중간고사
형식: 웹 페이지 크롤링 > pandas > 데이터 정보를 이용(min/max, 특정 속성에 대해 count 등)
정적 웹페이지 크롤링(hollys)
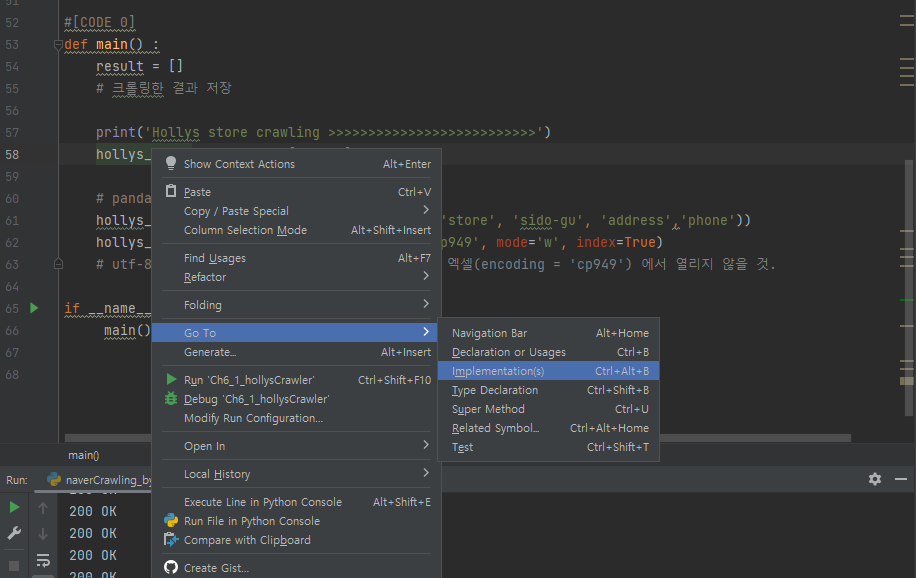
main 함수의 결과값을 저장하는 result 변수가 파라미터가 되는 hollys_store 함수를 우클릭한후 Go To를 누른 후 Imprementation을 누르면
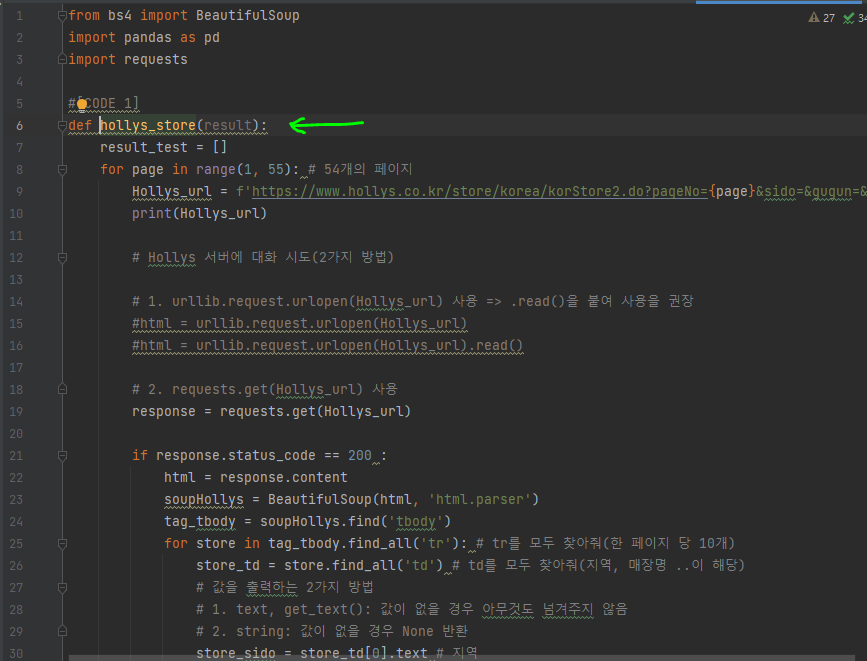
해당 함수로 이동할 수 있다.
할리스 매장검색(https://www.hollys.co.kr/store/korea/korStore2.do) 페이지의 매장 정보를 크롤링할 예정이다.
웹 페이지의 html 태그를 분석하자.
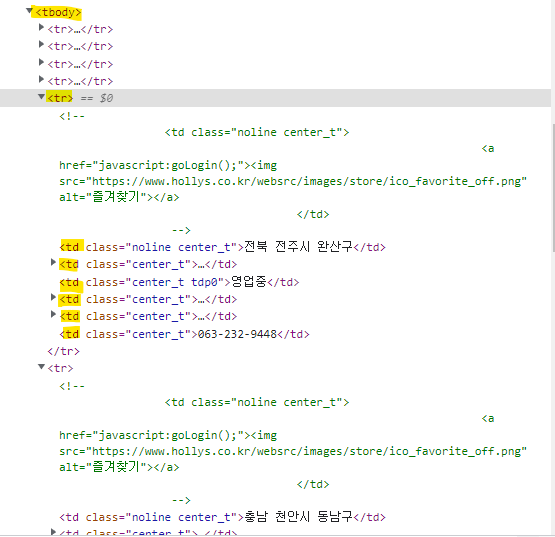
<tbody>태그 속 10마리의 자식태그인 <tr>태그들이 있고, tr태그 속 6마리의 <td>라는 자식 태그가 있는 구조다!
