오늘은 파이썬의 window function을 배워보고자 한다.
window function이란 행과 행 간에 비교, 연산, 정의를 하기 위해 사용되는 함수이다.
파이썬에서 사용하는 window function에는 shift, rolling, expanding이 있다.
1. Shift
시계열 데이터의 인덱스를 원하는 기간만큼 끌어당기는 메서드(시계열 데이터가 아니어도 가능하지만 시계열 데이터에 주로 사용된다)
- 주요 파라미터
- periods: 이동할 기간. 음수 또는 양수로 입력.
- freq: 선택 매개변수. Y, M, D, H, T, S, Timestamp, 'Infer' 등이 위치
- fill_value: shift로 인해 생긴 결측치를 대체할 값 지정
- axis: 연산할 축방향 설정. 0(행) / 1(열)
- 예시
-df.shift(1).head()# 이전 값 땡김
-df.shift(**-**1).head()# 이후 값 땡김
-df.shift(periods=3,freq='D')# 3일 이동
-df.shift(periods=3,freq='infer')# df의 날짜간격을 분석해서 적당한 주기를 이동
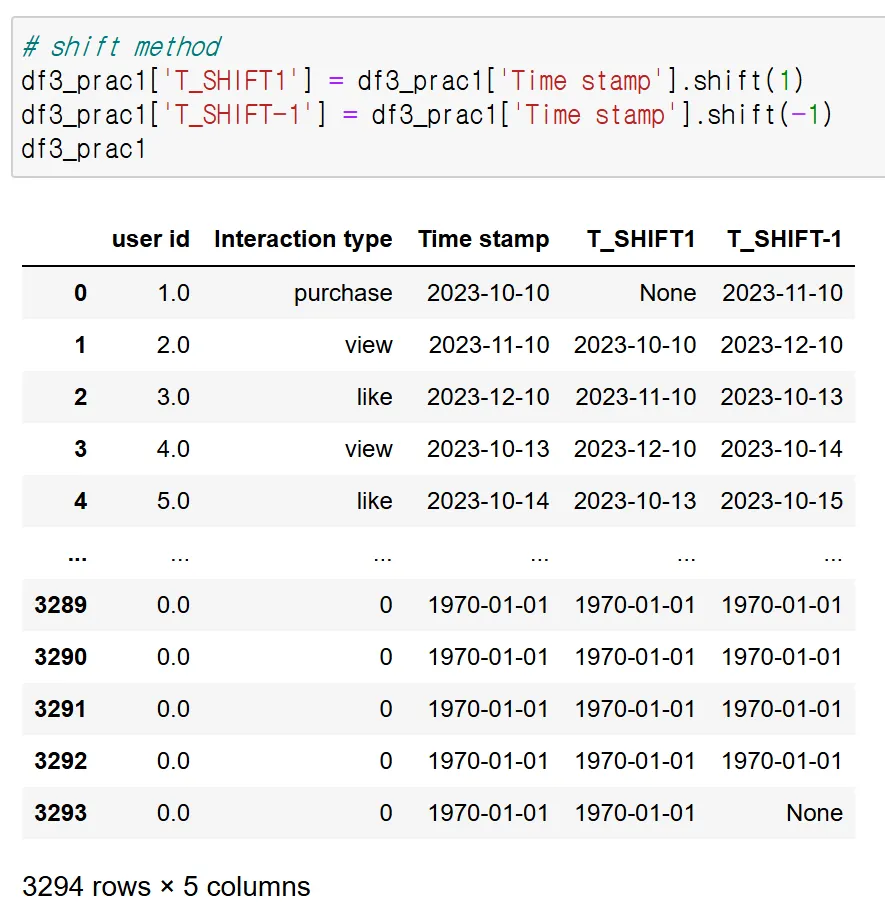
shift(1)은 이전 값을 땡기기 때문에 제일 윗행은 땡길 값이 없어서 None, shift(-1)은 이후 값을 땡기기 때문에 제일 아래 행이 None인 것을 확인할 수 있다.
2. Rolling
데이터 프레임 내 범위를 지정하여 값을 연산해주는 메서드
- 주요 파라미터
- window: 계산할 창(window)의 크기 입니다. 열 기준으로 계산할 경우 행의 수입니다.
- min_periods: 계산할 최소 크기(기간) . 기본적으로 window 크기와 동일.
- center: 계산을 중간 행에서 할 지 결정하는 파라미터. 기본값은 False, True 로 할 경우 중간 행을 기준으로 계산합니다.
- win_type: triang / gaussian 등 가중치를 넣어 계산할 경우 계산 방식.
