데이터분석프로그래밍
1.데이터 분석 프로그래밍

0308 12:00~1:15<영상자료>데이터를 저장하는 하드디스크의 비용 감소로 빅데이터의 역사가 시작됨.데이터는 정형화 되었어야 하는데, 비용 감소에 따라 다양한 정보가 저장 가능해짐.따라서 보다 많은 데이터를 쉽게 저렴하게 저장 가능이미지, 동영상 같은 비정형
2.데이터분석프로그래밍_0310_Fri

임상도(나무 지도), 산업 기상정보, 기상청의 기온, 강수량, 습도현재의 산불위험 지역을 알려주는 "국가 산불위험 예보" 서비스 개선범죄 데이터를 연계한 빅데이터 분석을 통해 수원시 cctv 사각 지대와 우선 설치 지역 선정(2014년)송도해수욕장에 대한 뉴스와 관광객
3.데이터분석프로그래밍_0315_Tue
개발환경파이썬 버전, 라이브러리 버전(Numpy 버전 등)이 중요함.함께 맞춰놓으면 디버깅 등 고생을 덜 할 수 있음.아나콘다쓰는 이유: 개인 pc, 실험실, 딥러닝, 파이썬 등개별적인 프로젝트를 진행하는데 개발환경이 다 다름!다양한 개발환경을 지원하기 때문에!과제 제
4.데이터분석프로그래밍_0317_Thu
아나콘다 실행 jupyter 실행 자기이름 폴더가 default 폴더임 파생변수까지 진도 나감. 1) 데이터 개수 확인2) 기타 보기3) 정렬과제공공데이터 포털 => 임의로 데이터 선택 => row 데이터가 어느정도 있는 것=> 1000개 정도 가지고 => p
5.데이터 분석 프로그래밍 0322 Tue
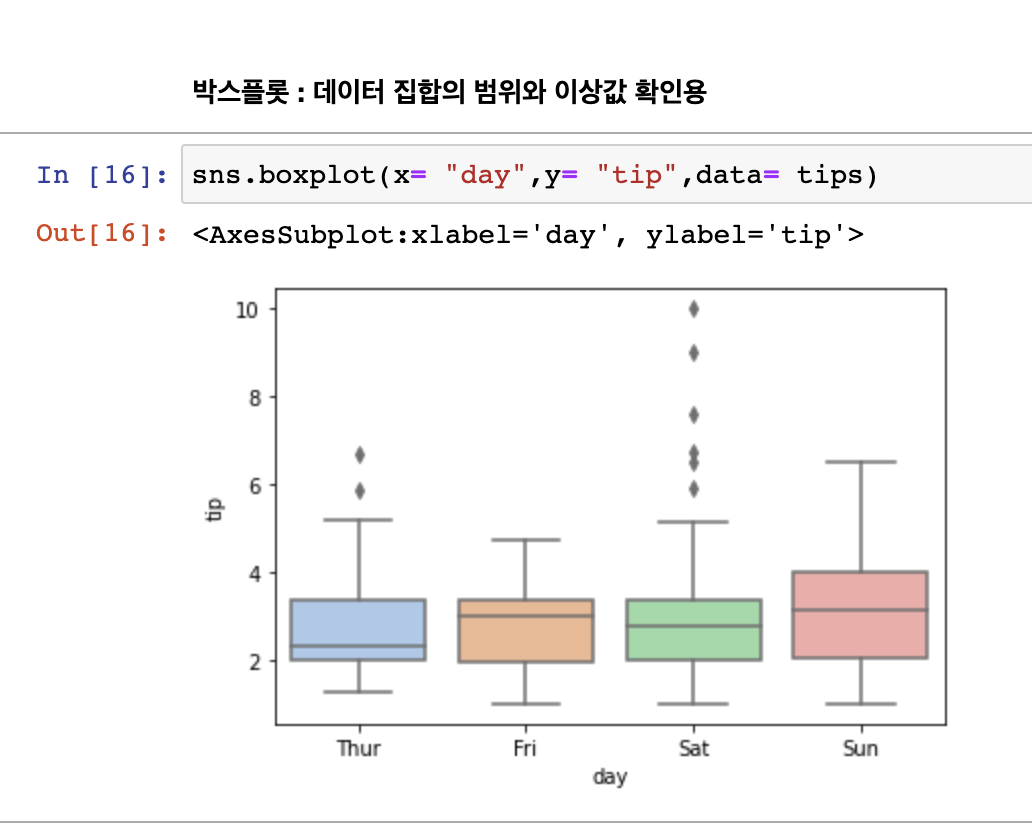
Data Visualization Basic(samples) 다운 받기 Preview pandasdatacleaning 파일 저번 시간 공백, 결측치 데이터를 없앨 때 대여소 번호, 대여 시간이 삭제안되는 이슈 연속적 수치라고 하면 평균값으로 대치할 때 오류 ->
6.데분프_0324_Thu_크롤링시작
join으로 사용가능.서브쿼리와 차이? (말씀하신 거 못 들었다)가장 비싼 도서의 이름부속 질의 => 조인하는거 연습하기집계연산=> 통계적인 이야기집합연산=> 두개를 합치는 것과제는 3장이 끝나고 다음시간에 같이 낼 예정.
