0.Summary
- 목적: TTS(음성합성) 평가 데이터의 품질 지표(평균/표준편차)와 신뢰도(Kappa/Agreement)를 다차원으로 분석
- 핵심 기능:
- 다차원 분석: 전체, 모델별, 문항(ID)별, 도메인/카테고리별 자동 그룹화 분석
- 신뢰도 검증: Fleiss' Kappa 및 Agreement를 통한 평가자 간 합의 수준 측정
- 의사결정 지원: 분석 수치에 따른 자동 조치 가이드(Action Guide) 생성
- 기대 효과: 평가 데이터의 객관성 확보 및 불성실 평가자/모호한 문항의 조기 선별
예시 이미지
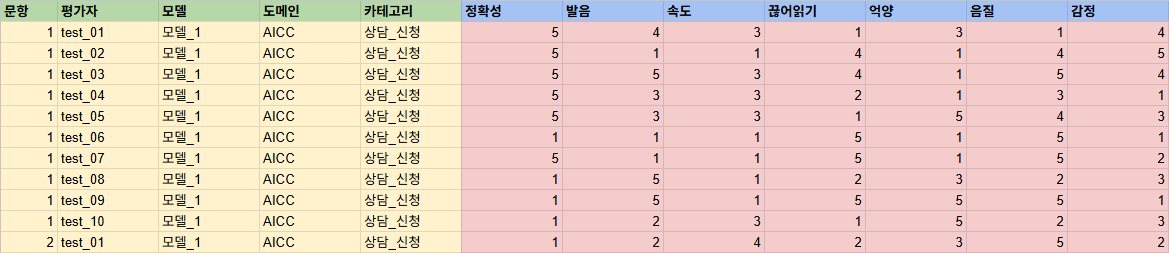
입력 xlsx, csv 형식
- 구분자 헤더 : 문항, 평가자, 모델, 도메인 등 (녹색 영역)
- 구분자 입력값 : (노란색 영역)
- 평가지표 헤더 : 정확성, 발음, 속도, 끊어읽기 등 (파란색 영역)
- 평가지표 입력값 : (빨간색 영역)

입력값
- ID_COLUMN
- RATER_COLUMN
- GROUP_INPUT
- 문항, 평가자 열의 이름과 그 외 구분자로 사용할 헤더 목록을 입력
- 해당 목록에 포함되지 않은 헤더는 평가지표로 간주
- RESULT_FILE
3. Install Libraries
#@title 라이브러리 설치 및 확인
import importlib
import subprocess
import sys
def install_if_missing(package_name, import_name=None):
if import_name is None:
import_name = package_name
try:
importlib.import_module(import_name)
# print(f"✅ {package_name} 이(가) 이미 설치되어 있습니다.")
except ImportError:
print(f"Installing {package_name}...")
# Colab 환경에서 시스템 호출을 통해 설치
subprocess.check_call([sys.executable, "-m", "pip", "install", package_name])
print(f"✅ {package_name} 설치 완료.")
# 설치가 필요한 라이브러리 목록 (패키지명, 임포트명)
packages = [
("openpyxl", "openpyxl"),
("statsmodels", "statsmodels"),
("xlsxwriter", "xlsxwriter")
]
for pkg, imp in packages:
install_if_missing(pkg, imp)
import pandas as pd
import numpy as np
import io
- 필수 라이브러리, 패키지
openptxl, statsmodel , xlsxwriter 설치
openptxl : 엑셀(xlsx) 파일 불러와 Data Frame으로 변환statsmodel : 빈도 행렬을 통해 Fleiss-Kappa, Agreement 계산 함수 사용xlsxwriter : 엑셀(xlsx) 파일 내용 수정, 쓰기
- 설치 확인 후 설치되지 않은 라이브러리, 패키지만 선택적으로 설치
4. Data Frame 변환
업로드 된 파일 불러오기
# 1. 파일 확장자 확인 및 데이터 로드
if FILE_PATH and os.path.exists(FILE_PATH):
# 파일 확장자에 따라 읽기 방식 결정
if FILE_PATH.endswith('.csv'):
df = pd.read_csv(FILE_PATH)
elif FILE_PATH.endswith(('.xls', '.xlsx')):
df = pd.read_excel(FILE_PATH)
else:
print("❌ 지원하지 않는 파일 형식입니다. (CSV 또는 Excel 파일 필요)")
df = pd.DataFrame() # 빈 데이터프레임 생성
else:
print("❌ 파일을 업로드하거나 올바른 경로를 입력해주세요.")
