오늘은 파이썬을 이용해 테이블을 자유롭게 변환하는법을 배워보았다!
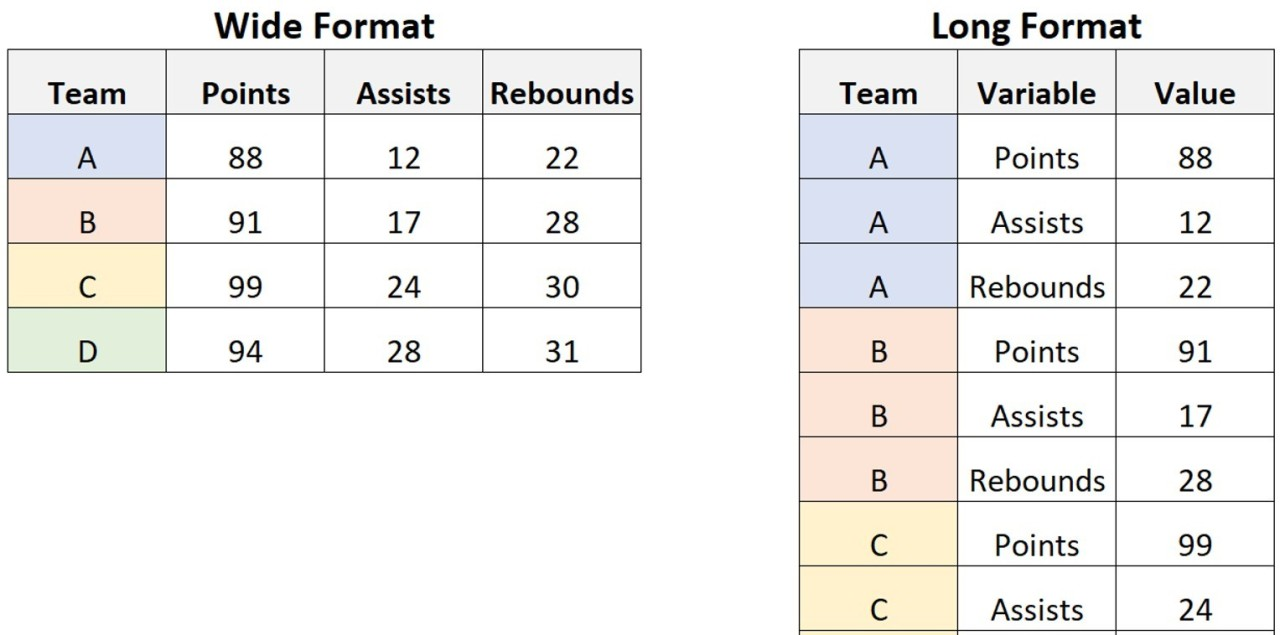
Wide format은 각 주제가 단일 행으로 표시되며, 측정값을 한 행에 표시한다. 열은 그 측정값의 의미를 나타낸다.
Long format은 하나의 열에 변수 이름(데이터)를 나타내고, 다른 열에 그에 대응하는 변수를 나타내며, 하나의 행에 하나의 측정값이 위치한다.
