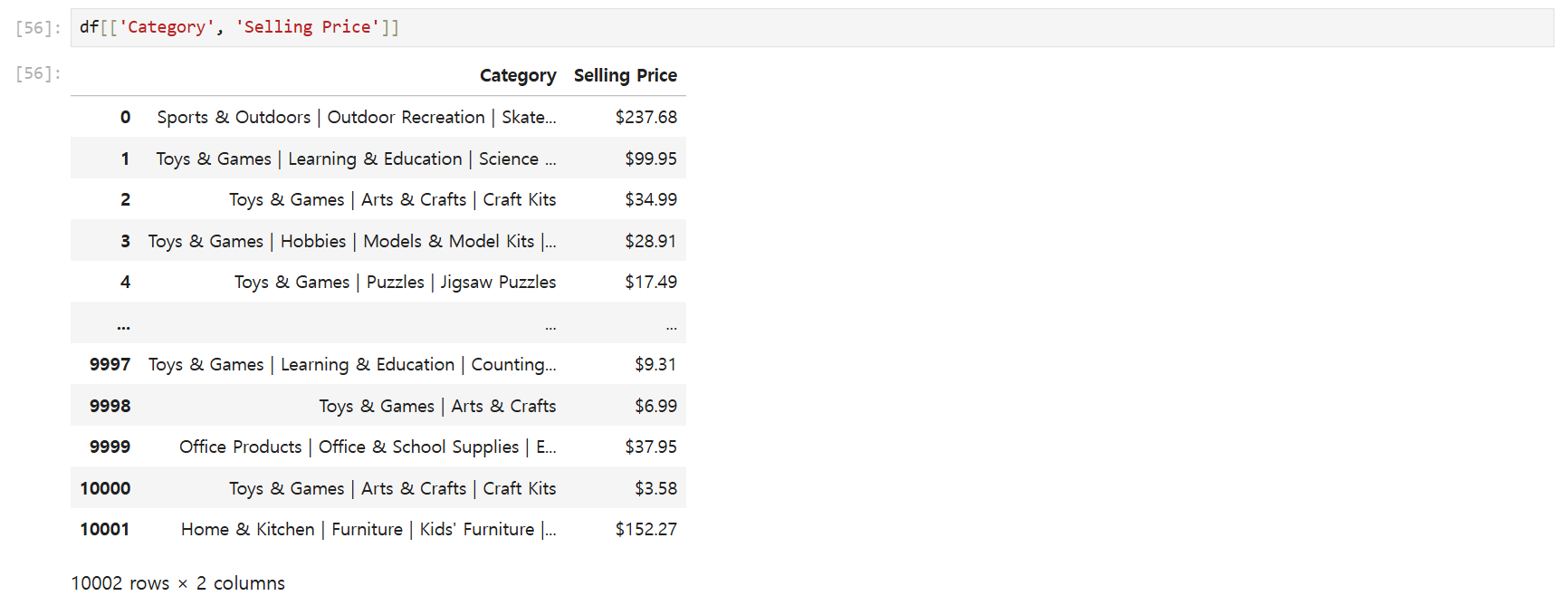
2개 이상의 컬럼을 출력하고 싶을 땐 [['', '']]를 사용한다.

dropna() #하나라도 null이 있는 행을 모두 삭제한다.
df3는 모든 행들이 하나라도 null이 있어서 데이터가 하나도 출력되지 않았다.