df = pd.DataFrame()
- 파일 확장자에 따라 파일 불러와 Data Frame(
df) 형식으로 변환해 향후 활용에 용이하게 함
입력값 전처리
if not df.empty:
# (1) 그룹 컬럼 리스트화 (쉼표 분리 및 공백 제거)
GROUP_COLUMNS = [x.strip() for x in GROUP_INPUT.split(',') if x.strip()]
# (2) 구분자(식별자) 목록 통합
# 사용자가 입력한 ID, 평가자, 그룹 컬럼들을 모두 모음
excluded_cols = [ID_COLUMN, RATER_COLUMN] + GROUP_COLUMNS
# (3) 평가지표(Metrics) 자동 추출
# 전체 컬럼 중 구분자 영역을 제외한 나머지를 모두 평가지표로 간주
metric_cols = [col for col in df.columns if col not in excluded_cols and "Unnamed" not in col]
# (4) 데이터 타입 정리 (평가지표는 숫자형으로 변환)
for col in metric_cols:
df[col] = pd.to_numeric(df[col], errors='coerce')
- 데이터 프레임을 정상적으로 불러온 경우
GROUP_COLUMNS 리스트화
- 예시)
GROUP_COLUMNS에 "모델, 도메인, 카테고리" 입력
리스트로 변형 : GROUP_COLUMNS = ["모델", "도메인", "카테고리"]
ID_COLUMN, RATER_COLUMN에서 입력받은 값들도 모아 excluded_cols 구분자 리스트를 구성
- 예시)
ID_COLUMN = "문항", RATER_COLUMN = "평가자"로 입력
리스트로 변형 및 통합 : excluded_cols = ["문항","평가자","모델", "도메인", "카테고리"]
- 나머지 열의 요소는 모두 평가지표로 간주
- 예시) 기존 헤더 목록 :
[문항,평가자,모델,도메인,카테고리,정확성,발음,속도,끊어읽기...]
구분자 제외 후 평가지표만 추출한 목록 : [정확성,발음,속도,끊어읽기...]
- 평가지표 열의 요소를 전부 숫자형으로 변환
5. Fleiss-kappa & Agreement 측정
평균, 표준편차, kappa 산출 통합 함수
def get_combined_metrics(target_df, group_id_col, metric_col):
try:
# 데이터 정제
valid_df = target_df[[group_id_col, metric_col]].dropna()
if valid_df.empty: return np.nan, np.nan, np.nan, np.nan, 0
# [통계] 평균 및 표준편차
mean_v = round(valid_df[metric_col].mean(), 4)
std_v = round(valid_df[metric_col].std(), 4)
# [Kappa] 빈도 행렬 생성 (행: 평가대상, 열: 점수범주)
count_matrix = pd.get_dummies(valid_df[metric_col]).groupby(valid_df[group_id_col]).sum().to_numpy()
kappa = np.nan
# 대상(Subject)이 2개 이상이고 점수 종류가 2개 이상일 때 Fleiss' Kappa 산출
if count_matrix.shape[0] >= 2 and count_matrix.shape[1] >= 2:
kappa = round(fleiss_kappa(count_matrix, method='fleiss'), 4)
elif count_matrix.shape[0] >= 2 and count_matrix.shape[1] == 1:
kappa = 1.0 # 모든 대상에 대해 모든 평가자가 동일 점수를 준 경우
agreement = np.nan