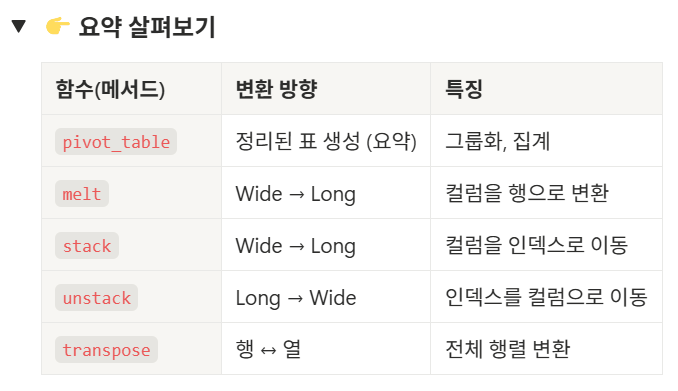
오늘 배울 함수를 요약하면 다음과 같다
하나하나 살펴보자
테이블을 핸들링하는 기법에는 여러가지가 있다
1. Tranpose
테이블의 열과 행을 바꿔주는 가장 간단한 함수이다
데이터프레임.T의 형태로 쓴다
컬럼은 수평으로 나열되어 있으므로 열과 행을 전치하여 컬럼을 쉽게 확인할 수 있다
행이 많을 경우 변환하는 데 오래 걸리므로 .head()를 사용하여 간단한 테이블을 변환할 수 있다
-
Pivot Table
pd.pivot_table(데이터프레임, index=컬럼명, columns=컬럼명, values=컬럼명, aggfunc=연산방식)의 형태로 쓴다 -
Melt
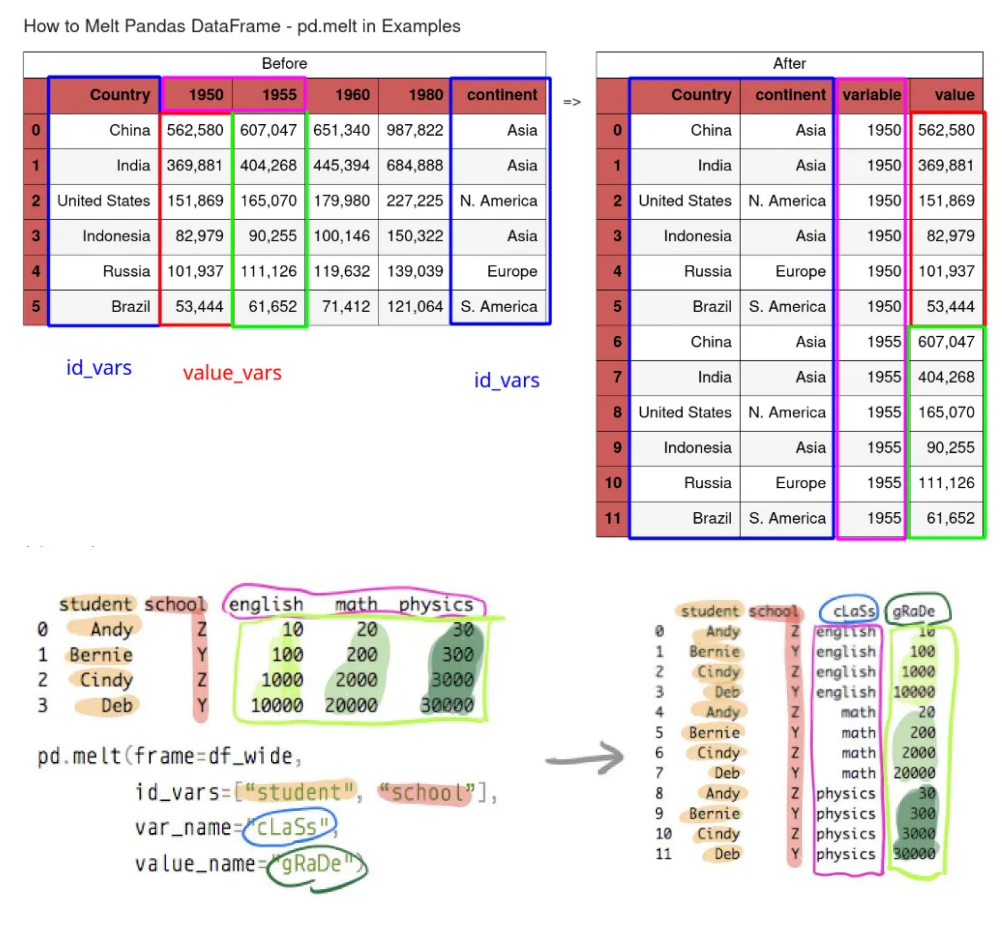
피벗 테이블을 기존 형태로 바꿔주는 함수이다.
