2.7 긴 꼬리 분포
1. 용어 정리
- 꼬리(tail): 적은 수의 극단값이 주로 존재하는, 도수분포의 길고 좁은 부분
- 왜도(skewness): 분포의 한쪽 꼬리가 반대쪽 다른 꼬리보다 긴 정도
2. 긴 꼬리 분포
- 일반적으로 데이터는 정규분포를 따르지 않는다.
- 대칭 및 비대칭 분포 모두 긴 꼬리를 가진다.
- 분포의 꼬리 = 양 극한값
3. 실습 예제
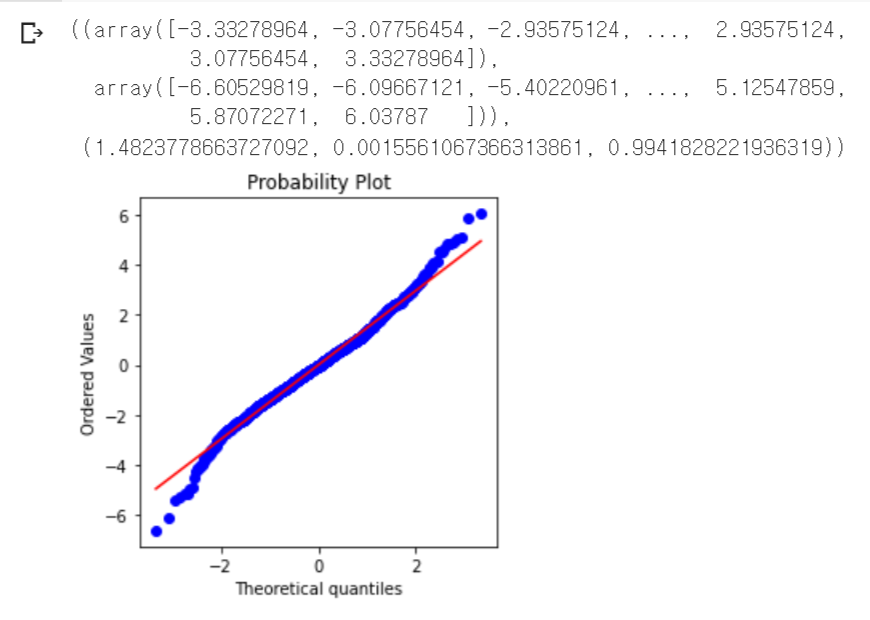
- 코드
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas as pd
import numpy as np
sp500_px = pd.read_csv('/content/drive/MyDrive/데이터과학을위한통계/data/sp500_data.csv')
nflx = sp500_px.NFLX
nflx = np.diff(np.log(nflx[nflx > 0]))
fig, ax = plt.subplots(figsize = (4, 4))
stats.probplot(nflx, plot = ax)- 결과
피터 브루스, 앤드루 브루스의 <데이터 과학을 위한 통계(2판): 데이터 분석에서 머신러닝까지 50가지 핵심 개념> 을 읽고 정리한 내용입니다.

My_Spielraum