- on: 시계열 인덱스나, 시계열과 유사한 열이 있을 경우 이 열을 기준으로 rolling을 수행할 수 있습니다.
- axis : 연산할 축방향 설정. 0(행) / 1(열)
- closed: 연산이 닫히는 방향을 설정. left / right / both / neither 이 존재합니다.
- right: 오른쪽 값을 포함하여 계산
- left: 왼쪽 값을 포함하여 계산
- both: 양쪽을 포함하여 계산
- neither: 양쪽을 포함하지 않고 계산
- method:{'single' / 'table'} numba를 이용하여 테이블 계산을 진행하여 속도를 높힐지 여부. 현재 'single'만 사용가능.
- 예시
-df.rolling(window=3).mean()# 3일 이동평균 구하기
-df.rolling(window=3).sum()# 3일 누적합 구하기
-df.rolling(window=3, center=Ture, closed='left').mean()# 3일 이동평균을 중간 행을 기준으로 계산하고, 왼쪽 값을 포함하여 계산
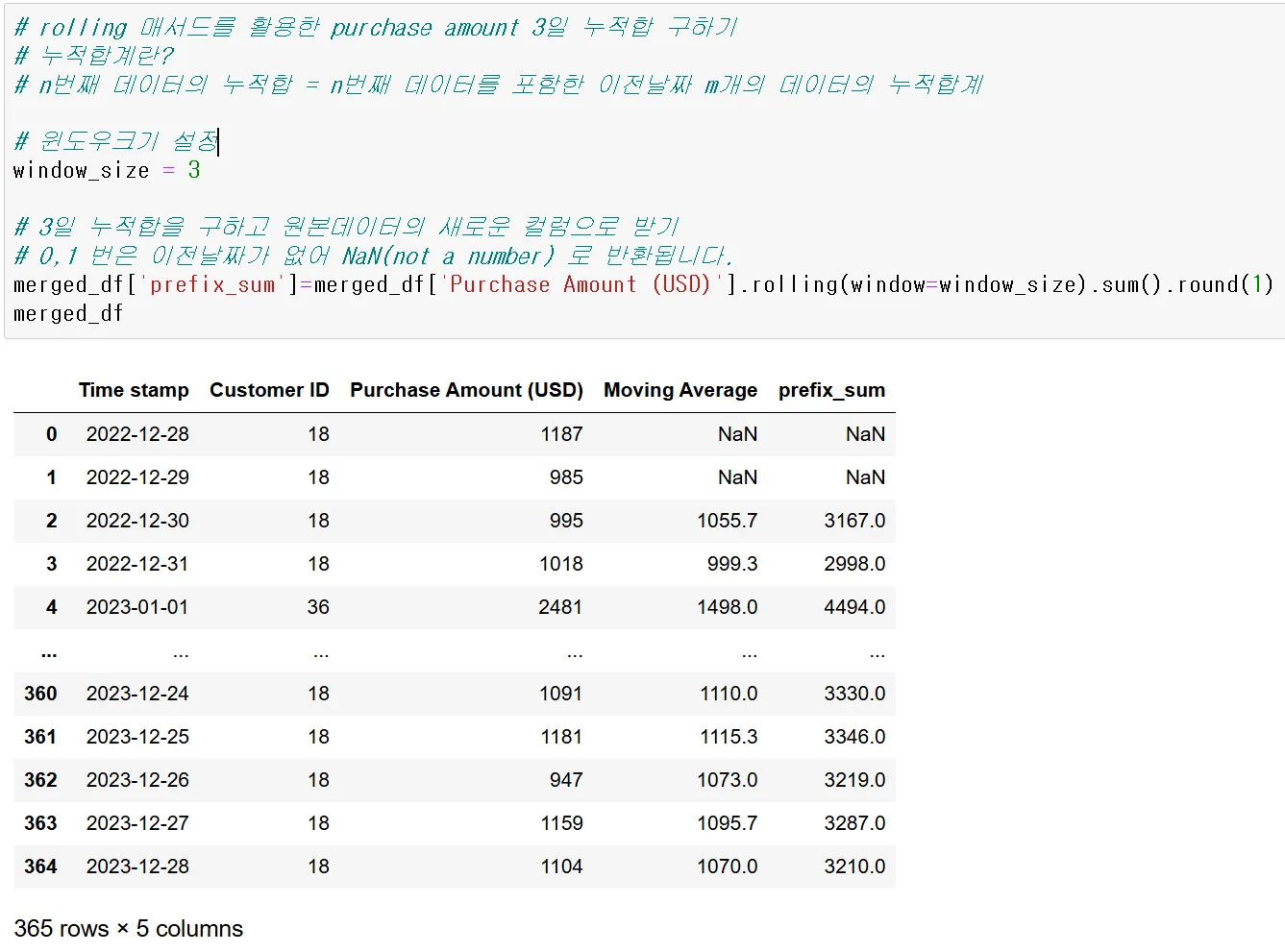
1187+985+995=3167
985+998+1018=2998
이런식으로 이동하면서 지정된 범위 안의 숫자를 연산해준다
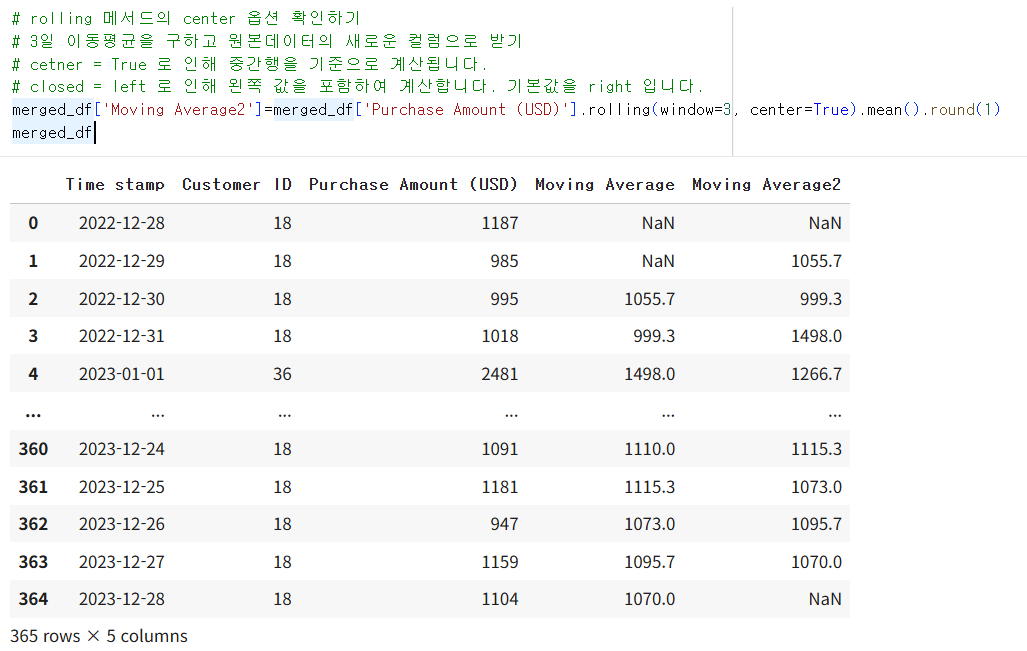
center=True로 설정할 경우 (1187+985+995)/3=1055.7이 995 옆이 아닌 985 옆에 생성된다.
# closed 옵션 비교하기
a = pd.DataFrame({'values': [10, 20, 30, 40, 50]})