Melt에는 id, var, value 세 가지 요소가 있다
id로 지정한 컬럼을 제외한 나머지 컬럼을 데이터로 변환해서 var(iable)컬럼에 위에서 아래로 쌓아준다
value 컬럼에는 id와 var에 대응하는 값을 넣어준다
데이터프레임.melt(id_var=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
-id_vars: 기준이 될 열(그대로 유지할 열)
-value_vars: 기준열에 대한 하위 카테고리를 나열할 열(병합할 열)
-var_name: 카테고리들이 나열된 열의 이름(병합 후 표현할 열 이름)
-value_name: 카테고리들의 값이 나열될 열의 이름 설정(기본값:value)
-col_level: multi index의 경우 melt를 수행할 레벨을 설정
-ignore_index: 인덱스를 재정렬할지의 여부
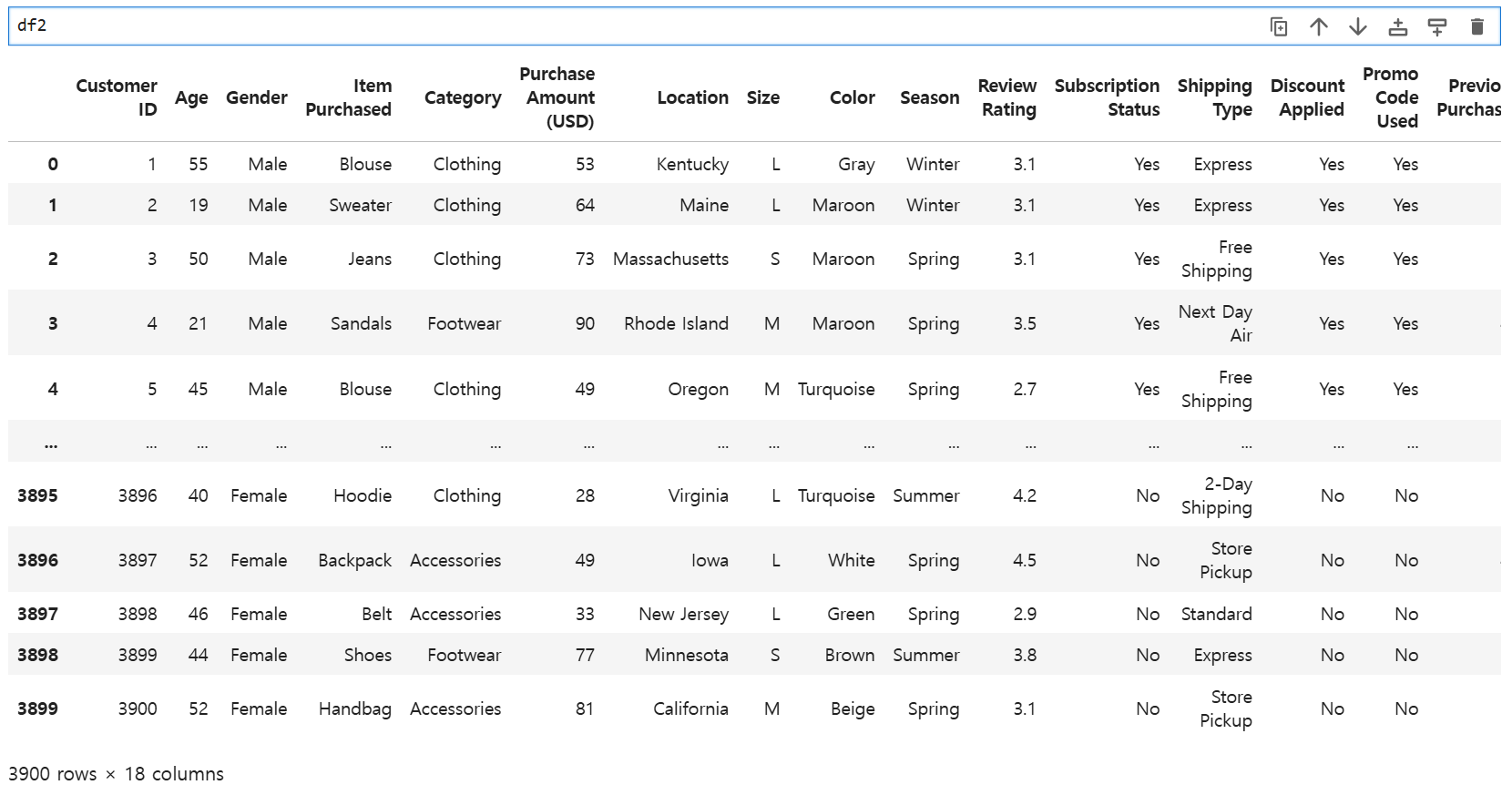
df2가 다음과 같을 때 Customer ID를 id로, Season과 Size를 var로 지정하고, var name을 Feature, value name을 Value로 지정하면 다음과 같은 테이블이 출력된다
