머신러닝에 들어가기 전 데이터 표준화와 정규화에 대해 알아보았다.
나이대에 따른 연봉에 대해 분석하고자 할 때 나이대는 최대 100이지만 연봉은 70000000정도로 큰 차이가 난다.
이 때 컴퓨터는 큰 수를 더 중요한 factor로 인식하여 연봉에 가중치를 더 준다
하지만 연봉만큼 나이대도 중요하다
이러한 이유로 크게 차이가 나는 요소들의 값을 변환하거나 재조정하는 것이 표준화와 정규화이다
1. 데이터 표준화
표준화는 말 그대로 평균 0으로 재조정해주는 것이다.
모든 데이터가 평균이 0, 분산(표준편차) 1이므로 평균으로부터 얼마나 떨어져 있는지에 집중하게 만든다.
표준화는 각 변수의 스케일 차이를 없애서 모델이 모든 변수를 균형 있게 학습하도록 하기 위해서 진행한다
평균만 그대로 옮겨주는 것이기 때문에 데이터 분포도는 동일하고 정규성을 띄지 않으면 표준화 이후에도 정규성을 띄지 않는다
표준화 이전에 정규성을 만족하면 표준화 이후 평균 0, 분산 1을 가지는데 이를 표준정규분포라고 한다.
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
iris=load_iris()
iris_data=iris.data
iris_df=pd.DataFrame(data=iris_data, columns=iris.feature_names)
d1 = iris_df.mean().reset_index()
d2 = iris_df.var().reset_index().drop(['index'],axis=1)
d3 = pd.concat([d1, d2], axis=1)
d3.columns=['index','평균','분산']
d3
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
# fit()에 매개변수로 전달할 데이터 프레임은 2차원 이상의 값이어야 함
scaler.fit(iris_df)
# standard scaler 적용
iris_scaled=scaler.transform(iris_df)
## fit 과 transform 한번에 하기
# scaler.fit_transform(iris_df)
# iris_scaled가 배열 형태 -> 데이터 프레임으로 변환
iris_df_scaled=pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
d4 = iris_df_scaled.mean().reset_index()
d5 = iris_df_scaled.var().reset_index().drop(['index'],axis=1)
d6 = pd.concat([d4, d5], axis=1)
d6.columns=['index','scale_평균','scale_분산']
d7 = pd.concat([d3, d6], axis=1)
#중복된 열 중 첫 번째만 True로 해서 나머지는 제거
d7 = d7.loc[:, ~d7.columns.duplicated()]
d7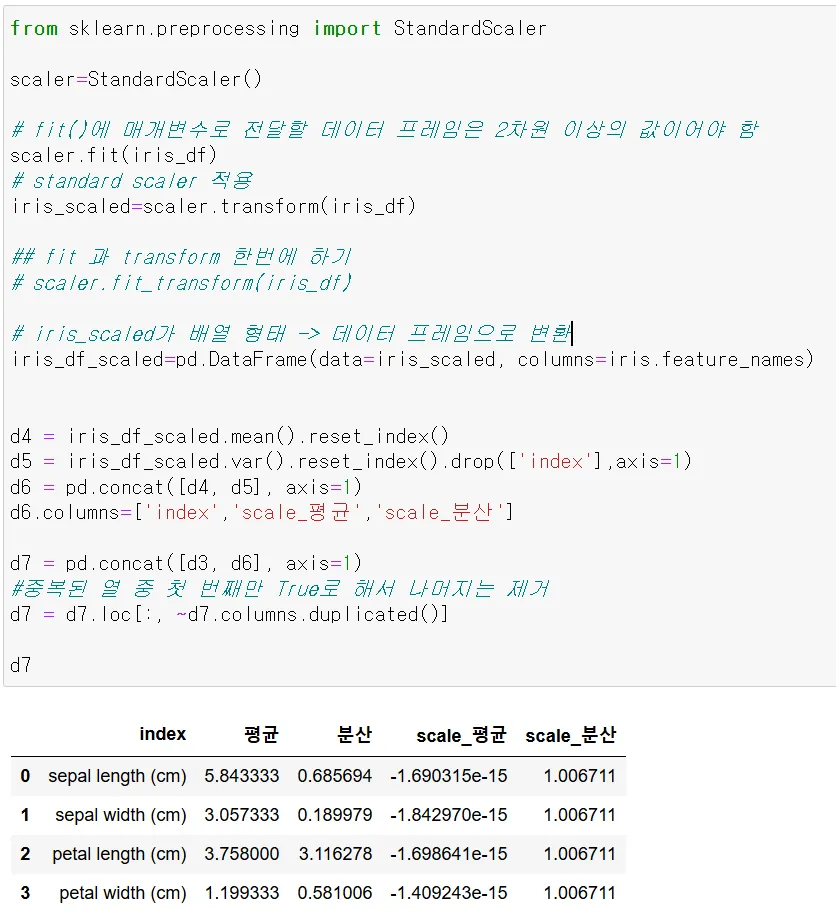
2. 데이터 정규화
데이터 정규화는 데이터 비율을 0-1로 압축하는 것이다.