7.데분프_0329_naverNews crawling
네이버 오픈 api를 활용한 크롤링주피터 노트북이 아닌 파이참을 쓰는 이유: 객체의 속성값, 하위 속성 ... => 계속 확인 가능단편적으로 한 줄 한 줄 씩 실행하려면 주피터 노트북이 적절하나, 디버깅을 하기위해 파이참을 사용.https://developer
8.데이터분석프로그래밍_0331
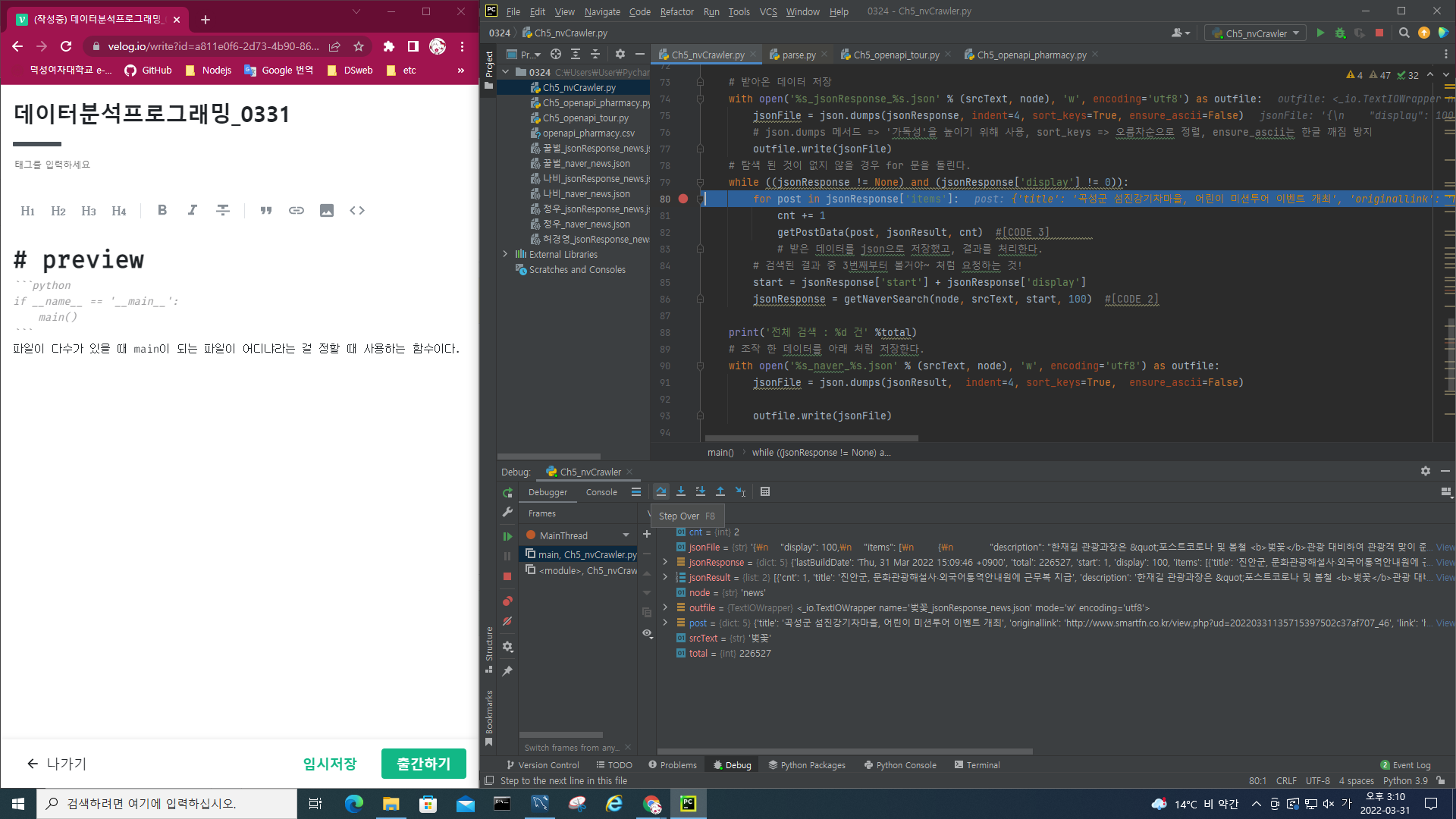
파일이 다수가 있을 때 main이 되는 파일이 어디냐라는 걸 정할 때 사용하는 함수이다.breaking pointF8> 실행결과를 return 받아 그 다음으로 넘어간다.F7> 함수 안에 들어간 실행결과를 보고싶으면 f7를 누르면 된다.네이버에서 제공하는 api말고 일
9.데분프_0405
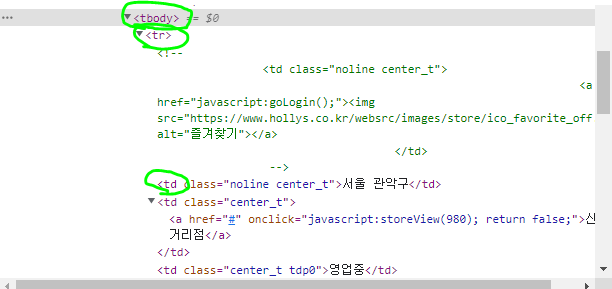