season과 size가 데이터로 들어가고 그에 대응하는 값들이 value로 나온다

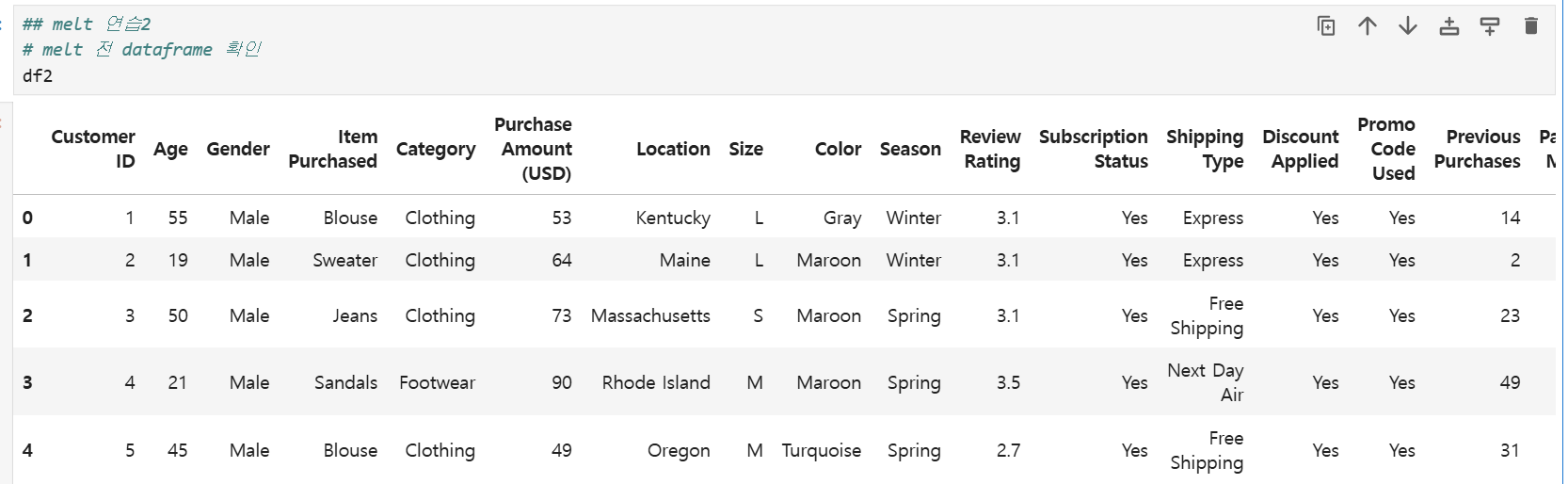
df2를 5행까지만 자르고 id를 Location으로만 지정하여 melt하면
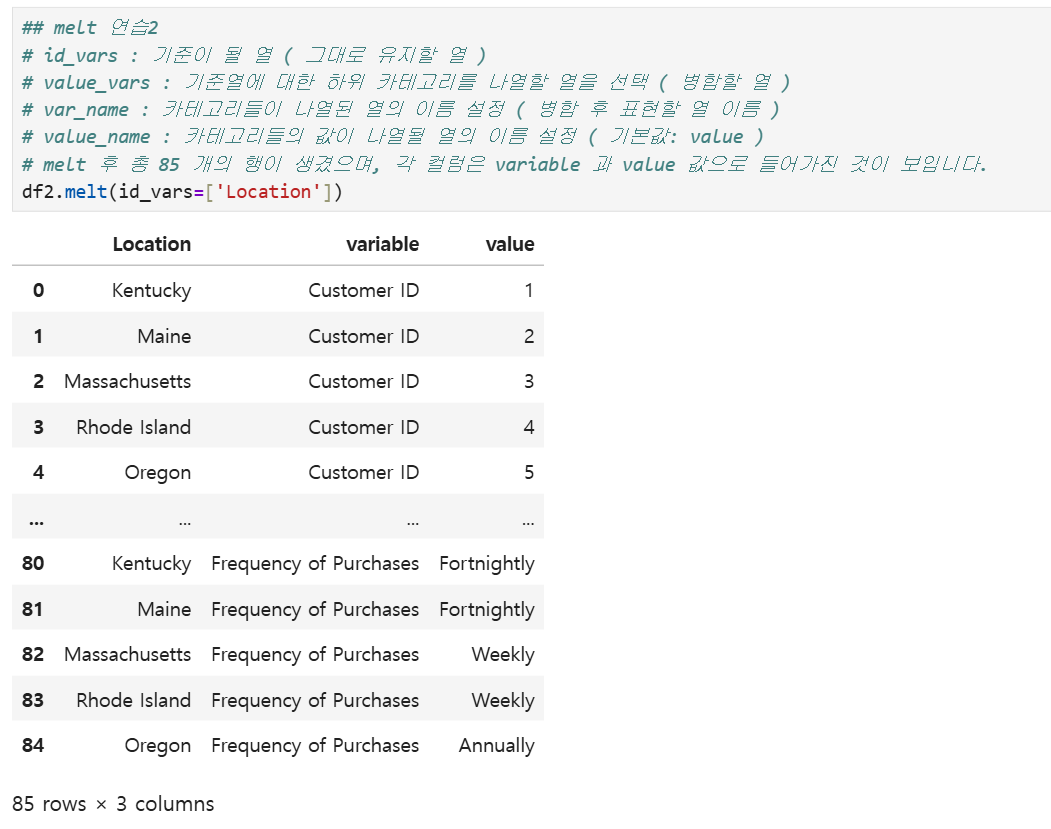
id인 Location을 제외한 나머지 컬럼들은 데이터로 들어가고 value가 표시되어 다음과 같이 켄터키의 customer id부터 오리건의 customer id까지, 켄터키의 나이부터 오리건의 나이까지, ..., 켄터키의 구매 주기부터 오리건의 구매 주기까지 데이터가 촤르륵 나오는 걸 확인할 수 있다