# 현재 위치를 포함하여 데이터가 3개인 순간부터 계산
aa = a.rolling(window=3).sum() # closed='right'
# 현재 위치를 포함하지 않고 데이터가 3개인 순간부터 계산
b = a.rolling(window=3, closed='left').sum()
# right 와 동일하게 동작. 현재위치와 양쪽 경계를 포함하여 데이터가 3개인 순간부터 계산
c = a.rolling(window=3, closed='both').sum()
# 양쪽 경계와 현재위치를 사용하지않고 윈도우 크기 3을 만족할 경우에만 출력
# window 가 3인 상태에서, 양쪽 경계값을 제외하면 1개의 데이터가 남으므로 모든 값이 NaN으로 출력.
# 무의미
d = a.rolling(window=3, closed='neither').sum()
#결과표 한번에 보여주기
e = pd.concat([a,aa, b,c,d], axis=1)
e.columns = ['원본','right','left','both','neither']
e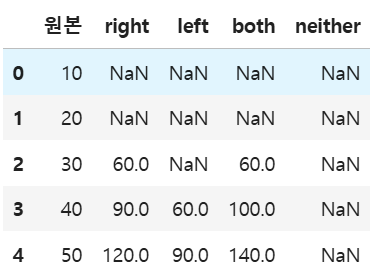
window는 최소한의 데이터 개수이다.
both가 자기 자신 포함 양쪽 데이터를 다 합친 개수이기 때문에 인덱스 1에 60이 생성되어야 할 것 같지만, window=3이기 때문에 인덱스 1은 최소 데이터 개수를 충족하지 못하여 NaN으로 뜬다
neither은 window에서 양쪽 데이터를 뺀 것인데, window=3이므로 양쪽을 빼면 자기 자신만 남는다. 그런데 rolling에서는 기본적으로 3개 이상의 데이터가 있어야 한다고 지정되어 있기 때문에 전부 NaN이 뜬다.