# 일치도(Agreement) 계산 로직
# n_raters가 2명 이상이어야 쌍(pair)을 지어 일치도를 구할 수 있음
if count_matrix.shape[0] >= 2:
n_raters = count_matrix[0].sum()
if n_raters >= 2:
# 각 문항별 일치도 P_i 계산: (sum(n_ij^2) - n_i) / (n_i * (n_i - 1))
numerator = np.sum(count_matrix**2, axis=1) - n_raters
denominator = n_raters * (n_raters - 1)
p_i = numerator / denominator
agreement = round(np.mean(p_i), 4) # 전체 문항에 대한 평균 일치도
return mean_v, std_v, kappa, agreement, len(valid_df)
except Exception as e:
print(f"Error in {metric_col} for {group_id_col}: {e}") # 에러 메시지 출력
return np.nan, np.nan, np.nan, np.nan, 0
Fleiss-kappa 측정
# [Kappa] 빈도 행렬 생성 (행: 평가대상, 열: 점수범주)
count_matrix = pd.get_dummies(valid_df[metric_col]).groupby(valid_df[group_id_col]).sum().to_numpy()
kappa = np.nan
# 대상(Subject)이 2개 이상이고 점수 종류가 2개 이상일 때 Fleiss' Kappa 산출
if count_matrix.shape[0] >= 2 and count_matrix.shape[1] >= 2:
kappa = round(fleiss_kappa(count_matrix, method='fleiss'), 4)
elif count_matrix.shape[0] >= 2 and count_matrix.shape[1] == 1:
kappa = 1.0 # 모든 대상에 대해 모든 평가자가 동일 점수를 준 경우
- Fleiss-kappa 측정을 위해서는 빈도 행렬을 구성해야 함
metric_col에 포함된 평가 지표에 해당하는 데이터를 순차적으로 가져옴
- 예시)
metric_col = [정확성,발음,속도,끊어읽기...]인 경우 정확성 항목에 관한 평가 데이터를 가져옴
- 점수를 열로 가지는 표로 재구성해, 각 평가자의 점수에 해당하는 열에
1로 표기
- 예시)
정확성에 대한 점수 구성이 [4,2,1,3,5]인 경우 아래와 같이 행렬 구성
이후 묶고자 하는 구분자를 기준으로 변수들을 한 그룹으로 묶음
| 평가자 | 1 | 2 | 3 | 4 | 5 |
|---|
| test_01 | 0 | 0 | 0 | 1 | 0 |
| test_02 | 0 | 1 | 0 | 0 | 0 |
| test_03 | 1 | 0 | 0 | 0 | 0 |
| test_04 | 0 | 0 | 1 | 0 | 0 |
| test_05 | 0 | 0 | 0 | 0 | 1 |
| ... | | | | | |
- 구분자를 기준으로 묶은 변수 그룹을 합쳐 해당 점수의 빈도 행렬로 변환
- 예시) 문항을 기준으로 위의 행렬을 빈도 행렬로 변환한 결과
statsmodels이 계산할 수 있도록 문자열 영역을 제거하고 숫자 값만 행렬로 전달- 어떤 평가자가 몇 점을 주었는지는 중요하지 않고, 전체에서 각 점수가 어떤 빈도로 등장했는지가 중요함
count_matrix.shape[0] >= 2 and count_matrix.shape[1] >= 2
- 구분자에 해당하는 평가 요소가 2개 이상인지, 발생한 점수의 종류가 2개 이상인지 확인
구분자 : 평가요소 = 문항 : [1번, 2번, 3번...]