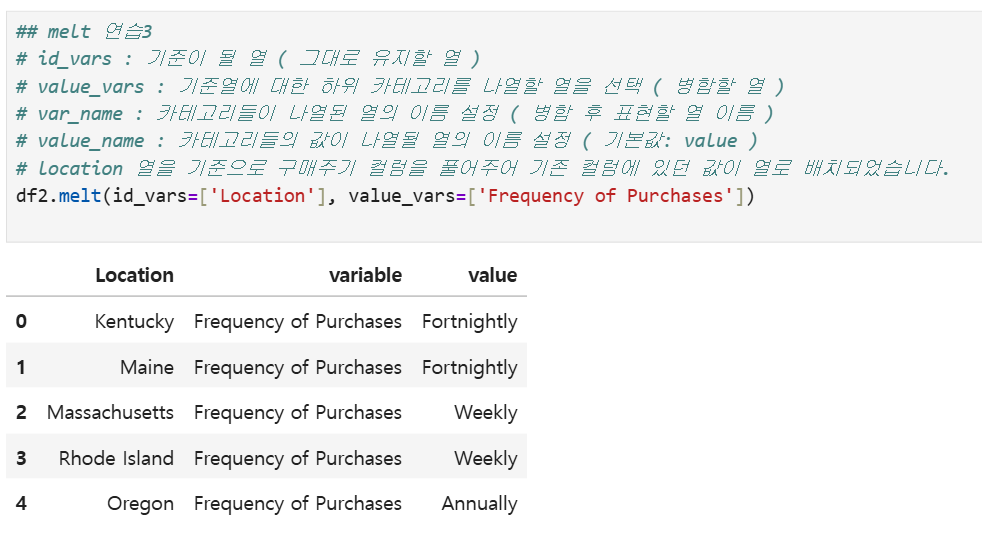
id가 Location, var가 Frquency of Purchases이면 다음과 같은 테이블이 출력된다
id는 그대로 나오고, var는 컬럼명이 데이터로 들어가고, 원래 테이블의 Frquency of Purchases의 값은 그 옆에 대응되어 나온다는 걸 익히자 -
Stack
컬럼을 하위 인덱스로 변환
데이터프레임.stack(level=-1, dropna=True)
-level: stack을 수행할 인덱스 레벨(level=-1일 경우 제일 뒤(안쪽)이 수행됨)