최소값만 제외하고 크기만 줄여서 모든 데이터가 0-1 사이에 있도록 재조정하는 것이다.
정규화는 이상치에 매우 민감해서 이상치를 처리한 후에 진행해야 한다.
예를 들어 연봉이 대부분 3000-4000만원이지만 한 사람이 30억일 때 최소값만 제외하고 0-1 사이가 되도록 재조정을 하면 이상치와 대부분의 데이터가 간격이 매우 커져서 대부분의 데이터들은 0의 근사치가 된다.
# 라이브러리 import
import pandas as pd
import numpy as np
import scipy.stats as stats
from sklearn.preprocessing import MinMaxScaler
# 이상치 추가 전 데이터의 평균과 분산
y = np.arange(100)
scaled = MinMaxScaler().fit_transform(y.reshape(-1, 1))
print('이상치 추가 전의 데이터')
print('평균: ', scaled.mean(), '\n분산: ', scaled.std())
# 이상치 추가 후 데이터의 평균과 분산
y[9] = 10000
scaled = MinMaxScaler().fit_transform(y.reshape(-1, 1))
print('\n이상치 추가 후의 데이터')
print('평균: ', scaled.mean(), '\n분산: ', scaled.std())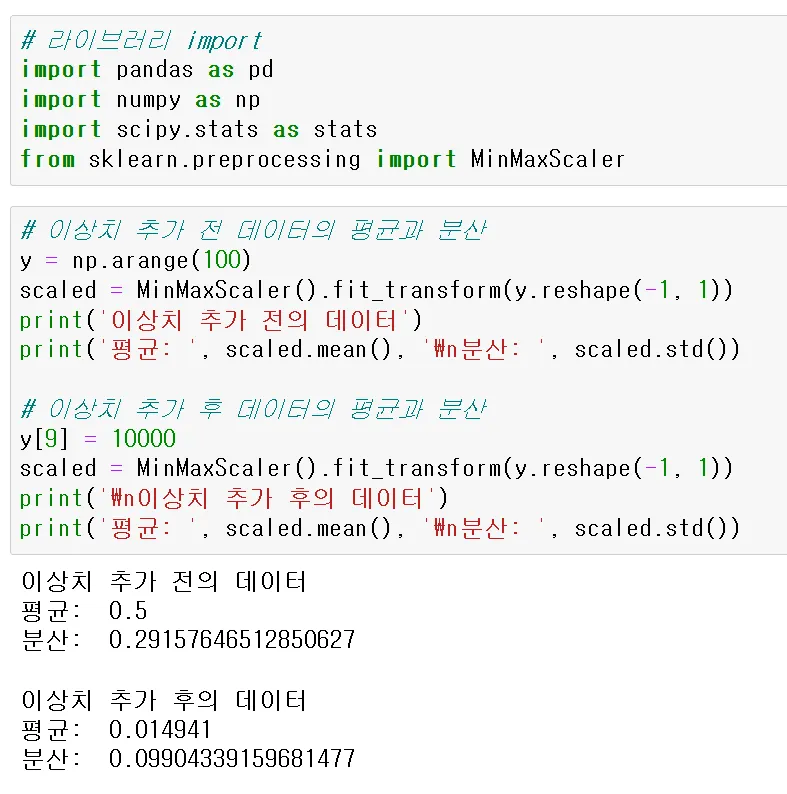
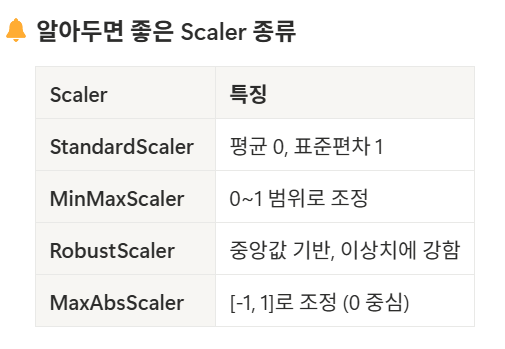
스케일러 종류에는 다음과 같은 것들이 있다.
로그변환
이상치를 처리하기 위해서 제거하는 방법도 있고 로그로 변환하는 방법도 있다.
로그 변환은 수치가 큰 데이터를 작제 줄여주는 방법이다.
