어떤 직군?
- 제조사
- IT기업
- CJ, LG 화학등
- 삼성 SDS(SI등)
관심이 가는 직군?
회사가 하는 일? => 채용공고로 확인(Job description)
가장 기본적인 데이터 통계 기법 => 머신러닝까지
통계분석 : 수치기반으로 분석하겠음
이 데이터의 통계적인 경향성 => 임의 값 대입했을 때 결과값을 도출함.
와인데이터를 가지고 실습할 예정
교재 학습보조자료 다운로드받으면 자료 다 있음.
와인의 화학적 요소, 성분을 기반으로 등급을 매김.
11가지 요소를 합쳐서 등급이 결정됨.
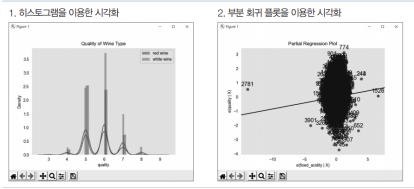
시본, 맷플롭으로 다룬 그래프=> 직관적인 확인을 위함.
[기술 통계 분석 + 그래프] 와인 품질 예측하기
기술 통계
데이터의 특성을 나타내는 수치를 이용해 분석하는 기본적인 통계 방법
예시로 평균, 중앙값, 최빈값들이 있음
토익 응시자를 %로 표현, 어떤 백화점의 매출이 지속적으로 증가, 연간 몇 %씩, 몇년도에 최대이익율 달성 등..
회귀 분석
독립 변수 x와 종속 변수 y 간의 상호 연관성(경향성) 정도를 파악하기 위한 분석 기법
'회귀'
돌아올 회 => 무엇으로 돌아오나?
평균으로 돌아옴! (평균을 향한 회귀 즉, (평균) 회귀)
ex. 학교 입장 학생 수 측정
1,2,3,4일차를 기준으로 5일차 입장 학생 수가 예측이 됨 => 평균의 추정선 으로 돌아온다.
<인과관계>
- 독립변수(x): 원인
- 종속변수(y): 결과
ex. 나이가 들 때 기초대사량 감소
나이: 독립변수
기초대사량: 종속변수
독립 변수가 하나 이면 단순 회귀 분석, 두 개 이상이면 다중 회귀 분석
이때, 독립 변수와 종속 변수의 관계에 따라
경향성이 선형일 경우 : linear-regression
비선형일 경우: non-linear-regression
T-검정
데이터에서 찾은 평균으로 두 그룹의 차이가 통계적으로 어떤 의미를 갖는지 수치화 하는 것
t 검정 맥락 짚기
쉬운 이해를 위해 예시를 하나 들어보자.
A 아이스크림의 표기 무게가 500g 인데 아무리봐도 500g 보다는 적은 것 같은 느낌이 드는 상황을 가정해보자.
이 상황을 정리해서 표현하면 다음과 같다.
아이스크림 회사는 A 아이스크림 무게가 500g 이라고 주장하고 있다. 즉, A 아이스크림 무게의 모평균이 500g 이라고 주장하고 있다.
나는 A 아이스크림의 무게가 500g 보다 가볍다고 생각한다. 즉, A 아이스크림 무게의 모평균이 500g 이라는 주장이 잘못되었음을 보이고 싶다.
아이스크림 회사의 주장이 거짓임을 밝히려면 어떻게 해야 할까?
단순하게 생각해보면 A 아이스크림을 10개정도 사서 무게의 평균을 내보면 된다.
만약 A 아이스크림 10개 무게의 평균이 300g 이라면 아이스크림 회사에 강하게 클레임을 걸 수 있을 것이다.
그런데 만약 A 아이스크림 10개 무게의 평균이 499g 이라면 어떻게 해야 할까?
500g 보다는 적으니 뭔가 기분은 나쁘지만 1g 정도의 차이는 봐줄 수 있을 것도 같다.
이런 상황에서
1g 의 차이가 통계적으로 어떤 의미를 갖는지 수치화 하는 것이 t 검정
정확히 말하면 1표본 t 검정(1 sample t test)이다. 하나의 표본을 가지고 하는 t 검정이라는 의미이다.
그러면 2표본 t 검정(2 sample t test)도 있을까?
물론 있다. 이것도 예시를 통해 감을 잡아보자.
이번에는 B 아이스크림이 있는데, 이 아이스크림은 바닐라맛과 딸기맛 두 종류가 있다고 하자.
아이스크림 회사에서는 두 아이스크림의 무게를 둘 다 500g 으로 표기했으나 아무리봐도 바닐라맛이 딸기맛보다 더 많은 것 같은 느낌이 드는 상황이다.
이 상황을 정리해서 표현하면 다음과 같다.