-dropna: stack을 수행한 결과에서 결측값을 제거할지 여부를 지정
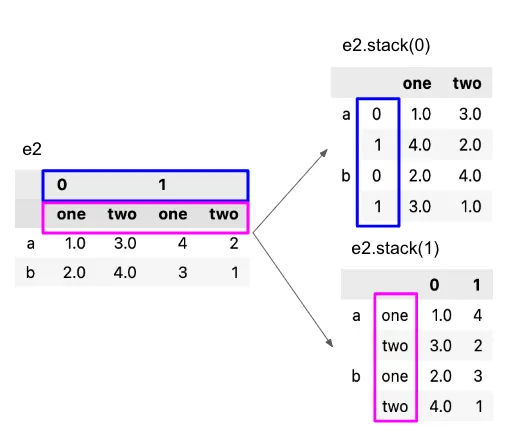
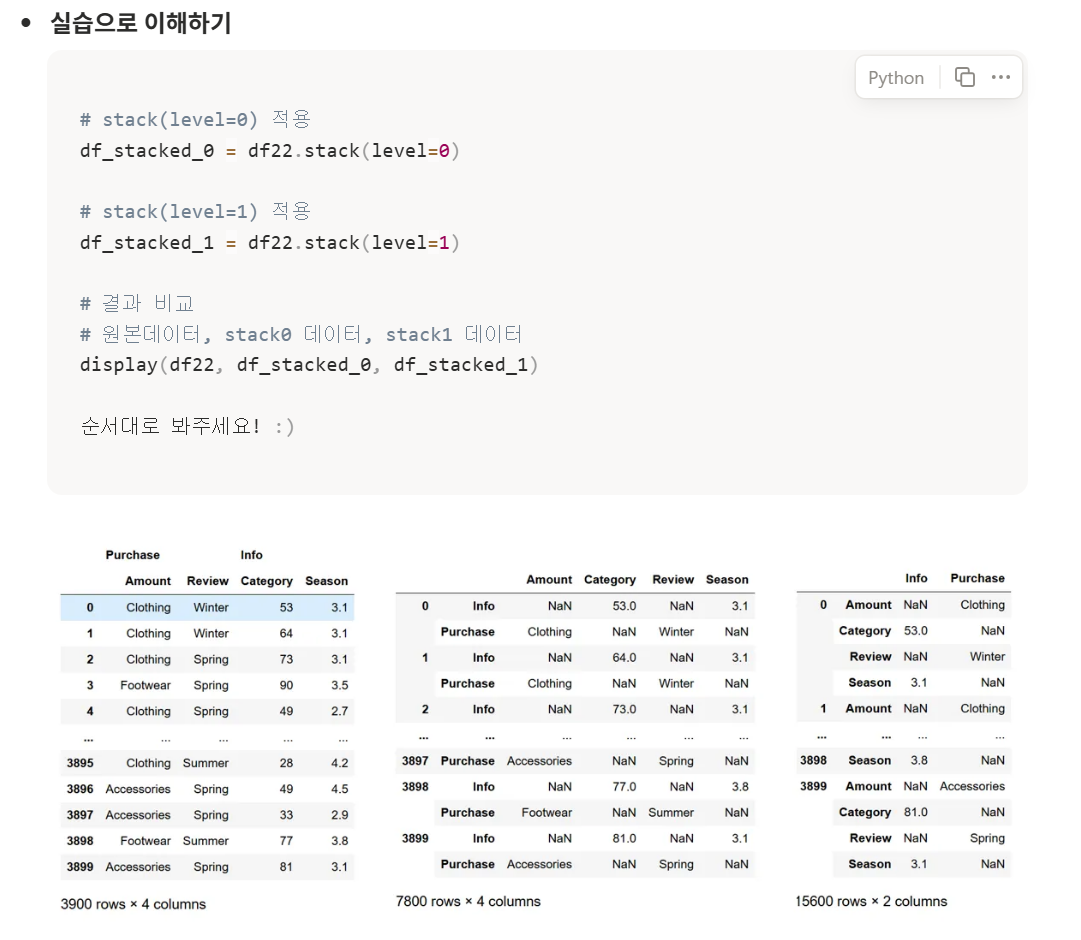
level=0일 때 윗 줄인 Purchase와 Info가, level=1일 때 아랫 줄인 Amount, Category, Review, Season이 인덱스로 들어간 것을 확인할 수 있다.
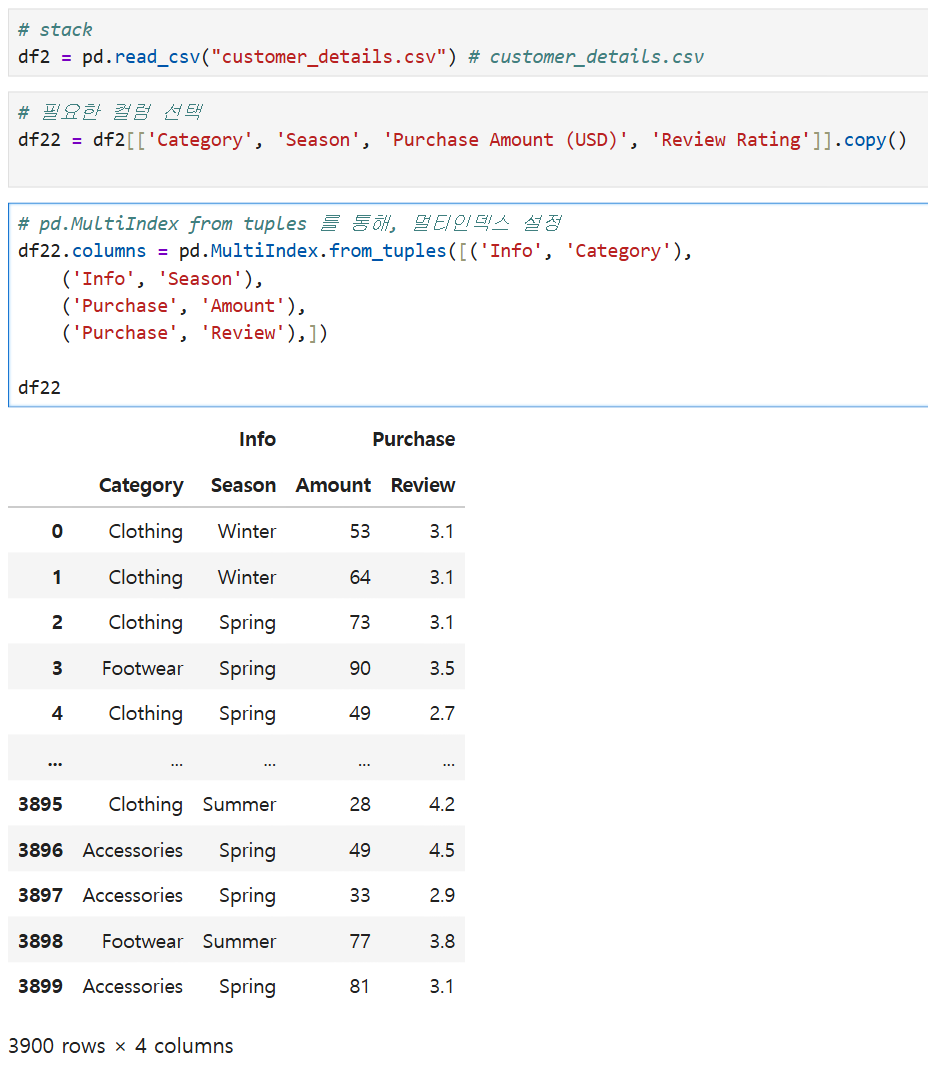