- 평가 요소가 하나라면 비교할 수 있는 다른 대상이 없어 kappa를 구할 수 없음
- Fleiss-kappa는 평가 대상이 다름에도 평가가 일관되게 이루어졌는지를 확인하기 위함이므로 단일 항목에 대한 정보로는 평가가 일관되게 이루어졌는지를 정의할 수 없음
- 점수의 종류가 1개라면 모두 통일된 상태이므로 kappa가
1임
Agreement 측정
agreement = np.nan
# 일치도(Agreement) 계산 로직
# n_raters가 2명 이상이어야 쌍(pair)을 지어 일치도를 구할 수 있음
if count_matrix.shape[0] >= 2:
n_raters = count_matrix[0].sum()
if n_raters >= 2:
# 각 문항별 일치도 P_i 계산: (sum(n_ij^2) - n_i) / (n_i * (n_i - 1))
numerator = np.sum(count_matrix**2, axis=1) - n_raters
denominator = n_raters * (n_raters - 1)
p_i = numerator / denominator
agreement = round(np.mean(p_i), 4) # 전체 문항에 대한 평균 일치도
- 일치도 계산도 동일하게 빈도 행렬을 사용함
- 점수 빈도 행렬의 첫번째 열의 모든 빈도 값을 합치면 전체 평가자 수를 알 수 있음
numerator = np.sum(count_matrix**2, axis=1) - n_raters
- 각 빈도 값을 제곱한 뒤, 다 더해서 평가자 수를 뺌
- 같은 점수를 선택한 사람들끼리 짝을 맺을 수 있는 경우의 수를 구함
denominator = n_raters * (n_raters - 1)
- 발생할 수 있는 모든 쌍의 개수를 구함(가능한 모든 쌍이므로 순서/방향을 고려한 개수)
agreement = round(np.mean(p_i), 4)
같은 점수 짝을 맺을 경우의 수/가능한 모든 쌍의 개수 의 평균을 구함
- 평가 결과가 보여주는 평균적인 합의 수준을 보여줌
6. 분석 시나리오 세팅
# (차원 이름, 그룹화할 컬럼, Kappa 계산 시 기준이 될 대상 컬럼)
scenarios = [('전체', [], 'id_model_pair')] # 전체는 ID+모델 조합을 대상으로 봄
# 단일 구분자별 분석 (id, 모델, 도메인, 카테고리 등)
for col in [ID_COLUMN] + GROUP_COLUMNS:
# ID별 분석일 때는 '모델'을 대상으로 일치도를 보고, 그 외에는 'ID'를 대상으로 봄
sub_target = '모델' if col == ID_COLUMN else ID_COLUMN
scenarios.append((f'{col}별', [col], sub_target))
# 조합별 분석 (사용자 입력 그룹 전체 조합)
if len(GROUP_COLUMNS) > 1:
scenarios.append(('조합별(Group)', GROUP_COLUMNS, ID_COLUMN))
# 4. 분석 실행 루프
final_report = []
# 전체 분석용 임시 식별자 생성
df['id_model_pair'] = df[ID_COLUMN].astype(str) + "_" + df['모델'].astype(str)
for sc_name, sc_cols, sub_col in scenarios:
if not sc_cols: # 전체 분석
for m in metric_cols:
mean, std, kap, agr, n = get_combined_metrics(df, sub_col, m)
final_report.append({
'분석차원': sc_name, '대상': 'Total', '지표': m,
'평균': mean, '표준편차': std, 'Kappa': kap, '일치도': agr, '샘플수': n
})
else: # 그룹/구분자별 분석
grouped = df.groupby(sc_cols)
for name, group_df in grouped:
label = name if isinstance(name, str) else "-".join(map(str, name))
for m in metric_cols:
mean, std, kap, agr, n = get_combined_metrics(group_df, sub_col, m)
final_report.append({
'분석차원': sc_name, '대상': label, '지표': m,
'평균': mean, '표준편차': std, 'Kappa': kap, '일치도': agr, '샘플수': n
})
# 5. 결과 정리 및 최종 검증
report_df = pd.DataFrame(final_report)
# 지표 열에 구분자 명칭이 들어간 행 강제 제거 (순수 지표만 남김)
report_df = report_df[~report_df['지표'].isin(all_identifiers)]
print(f"✅ 분석 완료!")