로그 변환은 피쳐 분포가 한 쪽으로 치우쳐져 있는 경우에 유용하다.
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
df4 = pd.read_csv("stock_market.csv")
# 수치형 데이터만 필터링
mask = [c for c in df4.columns if df4[c].dtype != 'object']
num_df = df4[mask]
num_df = num_df[['Capital','PER','EPS','ROE','PBR']]
num_df.hist(bins=20, figsize=(10,10))
log_df = np.log(num_df)
log_df.hist(bins=20, figsize=(10,10))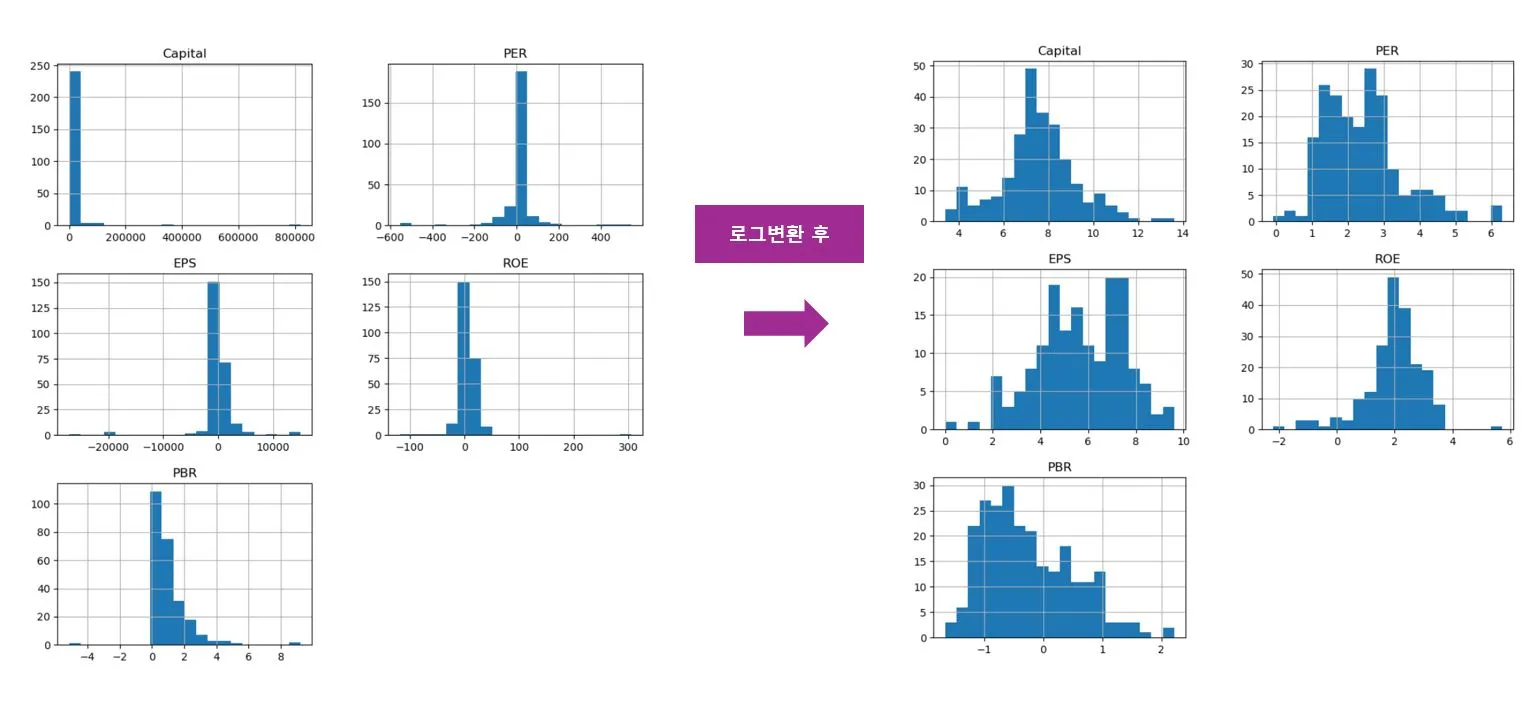
이런 식으로 데이터를 좀 더 차이가 뚜렷하게 볼 수 있다.
KNN
거리를 기반으로 유사한 경향을 보이는 각 데이터포인트를 묶어 분류하여 이상치를 처리할 수 있다.