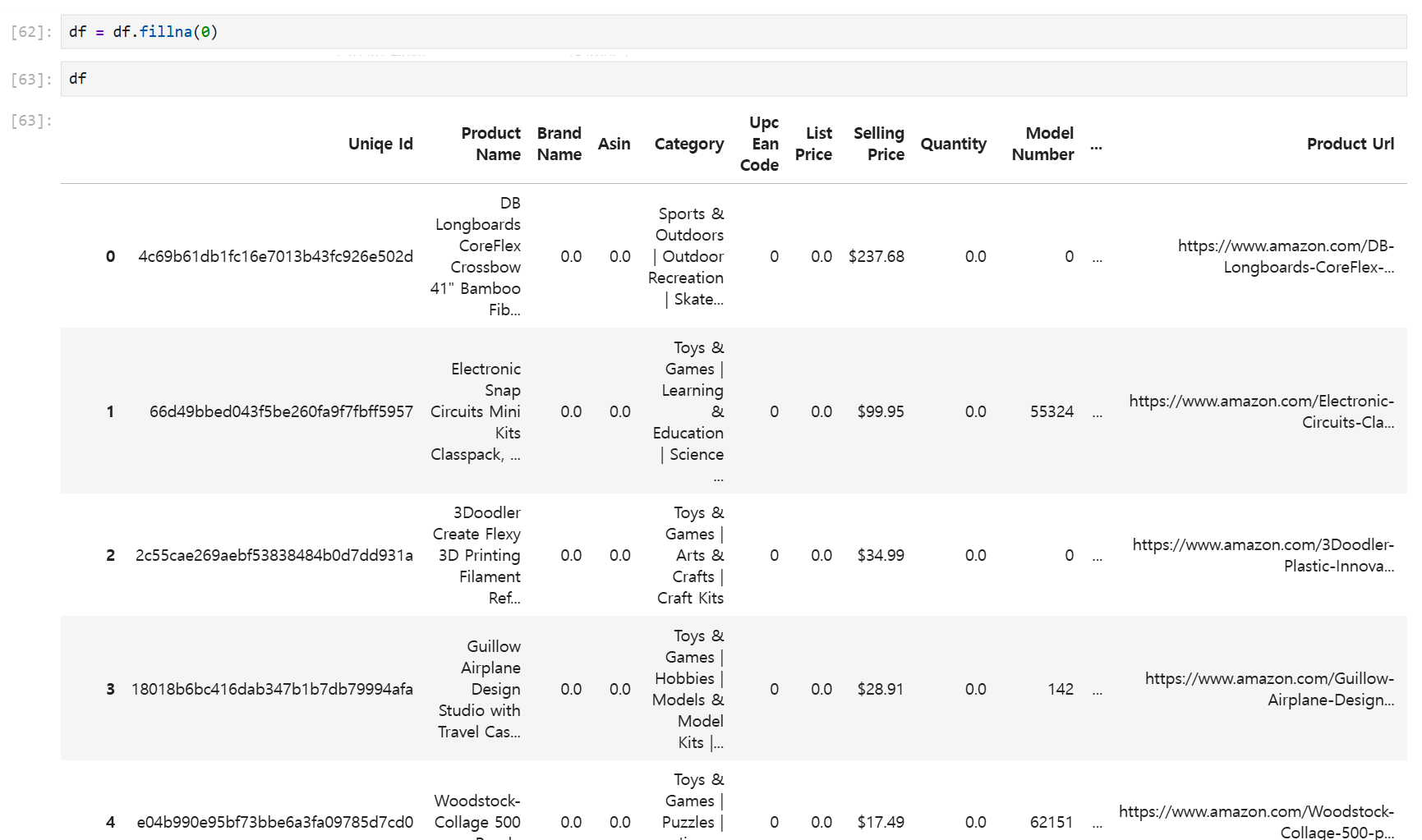
fillna() #null에 특정 값을 채워서 출력
조건절 걸어주기
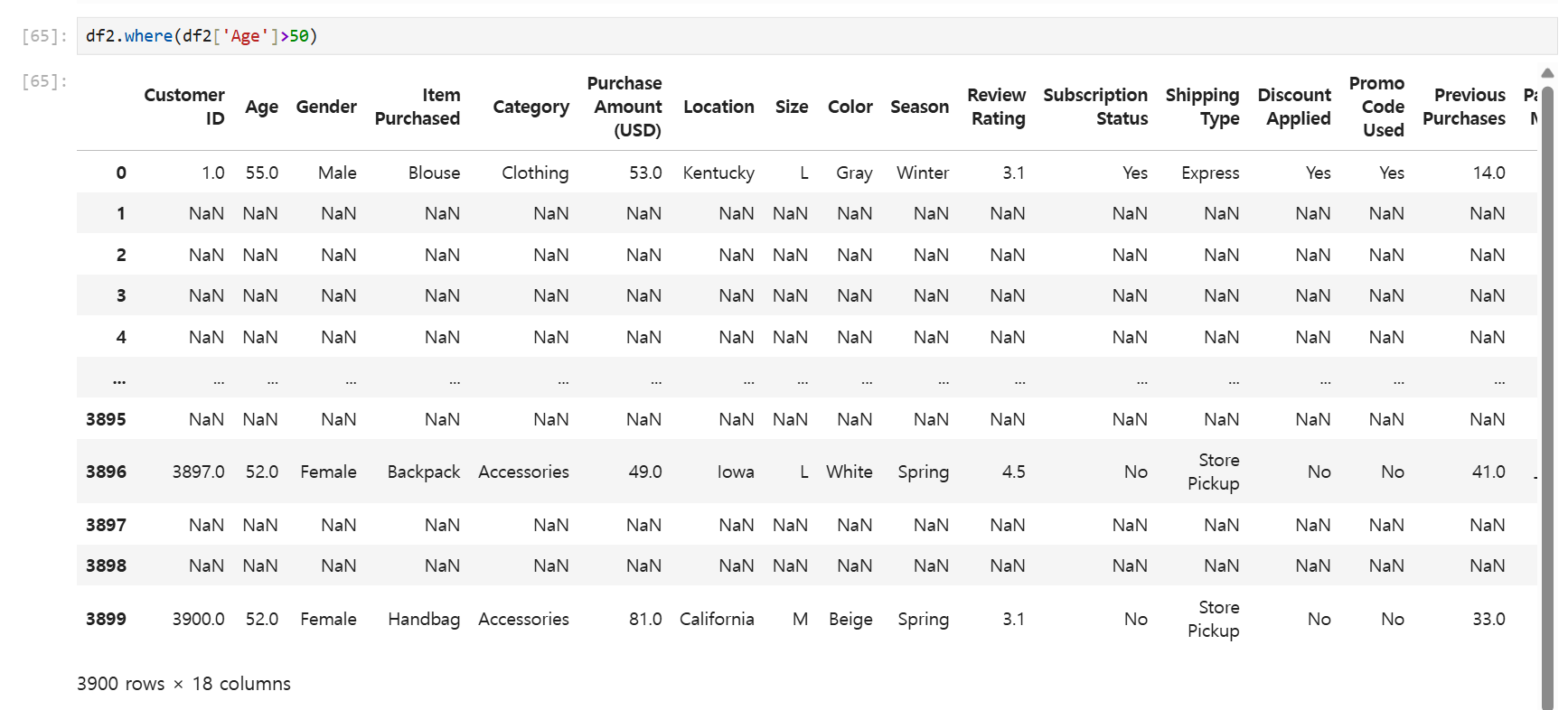
SQL에서는 조건에 부합하지 않는 데이터는 출력되지 않지만, Python에서는 NaN으로 함께 출력된다.
조건을 부합하는 데이터만 가져오고 싶을 때
여러가지 걸고 싶을 때 중첩은 &, 그 중 하나라도 만족은 |이다.