참고: 할리스 홈페이지(https://www.hollys.co.kr/)html 화면을 구성하는 요소를 명시한 문서scrapy: 파이썬 프레임워크과제면제권 사용할 때 과제게시판에 면제권 pdf 올리기할리스 매장 검색매장 검색 url 패턴화웹 페이지에 html 정
10.데분프_0407
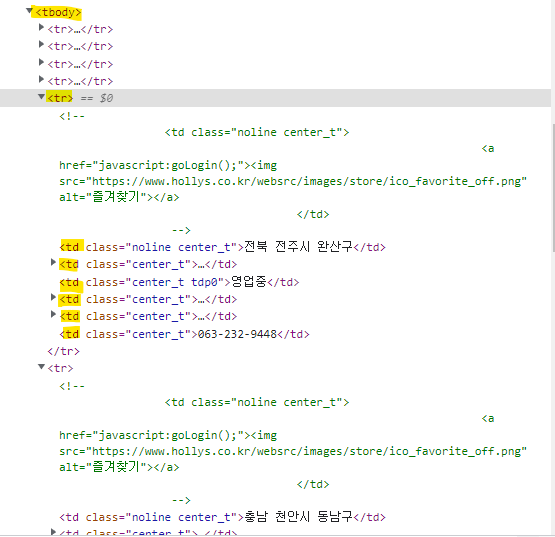
중간고사크롤링 > pandas > 데이터 정보를 이용(minmax, 특정 속성에 대해 count 등)결과는 1이다.따라서 find_all을 하기보다는(1개 요소이기에, 리스트로 출력하는것이 불편) find을 이용하자.https://wikidocs.net/857
11.데분프_0412
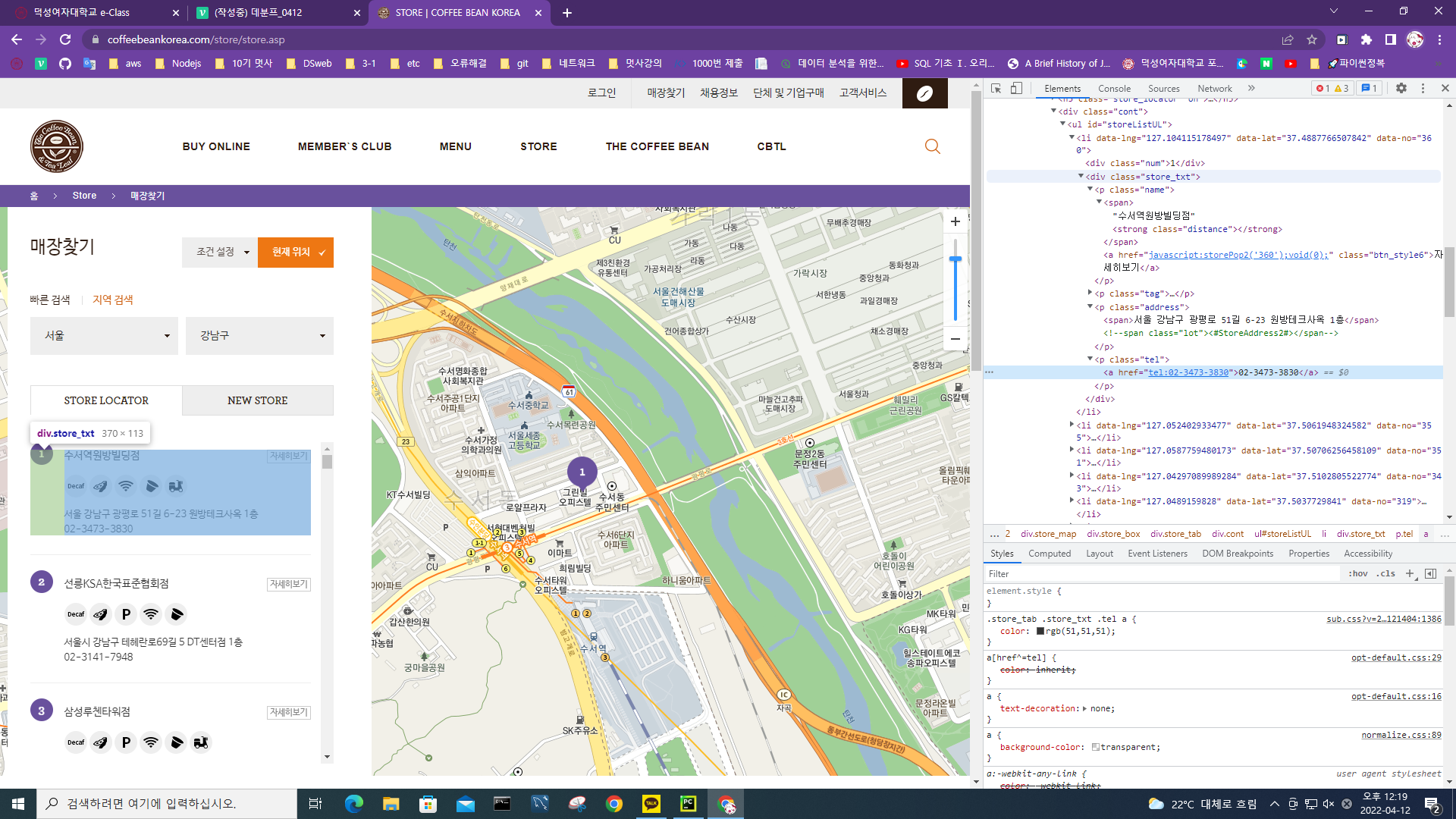
따로 공지 전까지는 비대면으로 수업 진행아마 시험(04/26)때는 대면으로 진행할 수 있을 듯호출된 자바스크립트 => bs로 파싱해 이용함storeListUL에 리스트 형식으로 매장이 나열되어 있는 듯 싶음.셀레니움 => 크롬드라이버로 페이지 띄우기bs => html만
12.데분프_0419

4월 19일에 앉은 자리에서 4월 26일 중간고사 진행할 예정파이썬 환경설정 세팅 미리 확인할 것.bs, selenium 사용할 수 있는지 확인selenium은 version 3점대 사용크롤링 한 후 dataframe으로 제작하기head, tail, 몇번째 항목 가져오
13.데분프_0421
시험 보기 전 커피빈 웹 페이지를 30명이 다 함께 크롤링해보니, 네트워크 오류 등으로 오류 발생 => 동적 웹페이지 크롤링은 안하고, 정적 웹 페이지 크롤링할 예정!