아이스크림 회사는 바닐라 맛 아이스크림의 무게와 딸기 맛 아이스크림의 무게가 똑같다고 주장하고 있다. 즉, 바닐라 맛 아이스크림의 모평균과 딸기 맛 아이스크림의 모평균이 서로 같다고 주장하고 있다. (여기서는 500g 이라는 수치는 그리 중요하지 않다)
나는 바닐라 맛 아이스크림이 딸기 맛 아이스크림보다 더 많다고 생각한다. 즉, 바닐라 맛 아이스크림과 딸기 맛 아이스크림의 모평균이 서로 같다는 주장이 잘못되었음을 보이고 싶다.
이 상황에서도 똑같이 각 맛의 아이스크림을 10개씩 사서 무게의 평균을 내볼 수 있다.
만약 바닐라맛 아이스크림 무게 평균이 501g 이고, 딸기맛 아이스크림 무게 평균이 499g 이라면,
두 평균의 차이 인 2g 이 통계적으로 어떤 의미를 갖는지 수치화 하는 것이 2표본 t 검정
히스토그램
데이터 값의 범위를 몇 개 구간으로 나누고 각 구간에 해당하는 값의 숫자나 상대적 빈도 크기를 차트로 나타낸 것
데이터 준비
1/ 다운로드한 csv 파일 정리하기
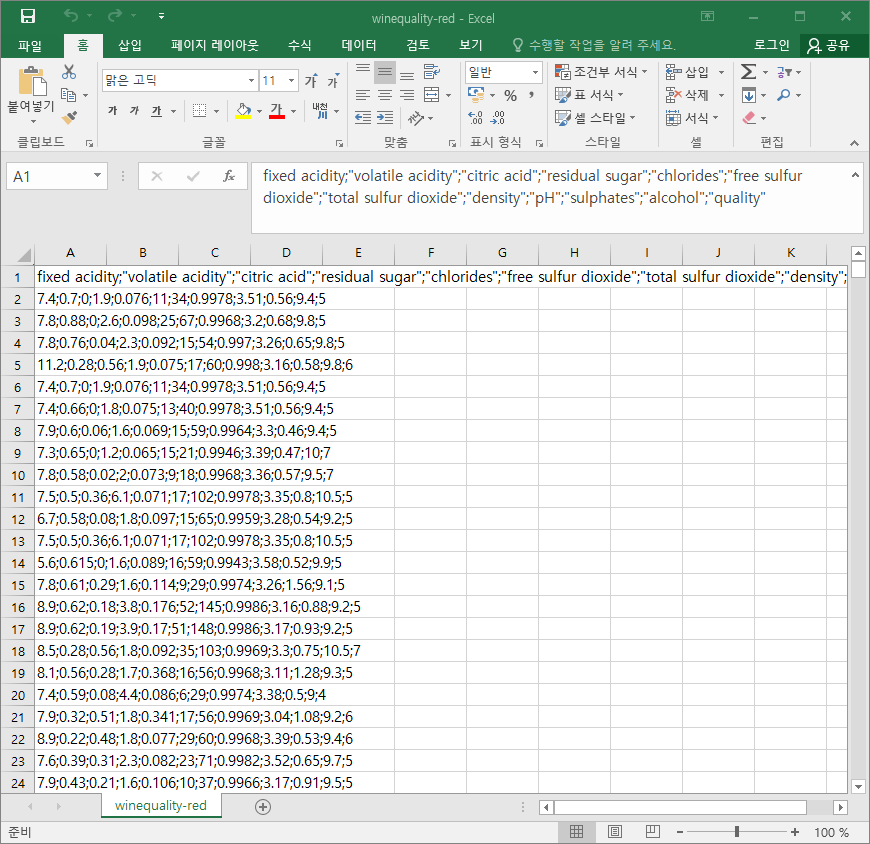
다운로드한 파일은 세미콜론을 열 구분자로 사용함.
그러나 엑셀은 csv 파일을 열 때 쉼표를 열 구분자로 사용하므로 열이 깨진 것 처럼 보임
따라서 데이터 셋의 구성을 파악하기 어려우니까 엑셀에서 세미콜론을 열 구분자로 인식하도록 파일을 다시 저장해야!
> red_df = pd.read_csv('C:/Users/kmj/My_Python/7장_data/winequality-red.csv', sep = ';', header = 0, engine = 'python')- sep = ';'
separate 옵션이 ';'임. - header = 0
0번째 row를 column 속성으로 잡음. - engine = 'python'
default 옵션이 c언어임.
파이참 단축어 alt+shift로 다중 열 드래그 가능
코드
import pandas as pd
red_df = pd.read_csv('./winequality-red.csv', sep =';', header = 0, engine ='python')
white_df = pd.read_csv('winequality-white.csv', sep =';', header = 0, engine='python')
red_df.columns.str.replace(' ','_')
print(red_df.head())
print(white_df.head())