다음과 같이 컬럼 여러 개를 멀티 인덱스로 지정할 수도 있다
대신 컬럼 이름만 들어가는 것이기 때문에 데이터에 맞춰 컬럼명을 순서대로 내가 입력해줘야한다
-
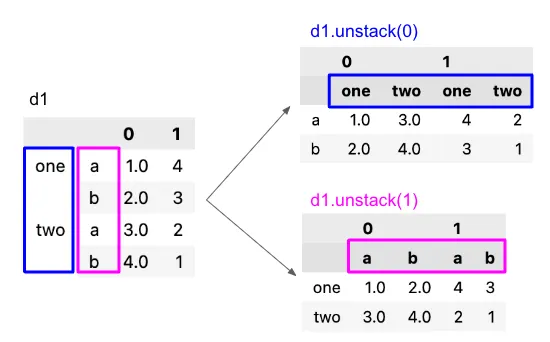
Unstack
인덱스 레벨을 컬럼으로 변환
**데이터프레임.unstack(level=0, fill_value=None)
-fill_value:결측값을 채울 값을 지정. None은 그대로 둠
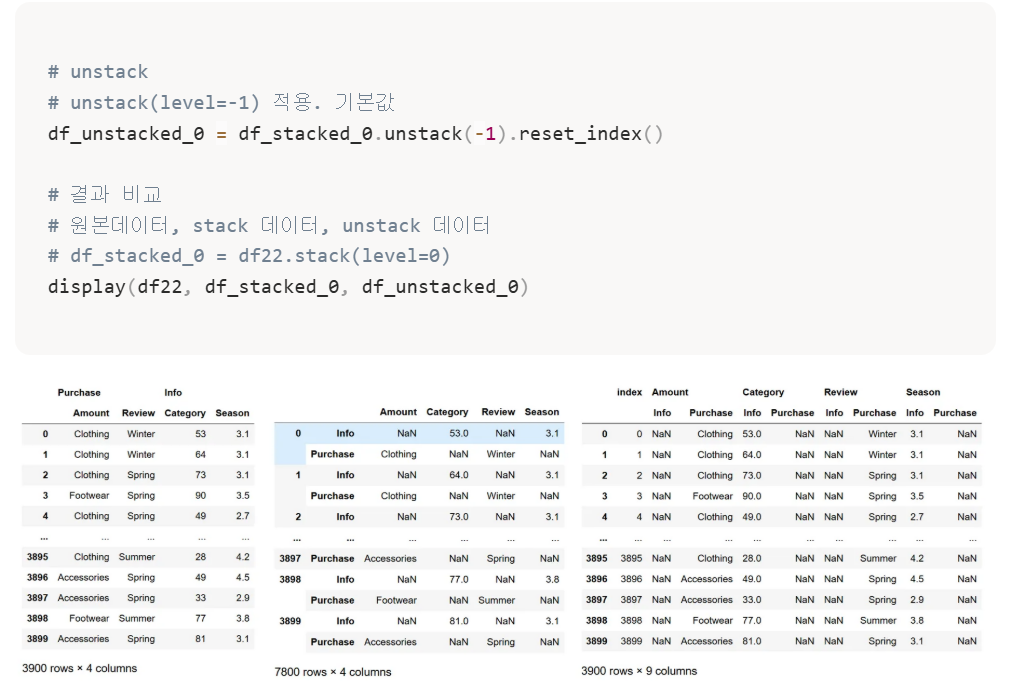
원래 테이블, stack, unstack을 차례대로 확인할 수 있다