그러나 에러 발생,,,
Python에서 =은 대입해주는 것이기 때문에 male인지 아닌지 T/F는 ==을 사용
''을 반드시 사용
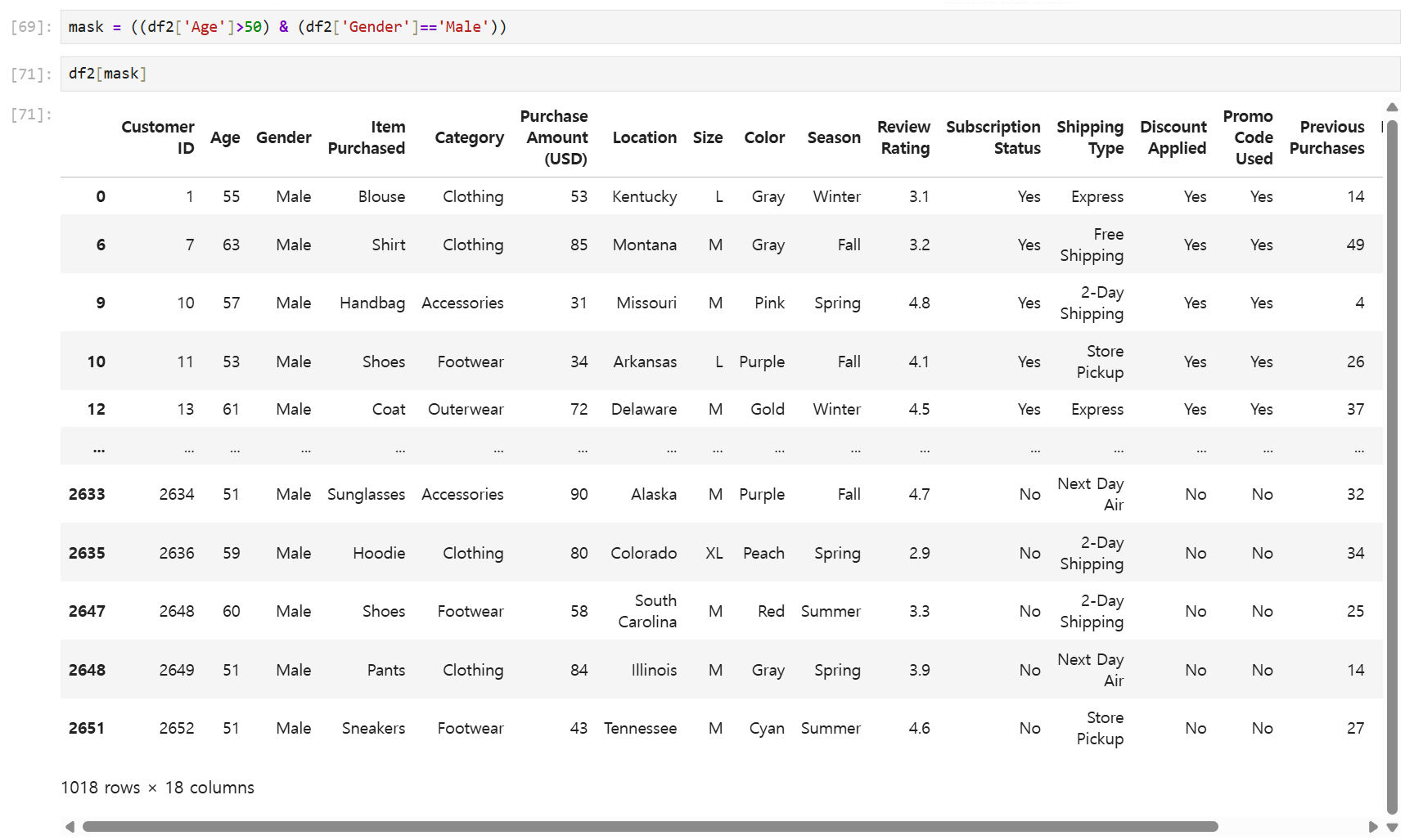
올바르게 출력되는 모습
이런식으로 조건에 부합하는 데이터를 잘라서 출력하는 것을 mask method라고 한다.
mask method는 반드시 []안에 쓴다
Group by로 묶어서 count하기