14.데분프_0428
커피빈 크롤링 오류href=클릭할 수 없는 객체로 오류 발생.강남구 선택 => li 정보가 있는 상태임.명시적인 ~ : 관심이 있는 태그가 있을 때까지 기다리겠다갱신이되지않았음에도 미리 읽어서 정보를 가져오기에, 갱신될 정보가 아니라서 오류 발생.=> 셀레니움을 사용하
15.데분프_0503
어떤 직군?제조사IT기업CJ, LG 화학등삼성 SDS(SI등)관심이 가는 직군?회사가 하는 일? => 채용공고로 확인(Job description)가장 기본적인 데이터 통계 기법 => 머신러닝까지통계분석 : 수치기반으로 분석하겠음이 데이터의 통계적인 경향성 => 임의
16.데분프_0510
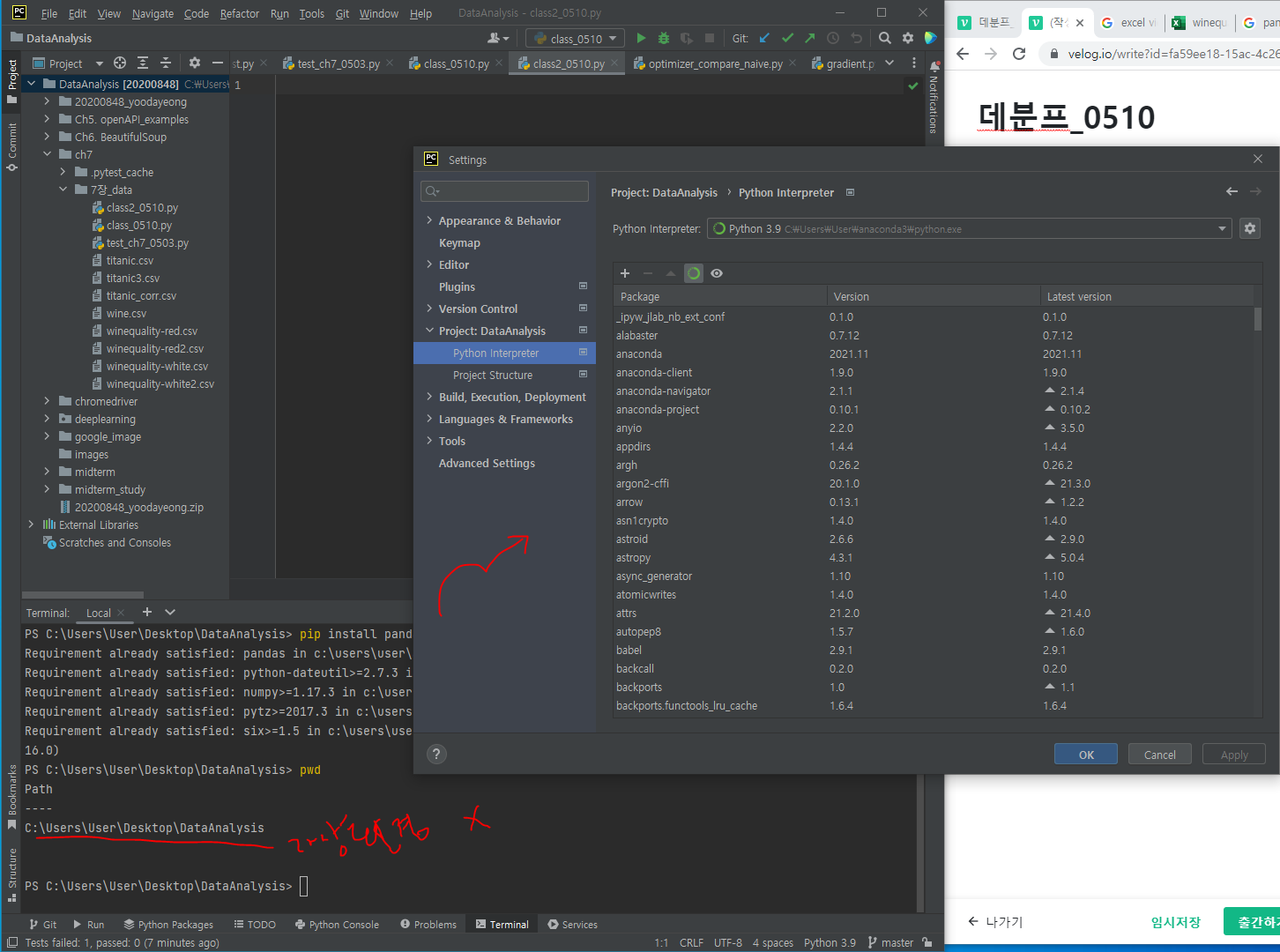
주식 종목의 우상향 그래프=> 그래서 다음날에는 어떤 결과? => 회귀분석을 통해 알 수 있음(이때 경향성-선형일 경우 선형 회귀분석, 독립변수가 여러개일 경우 다중선형회귀분석)0과 1로 구분(데이터가 2개의 범주 중 하나에 속하도록 결정하는)하는 경우 로지스틱 회귀를
17.데분프_0512

독립변수에 대한 회귀 변수warnings의 원인?x축, y축의 범위가 안맞기때문에!만약 (0,1000)(1,2000)(2,3000)이라면 범위를 맞춰준다.다중공정성혈중알코올농도-시험성적 상관관계 == 술 섭취량-시험성적 상관관계불필요한 모델로 성능이 나빠짐.PCA를 가
18.데분프_0517
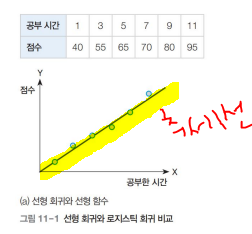
회귀분석: 데이터의 추세선으로 데이터를 예측, 추정하기 위함 상관분석: 변수들간에 어떤 상관관계가 있는지 확인 0~1까지, 절댓값 1에 가까울수록 상관성이 높음. 0에 가까울수록 상관성(correlation)이 없음 상관 계수 구하기 히트맵이 어떻게 나오는지를 보
19.데분프_0519