display(report_df.head(20))
전체 분석
- 전체 분석시에는
ID+모델 조합을 구분자로 사용해 지표를 구함
- 하나의 문항에 대해 3개의 모델이 있는 조건이므로 하나의 고유한 요소는
ID+모델이 조합되어야 구분할 수 있음
단일 구분자 분석
- 각 구분자를 기준으로 지표를 계산
- 문항별 분석일 때는 '모델'을 대상으로 일치도를 보고, 그 외에는 '문항'을 대상으로 봄
조합 구분자 분석
- 구분자 조합 전체를 합친 조합 구분자를 기준으로 지표를 계산
분석 시나리오 분리 이유
- 각 구분자에 따라 Fleiss-kappa와 Agreement를 따로 계산함으로써, 어느 요소에서 평가 결과의 불일치가 발생하는지 파악하기 쉽게 하고자 함
- 특정 구분자에서 불일치가 반복된다면, 해당 구분자에 맞춘 대처가 가능
- 모델 : 모델 성능이 월등하여 전반적으로 점수가 높게 치우친 경우, 아주 적은 특이값으로도 kappa가 낮게 나올 수 있음
- 평가자 : 평가자가 다른 평가자와 다른 기준을 적용하고 있거나, 가이드 숙지가 미흡할 수 있음
7. 지표에 따른 가이드
def get_action_guide(row):
kap = row.get('Kappa')
agr = row.get('일치도')
# 데이터가 없는 경우 처리
if pd.isna(kap) or pd.isna(agr):
return "-"
# 1. 일치도 높음 / Kappa 음수 또는 매우 낮음 (Prevalence 현상)
if agr >= 0.8 and kap <= 0.1:
return "[특이값 확인] 대세와 다른 소수 의견 존재. 단순 실수인지 또는 타인이 놓친 결함 발견인지 해당 평가자 면담 필요."
# 2. 일치도 중간 / Kappa가 0에 가까움 (Bimodal 분리)
elif 0.35 <= agr <= 0.55 and kap <= 0.1:
return "[가이드 수정] 의견이 두 집단으로 팽팽하게 갈림. 기준 모호성 확인 및 가이드라인 구체화 필요."
# 3. 일치도 낮음 / Kappa가 어느 정도 존재 (난이도 높음)
elif agr < 0.4 and 0.1 < kap <= 0.4:
return "[난이도 높음] 전반적으로 의견이 분산되었으나 일부 합의 존재."
# 4. 일치도 매우 낮음 / Kappa 0 이하 (무작위 수준)
elif agr < 0.3 and kap <= 0:
return "[신뢰 불가] 무작위 평가 수준. 데이터 분석 가치 낮음."
return "정상"
# '조치 가이드' 컬럼 생성
report_df['조치 가이드'] = report_df.apply(get_action_guide, axis=1)
# 파일 저장
output_path = f"{RESULT_FILE}_통합분석.csv"
report_df.to_csv(output_path, index=False, encoding='utf-8-sig')
print(f"✅ 분석 및 가이드 생성 완료! '{output_path}' 파일에 조치사항이 포함되었습니다.")
display(report_df.head(20))
Fleiss-kappa / Agreement에 따른 가이드
| Fleiss-kappa | Agreement | 조치 가이드 |
|---|
| 낮음(0.1 이하 혹은 음수) | 높음(0.8 이상) | 대세와 다른 소수의견 존재 |
| 낮음(0) | 중간(0.4~0.5) | 평가 결과가 두 집단으로 갈림 |
| 약간 높음(0.4 이상) | 낮음(0.4 이하) | 전반적인 의견 분산이 있으나 일부 합의 존재 |
| 낮음(0) | 낮음(0.3 이하) | 무작위 수준임 |
- 각 지표에 따른 조치 가이드를 제공해 평가 결과를 반영한 의사결정을 도움