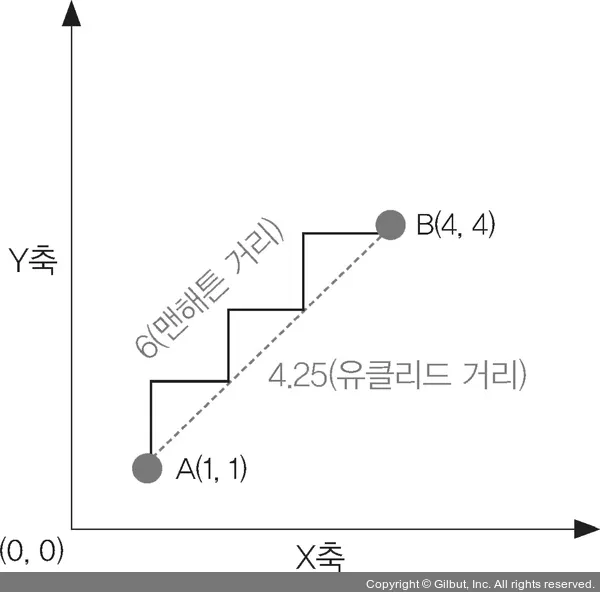
- 유클리드 거리(Euclidean Distance): K-NN 알고리즘에서 가장 일반적으로 사용하는 거리측정 방식 (절대거리 측정)
- 맨해튼 거리(Manhattan Distance): 2차원 평면 공간에서 두 점
p와q사이의 거리를 측정하는 방법 중 하나로, 두 점 사이의 수평 및 수직 이동 거리의 합으로 정의
from sklearn.neighbors import KNeighborsClassifier- 파라미터
- n_neighbors : 이웃의 개수를 지정 (default : 5)
- weights : 예측에 사용되는 가중치 uniform : 균일한 가중치 / distance : 거리의 역수로 가중치(default : uniform)
- algorithm : 가장 가까운 이웃에 계산하는데 사용되는 알고리즘(default : auto)
- p : 거리를 재는 방법 1:맨해튼거리 2:유클리드거리 (default : 2)
# 막간 이상치 처리방식 - KNN
# 수질 데이터를 기반으로 수질 상태를 분류하기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
df5.head(1).T
# 데이터 타입 확인
df5.info()
# 암모니아 컬럼에 '#NUM! 으로 기록된 값 제거
df5['ammonia'].value_counts()['#NUM!']
df5 = df5[df5['ammonia'].str.contains('#NUM!') == False]
# 결측값 처리
df5.dropna(inplace=True)
#df5.isnull().sum()
#데이터 타입 변경
df5['ammonia'] = pd.to_numeric(df5['ammonia'])
df5['is_safe'] = pd.to_numeric(df5['is_safe'])
# 독립변수(X)와 종속변수(y) 지정
columns = df5.columns
columns = [c for c in columns if c not in ['is_safe']]
# 예측하고싶은 값
# is_safe 컬럼이 1이면 안전한 물을, 0이면 안전하지 않은 물을 의미합니다.
y = df5['is_safe']
# 예측에 사용할 값
X = df5[columns]
# KNN 알고리즘 활용을 위한 TEST 셋과 TRAIN 셋 분리
# 훈련데이터셋: 모델이 학습할 데이터셋
# 테스트데이터셋: 모델 성능을 확인할 데이터셋
# 테스트데이터셋을 30% 로 지정
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
# scale
sc = StandardScaler()
# 적용시킬 데이터 준비
sc.fit(X_train)
# 훈련데이터셋과 테스트 데이터셋에 적용
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
# KNN알고리즘 훈련 데이터셋에 적용
knn = KNeighborsClassifier()
knnc = knn.fit(X_train,y_train)
# 테스트 데이터셋 예측
y_pred_knnc = knnc.predict(X_test)
y_pred_knnc
# 결과 확인
# Precision(정밀도): 예측한 클래스 중 실제로 해당 클래스인 데이터의 비율
# Recall(재현율): 실제 클래스 중 예측한 클래스와 일치한 데이터의 비율
# F1-score: Precision과 Recall의 조화평균
# Support: 각 클래스의 실제 데이터 수
# 정답(y_test) 과 예측값(y_pred_knnc)에 대한 리포트 생성
# accuracy = 0.86
# 0 레이블: 안전하지 않은 물에 대한 예측지표
# 1 레이블: 안전한 물에 대한 예측지표
# 현재 데이터셋의 경우, 데이터 불균형으로 인해 안전한 물에 대한 예측지표가 낮게 학습되었습니다.
# 1 레이블의 recall 이 0.11 이라는 것은 실제로는 안전하지만, 안전하지 않다고 예측한 경우가 많다는 의미.
# 이렇게 데이터가 불균형을 이룰 때는 F1-score(precision 과 Recall 의 조화평균)을 보면 됩니다. :- )
# 그래도 1 레이블의 f1-score 는 0.17 입니다.
print(classification_report(y_test, y_pred_knnc))