주식 종목의 우상향 그래프
그래서 다음날에는 어떤 결과?
=> 회귀분석을 통해 알 수 있음(이때 경향성-선형일 경우 선형 회귀분석, 독립변수가 여러개일 경우 다중선형회귀분석)
0과 1로 구분(데이터가 2개의 범주 중 하나에 속하도록 결정하는)하는 경우 로지스틱 회귀를 사용한다.
ex. 수업의 pass/non pass 여부
절대경로의 시작은 c드라이브이다.
상대경로의 시작은 내가 사용중인 현재 working directory로부터 읽어오고자 하는 폴더까지의 경로이다.
데이터 준비
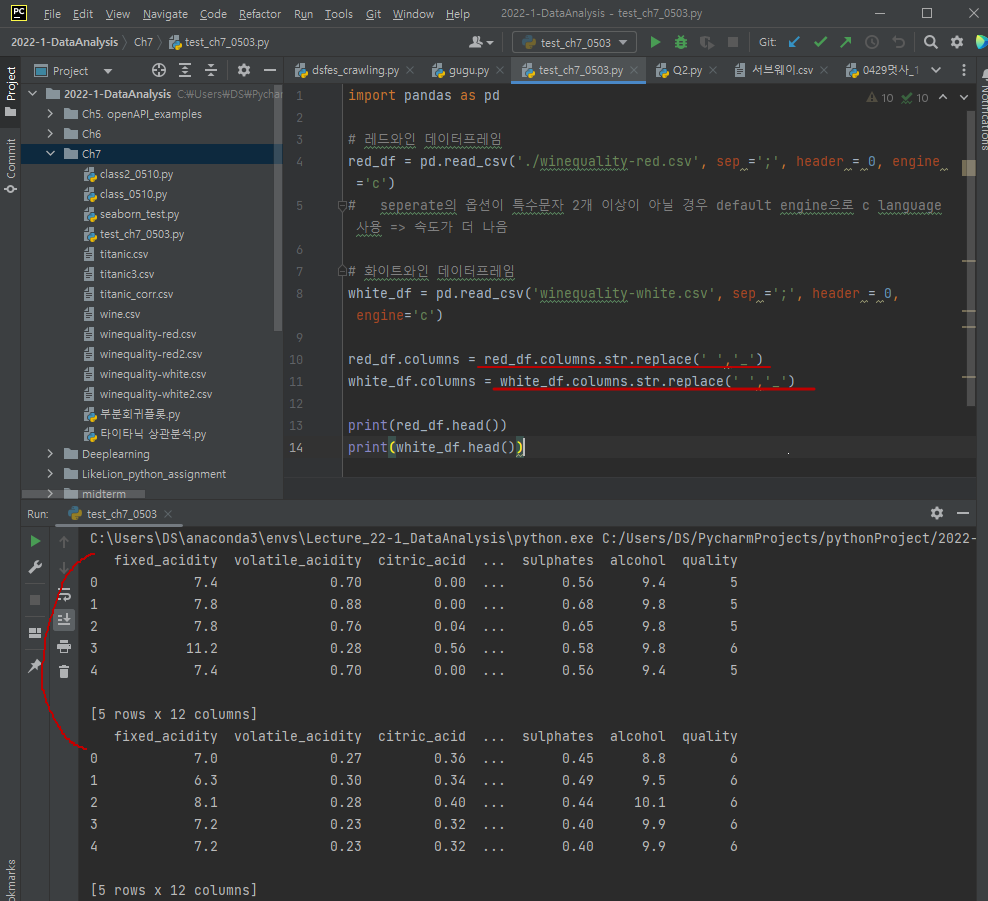
머신러닝 용 데이터 셋은 n개 속성 중 마지막이 출력 변수(y)이고 앞에서부터 n-1개의 속성은 입력 변수(x)로 구성
즉, (12-1)11개의 속성들이 입력변수이고 출력 변수는 와인의 품질 등급을 나타내는 quality이다.
데이터 병합
- 레드와인과 화이트와인 파일 합치기
레드 와인과 화이트 와인을 비교해 분석할 예정이므로 두 파일을 하나로 합쳐야!
