Preview
참고: 할리스 홈페이지(https://www.hollys.co.kr/)
html: 화면을 구성하는 요소를 명시한 문서
scrapy: 파이썬 프레임워크
- 과제면제권 사용할 때 과제게시판에 면제권 pdf 올리기
할리스 매장 검색
https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=1&sido=&gugun=&store=
https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=2&sido=&gugun=&store=
https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=3&sido=&gugun=&store=
https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=54&sido=&gugun=&store=매장 검색 url 패턴화
웹 페이지에 html 정보는 정적임.
정적인 파일이 있고 그 파일을 던져주기 때문에(정보를 보내주기 때문에), 인터랙티브 웹 페이지 (동적-자바스크립트)와 반대임.
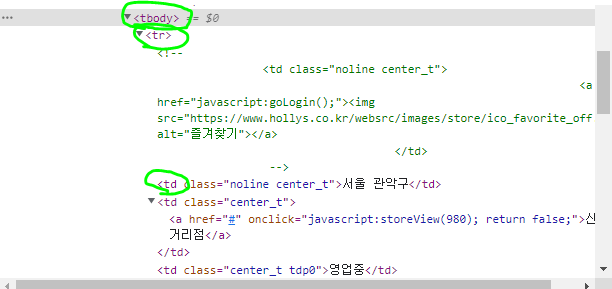
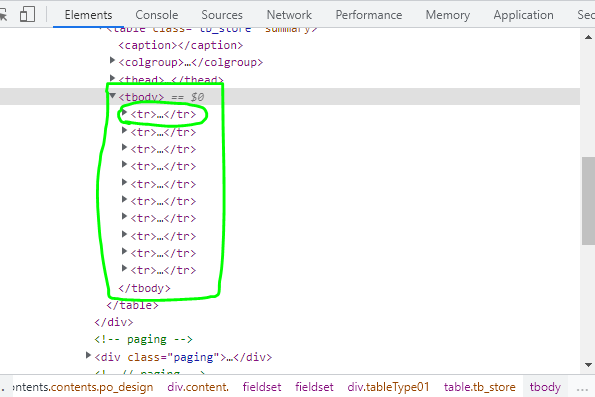
위 html의 경우 tbody> tr > td의 구조이기 때문에, 크롤링 할때 tbody> tr > td 순으로 정보를 가져오면 됨!
VScode => 가상환경 불러오려면 터미널 환경 세팅이 필수라
=> 파이참으로 실습 진행.
Ch6_1_hollysCrawler.py파일
result을 받아온 후 그 데이터를 바탕으로 DataFrame, csv 파일을 만드는 걸 알 수 있음.
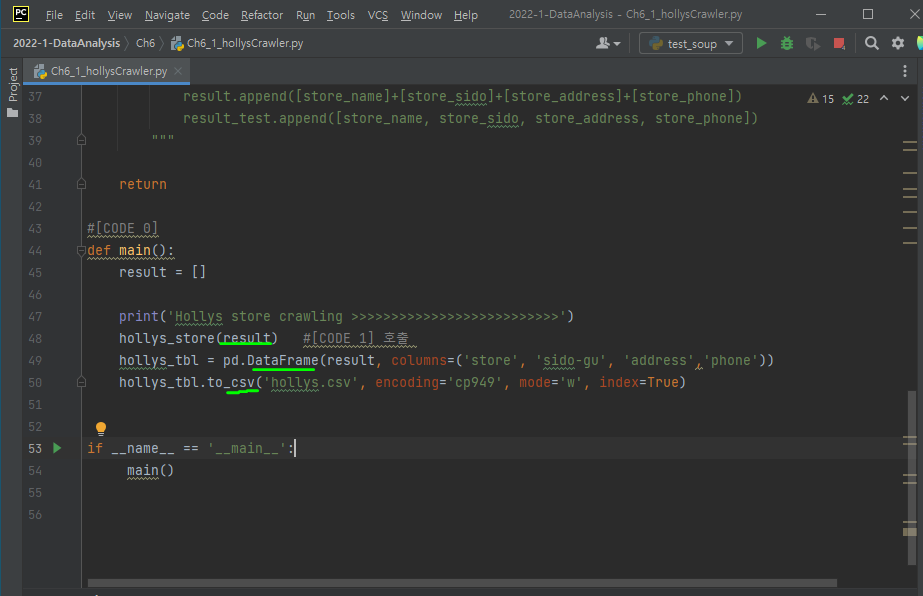
개발자도구에서 html 요소 파악
if(response.status_code == 200):
html = response.content
soupHollys = BeautifulSoup(html, 'html.parser')
tag_tbody = soupHollys.find('tbody')
for store in tag_tbody.find_all('tr'):
store_td = store.find_all('td')
store_name = store_td[1].string
store_sido = store_td[0].string
store_address = store_td[3].string
store_phone = store_td[5].string
result.append([store_name] + [store_sido] + [store_address] + [store_phone])
result_test.append([store_name, store_sido, store_address, store_phone])tbody를 찾고 tbody 안에 10개의 tr 태그 순서대로 for문을 돈다.
tr태그 속 td태그를 읽어오기 위해 find_all로 td태그를 읽어온다.
td태그의 첫번째 인자는 지역, 두번째 인자는 매장명, 세번째 인자는 영업중(이번 코드의 크롤링 정보에 해당x), 네번째 인자는 주소, 다섯번째 인자는 매장서비스(이번 코드의 크롤링 정보에 해당x), 여섯번째 인자는 전화번호이다.
이를 find_all로 td태그를 읽어온 정보가 리스트이므로 각각의 요소를 리스트의 인덱스으로 처리한다.
#[CODE 0]
def main():
result = []
print('Hollys store crawling >>>>>>>>>>>>>>>>>>>>>>>>>>')
hollys_store(result) #[CODE 1] 호출
hollys_tbl = pd.DataFrame(result, columns=('store', 'sido-gu', 'address','phone'))
hollys_tbl.to_csv('hollys.csv', encoding='cp949', mode='w', index=True)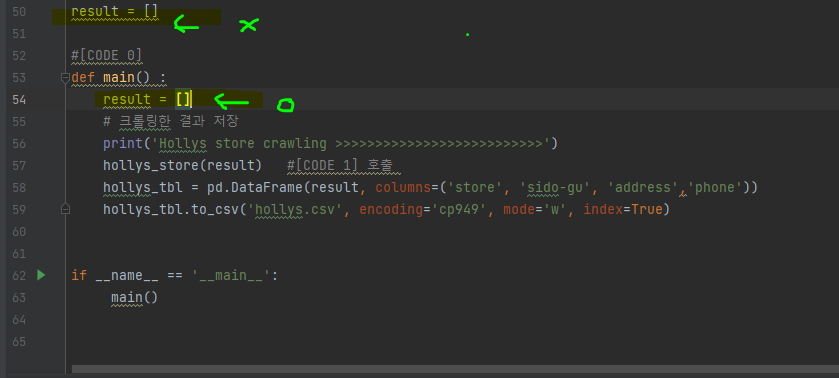
이때, 결과를 담는 변수인 result를 전역변수로 선언할 수 있는데, 파이썬에서 최대한 전역변수를 쓰지 않도록한다.
main() 함수 안에 지역변수로 넣자
크롤링한 정보인 result를 호출한후 DataFrame, csv파일로 만든다. 이때 csv으로 변환할 때 인코딩을 cp949로 하는데, 이는 csv파일을 열때 사용하는 마이크로소프트 엑셀 프로그램의 한글 인코딩 방식 cp949이기 때문이다.