df2.groupby('Gender')['Customer ID'].count()group으로 묶고 싶은 기준 컬럼은 ()안에, 세고 싶은 컬럼은 []안에 쓴다.
이건 외울것!!
여러 개의 기준으로 묶고 싶다면
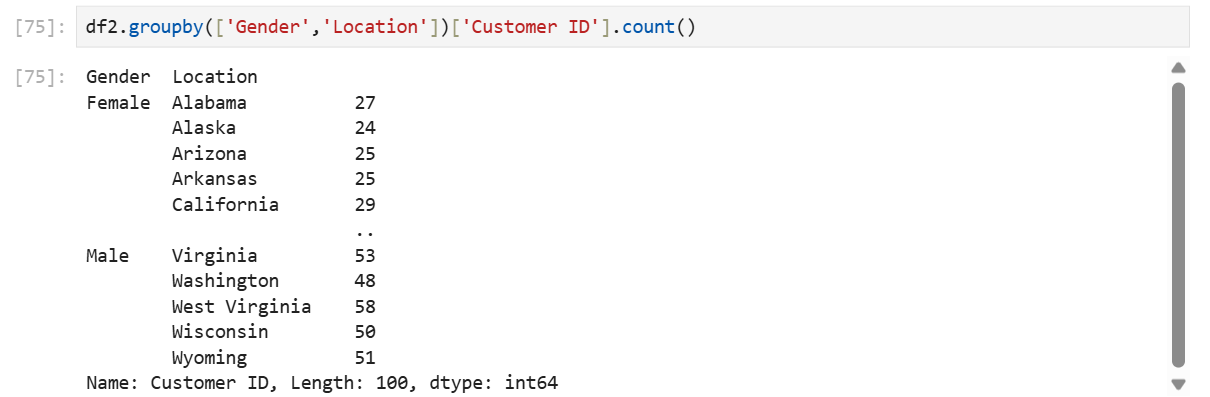
df2.groupby(['Gender','Location'])['Customer ID'].count()()안에 묶고 싶은 기준 컬럼들을 병렬로 쓴다.