따라서, 10개의 tr태그들을 뽑아낸 후에 다시 그 속에 td를 뽑으면 되겠다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=1&sido=&gugun=&store='
response = requests.get(url)
if response.status_code == 200:
html = response.content # html 정보를 가져옴
soup = BeautifulSoup(html, 'html.parser')
tbody = soup.find_all('tbody') # tbody가 몇갠지 확인을 먼저하기
print(len(tbody))
else :
print(response.status_code)결과는 1이다.
따라서 find_all을 하기보다는(1개 요소이기에, 리스트로 출력하는것이 불편) find을 이용하자.
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=1&sido=&gugun=&store='
response = requests.get(url)
if response.status_code == 200:
html = response.content # html 정보를 가져옴
soup = BeautifulSoup(html, 'html.parser')
tbody = soup.find('tbody') # tbody가 몇갠지 확인을 먼저하기
tr_list = tbody.find_all('tr')
print(len(tr_list))
else :
print(response.status_code)
전체 실습코드
import requests
from bs4 import BeautifulSoup
import pandas as pd
results = []
for pageNum in range(1, 55):
# 문자열 fotmating: f-string 이용
url = f'https://www.hollys.co.kr/store/korea/korStore2.do?pageNo={pageNum}&sido=&gugun=&store='
response = requests.get(url)
#print('-'*20, pageNum)
if response.status_code == 200:
html = response.content
soup = BeautifulSoup(html, 'html.parser')
tbody = soup.find('tbody')
tr_list = tbody.find_all('tr')
for td in tr_list:
td_list = td.find_all('td')
loc = td_list[0].text # 지역
name = td_list[1].text # 이름
addr = td_list[3].string # 주소
tel = td_list[5].string # 전화번호
results.append([loc, name, addr, tel])
#print(loc, name, addr, tel)
else:
print(response.status_code)
pdResult=pd.DataFrame(results, columns=['지역','매장명','주소','전화번호'])
pdResult.to_csv('hollys_stores.csv', encoding='cp949')
print(pdResult)동적 웹사이트 크롤링(coffeebean)
selenium을 이용하겠음.
1. pip install selenium

pip install selenium==3.141.0selenium은 3, 4버전이 있는데
일반적으로 많이 쓰이는 3.141.0 버전을 사용하겠음.
select는 결과값이 하나이든 두개이든 리스트로 반환함.
select는 경로를 지정할 수 있음('div > tbody ...')
- chromedriver 다운로드
https://chromedriver.chromium.org/downloads
현재 실행중인 프로젝트 폴더에 chromedriver을 옮겨논다.
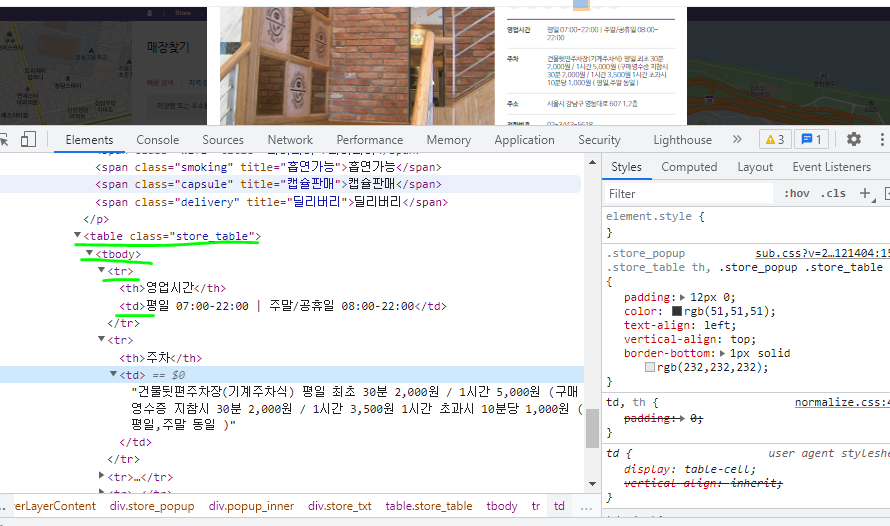
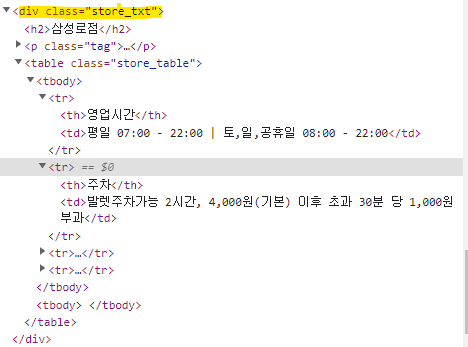
div.store_txt 안에 table 정보가 있고, table안에 td, tr 정보가 있음.

모든 건 zero 부터, 차근차근 헛둘헛둘