사이킷런을 설치하자사이킷런에서 제공하는 데이터셋sklearn.datasets 중에서 보스톤 주택 가격 데이터셋을 사용하기 위해 load_boston을임포트하고, 데이터셋을 로드하여load_boston( ) 객체boston를 생성line 6: 데이터셋에 대한 설명bost
20.데분프_0524
12주차 마지막 날3주만 더 있으면 방학이고, 방학이 끝나면 3학년 2학기이고 연말이라 시간이 빠르게 갈 것대학교때 배워야 하는 건 케어에서 벗어나 스스로 찾아가고 책임을 지고 하는 것 아닐까24시간 중에서 일을 몇시간 하는지주어진 시간 내 반 정도는 일하면서 보냄반
21.데분프_0526
내 PC > 우클릭 > 속성 > 64비트인지 아닌지 확인 환경변수 설정
22.데분프_0531
Kernel > RunAll 하면 모두 실행됨훈련 데이터셋에서만 최적화된 모델이 되버림 => 오버피팅(과적합)따라서 모든 훈련 데이터셋에서 몇 퍼센트를 떼어놓고 이용한다.결정트리 매개변수 매개변수로을 주면 정확도가 올라가는 방향search space 내에서 max de
23.데분프_0602
k개의 군집으로 분석할지 나누는 기법데이터 분포가 있을 때(어떤 데이터인지 모름), 데이터를 분류하기 위해 몇개의 군집(cluster)으로 나눌지?군집의 중심을 잡음각 데이터들을 가장 가까운 중심점으로 할당군집 내 데이터들을 기반으로 중심점 이동중심점의 이동이 없을 때
24.데분프_0607

코딩x 개념적인 부분을 기술하는 형태로 진행 크롤링 이후에 통계 분석, 상관 분석, 회귀 분석, 군집 분석, 텍스트 빈도 분석(시험 범위 포함x)까지 각 챕터당 코드 전 이론적인 배경 설명있음 => 참고할 것 예를 들어 지도, 비지도 학습 차이? 군집분석? 성능은 어
25.데분프_0609
주소데이터(커피빈 csv) => 지도에 주소 뿌리기지도 데이터 => gps 좌표 => 지도에 뿌리기gps 변환 방법 2가지프로그램(별도)네이버 맵 api(좌표 기반으로 지도 뿌려줌)다음 시간은(화) 질문을 토대로 q/a 할 예정