7.2 k-평균 클러스터링
1. 용어 정리
- 클러스터(cluster): 서로 유사한 레코드들의 집합
- 클러스터 평균(cluster mean): 한 클러스터 안에 속한 레코드들의 평균 벡터 변수
- k: 클러스터의 개수
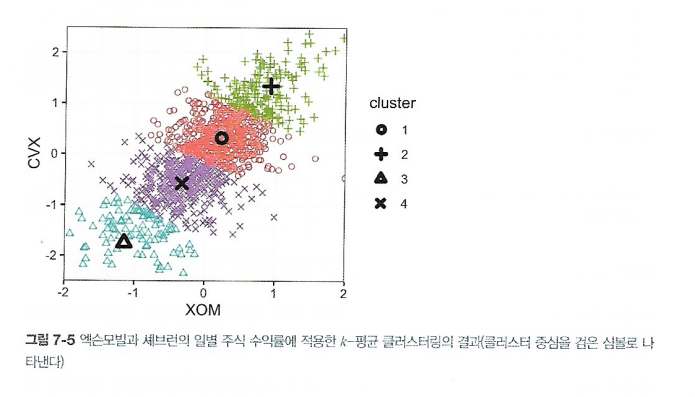
7.2.1 간단한 예제
- 클러스터의 중심 (클러스터내에 존재하는 점들의 평균)

- 클러스터 내부의 제곱합

- k-평균 할당법: 다음의 식이 최소가 되도록

- 시각화
7.2.2 k-평균 알고리즘
- 각 레코드를 거리가 가장 가까운 평균을 갖는 클러스터에 할당한다.
- 새로 할당된 레코드들을 가지고 새로운 클러스터 평균을 계산한다.
7.2.3 클러스터 해석
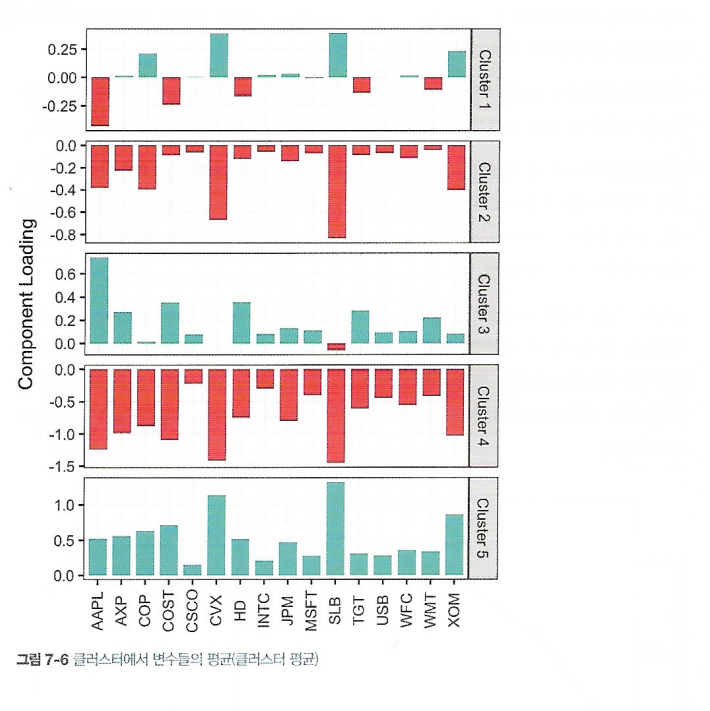
예를 들어 클러스터 4와 5는 각각 주식시장이 내리고 오른 날을 의미한다. 클러스터 2와 3은 각각 에너지 관련 주식이 내린 날과 소비재 주식이 오른 날의 특징을 보여준다. 마지막으로 클러스터 1은 에너지 주식은 오르고 소비재 주식은 내린 날을 보여준다.
클러스터 평균 그래프가 주성분 분석(PCA)에서 봤던 부하 그래프와 매우 비슷하다. PCA와 가장 다른 점은 클러스터 평균에서는 부호가 매우 중요한 의미를 갖는다는 점이다. PCA에서는 변동성의 주요 방향을 찾는 것이 목적이었다면, 클러스터 분석에서는 서로 가까운 위치에 있는 레코드들의 그룹을 찾는 것이 목적이다.
7.2.4 클러스터 개수 선정
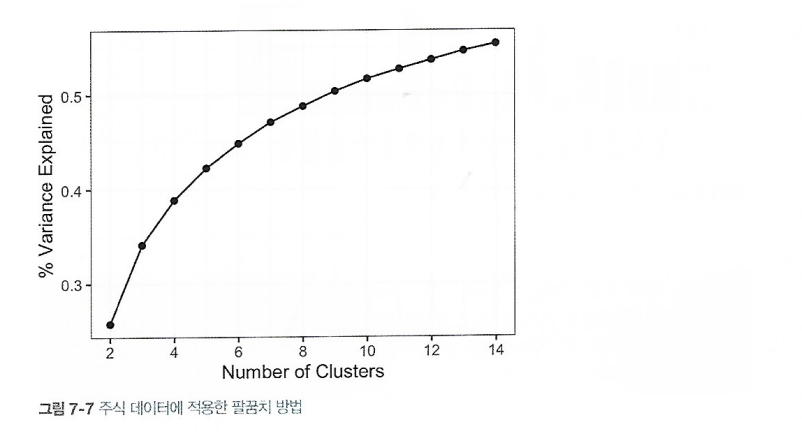
- '최상의' 클러스터 개수를 찾는 딱 한가지 표준화된 방법은 없다.
- 팔꿈치 방법은 언제 클러스터 세트가 데이터의 분산의 '대부분'을 설명하는지를 알려준다.
피터 브루스, 앤드루 브루스의 <데이터 과학을 위한 통계(2판): 데이터 분석에서 머신러닝까지 50가지 핵심 개념> 을 읽고 정리한 내용입니다.

My_Spielraum