단, ([])형태로 쓸것!!
중복 제거를 하고 싶을 때
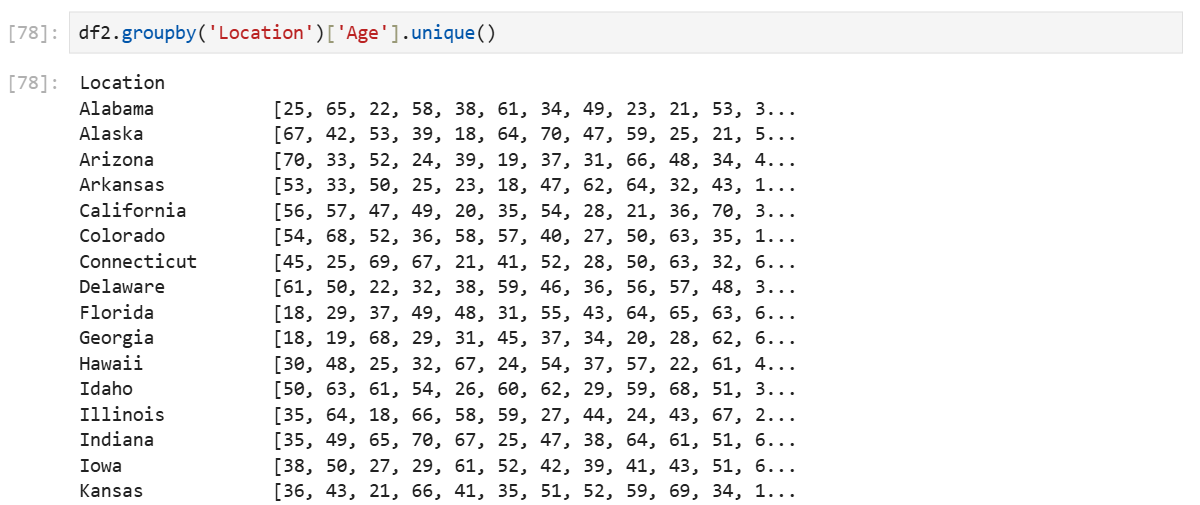
df2.groupby('Location')['Age'].unique()unique함수를 사용한다.
중복 제거를 하고 count하고 싶을 때
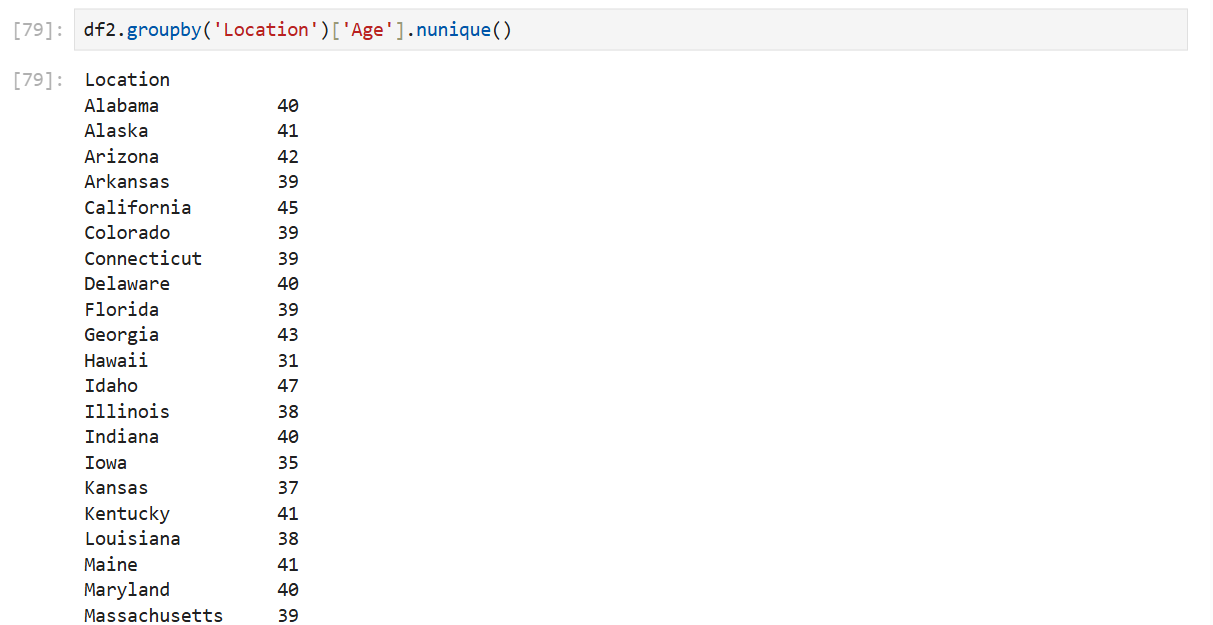
nunique함수를 사용한다.
