7.3 계층적 클러스터링
1. 용어 정리
- 덴드로그램(dendrogram): 레코드들, 그리고 레코드들이 속한 계측적 클러스터를 시각적으로 표현
- 거리(distance): 한 레코드가 다른 레코드들과 얼마나 가까운지를 보여주는 측정 지표
- 비유사도(dissimilarity): 한 클러스터가 다른 클러스터들과 얼마나 가까운지를 보여주는 측정 지표
7.3.1 간단한 예제
1. 두 가지 기본 구성 요소 기반
- 두 개의 레코드 i와 j 사이의 거리를 측정하기 위한 거리 측정 지표
- 두 개의 클러스터 A와 B 사이의 차이를 측정하기 위한, 각 클러스터 구성원 간의 거리 d를 기반으로 한 비유사도 측정 지표 D
7.3.2 덴드로그램
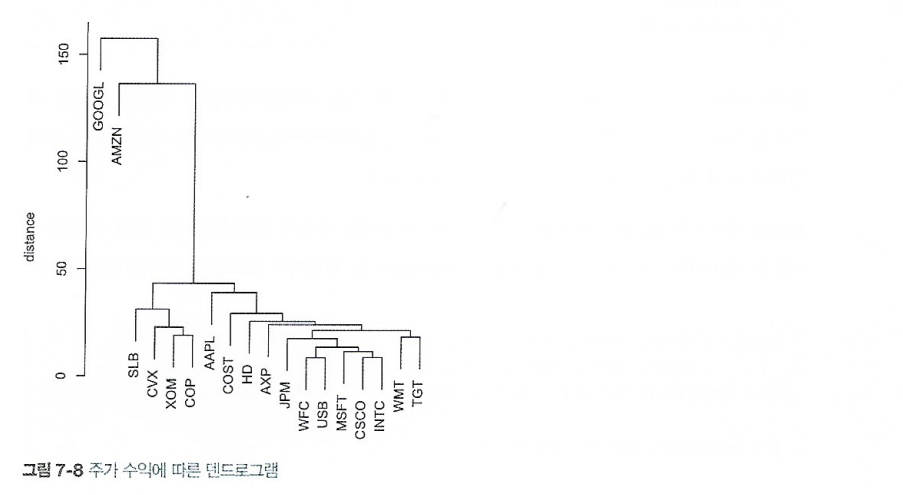
트리의 잎은 각 레코드를 의미한다. 트리의 가지 길이는 해당 클러스터 간의 차이 정도를 나타낸다. 구글과 아마존에 대한 수익률은 서로 다르고 다른 주식에 대한 수익률과도 상당히 다른 것을 볼 수 있다. 다른 주식들은 자연스럽게 그룹을 형성한다. 석유 관련주들(SLB, CVX, XOM, COP)은 자신들의 클러스터가 있고 애플(AAPL)은 독자적이며, 나머지는 서로 비슷하다.
7.3.3 병합 알고리즘
- 데이터의 모든 레코드에 대해, 단일 레코드로만 구성된 클러스터들로 초기 클러스터 집합을 만든다.
- 모든 쌍의 클러스터 k, l 사이의 비유사도 D를 계산한다.
- D에 따라 ㄱ가장 가까운 두 클러스터를 병합한다.
- 둘 이상의 클러스터가 남아 있으면 2단게로 다시 돌아간다. 그렇지 않고 클러스터가 하나 남는다면 알고리즘을 멈춘다.
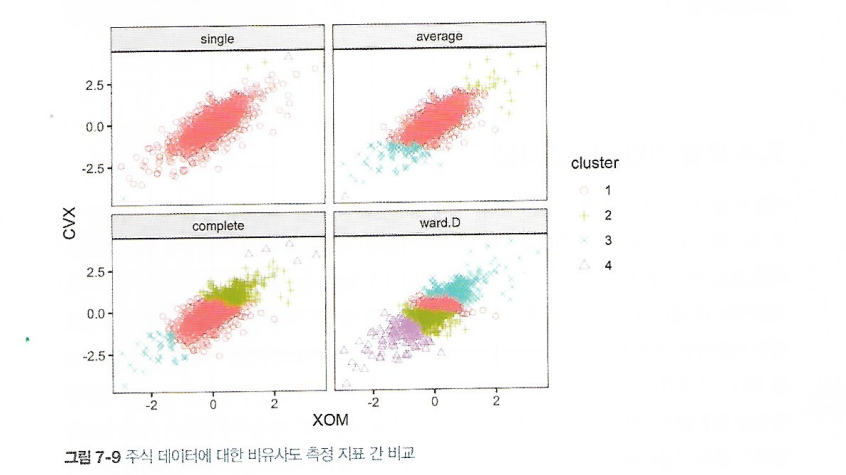
7.3.4 비유사도 측정
1. 비유사도를 특정하는 네 가지 일반적인 지표
- 완전연결
- 단일연결
- 평균연결
- 최소분산
2. 주식 데이터에 대한 비유사도 측정 지표 간 비교
피터 브루스, 앤드루 브루스의 <데이터 과학을 위한 통계(2판): 데이터 분석에서 머신러닝까지 50가지 핵심 개념> 을 읽고 정리한 내용입니다.

My_Spielraum