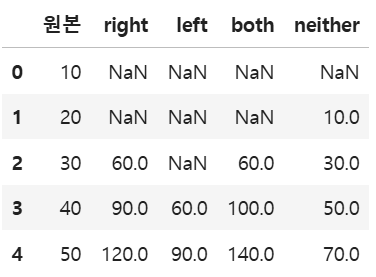
d = a.rolling(window=3, closed='neither', min_periods=1).sum() 코드를 수정하면 데이터가 뜨는 걸 볼 수 있다.
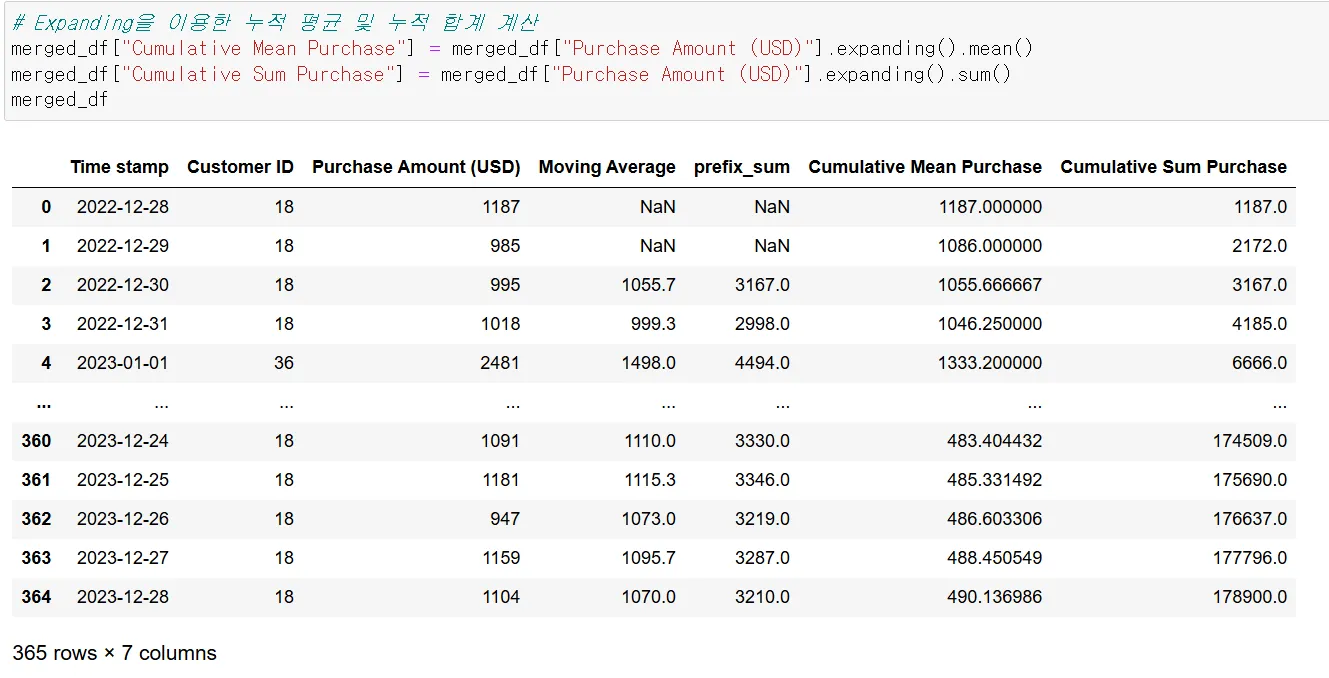
3. Expanding
Rolling은 범위를 지정해주지만 Expanding은 범위를 지정하지 않고 계속해서 값을 누적해서 연산을 해주는 메서드이다
- 주요 파라미터
- min_periods: 연산을 수행할 요소의 최소 갯수입니다. 이보다 작으면 NaN을 출력
- axis : 연산할 축방향 설정. 0(행) / 1(열)
- method: 연산방식. single(연산을 한 줄씩 수행) table(전체 테이블에 대해서 롤링수행). 기본값 single , 롤링 연산할 경우 numba 라이브러리 추가로 import 필요.
- 예시
-df.expanding(axis=1).sum()#열 기준으로 누적합 계산