*count: 중복 데이터 포함
*nunique: 중복 데이터 제외
파이썬에서 order by사용하기
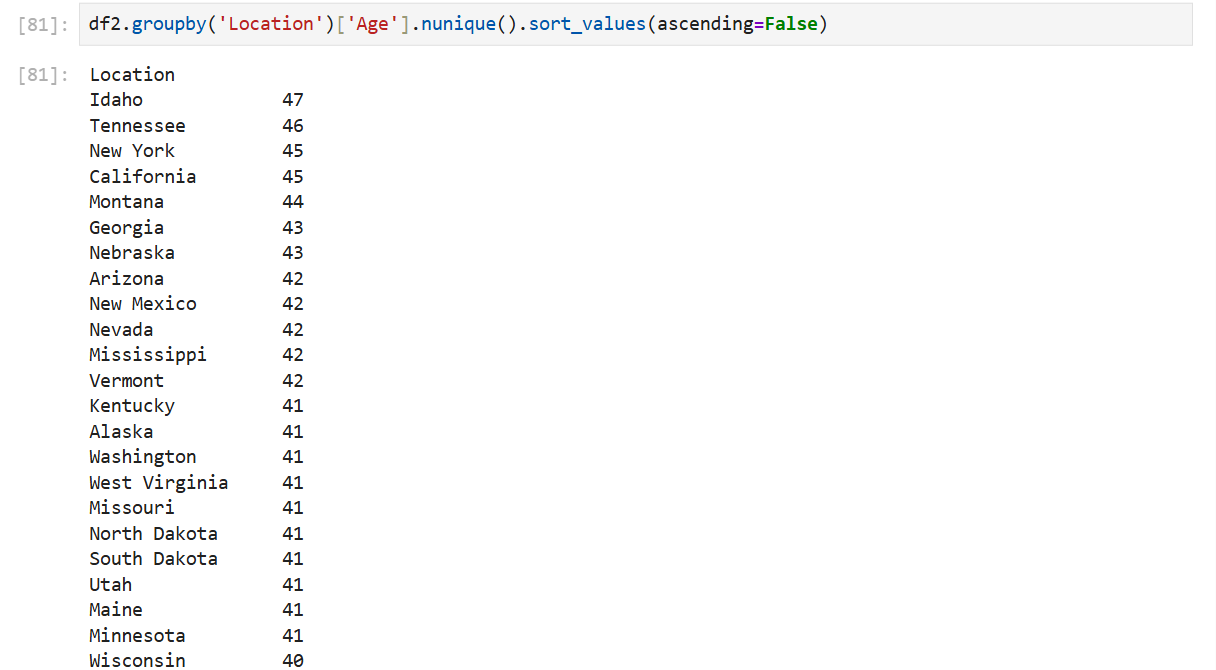
df2.groupby('Location')['Age'].nunique().sort_values(ascending=False)제일 뒤에 sort_values()를 사용한다.
ascending=True이면 오름차순 정렬
ascending=False이면 내림차순 정렬