이때 type 열을 하나 추가해 레드와인과 화이트 와인을 구분한다.
데이터 탐색
데이터를 병합한 후 기술 통계 방법으로 탐색해보자
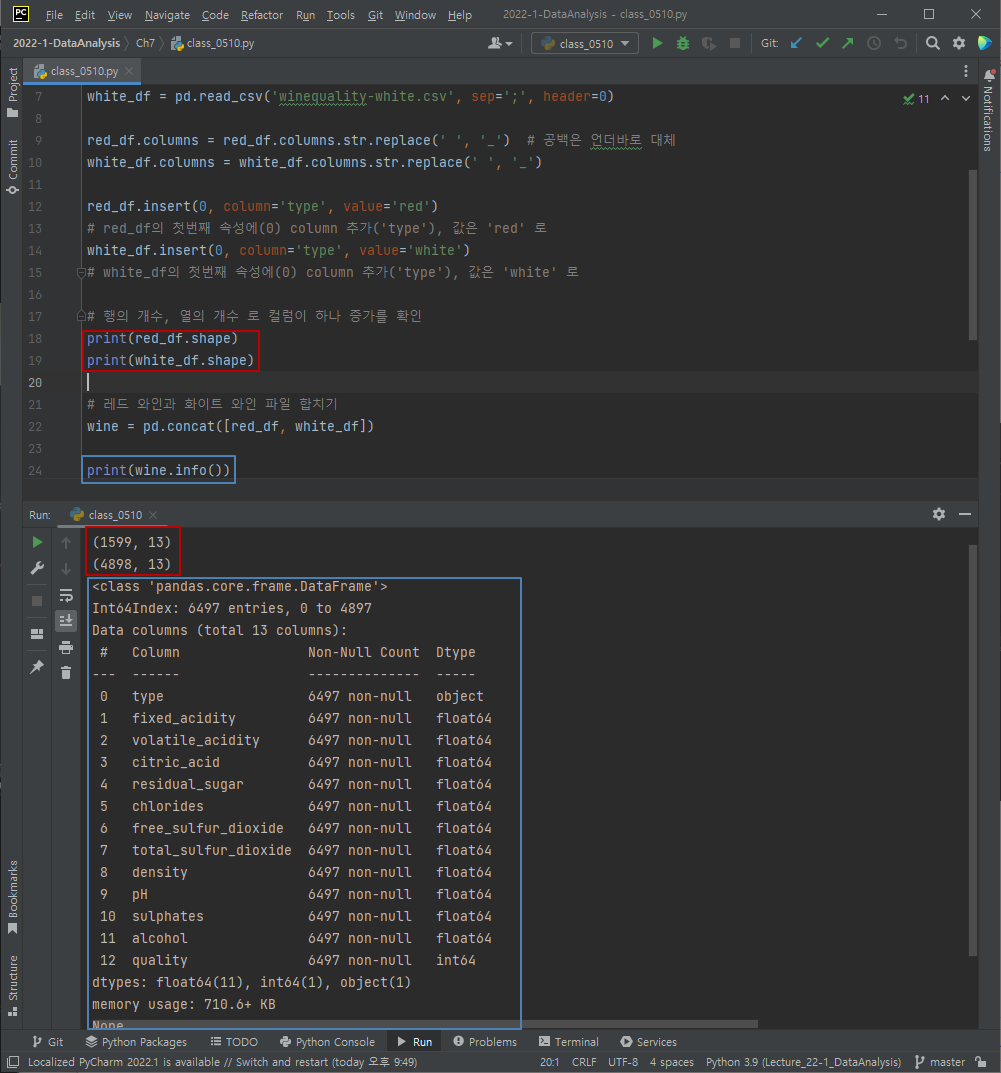
info() 함수를 사용해 기본 정보 확인
전체 샘플은 6,497개이고 속성을 나타내는 열은 13개이다.
각 속성의 이름은 type부터 quality까지, 속성 중 실수타입(float 64)은 11개, 정수타입(int 64)은 1개(quality), 독립변수(x)는 type부터 alcohol까지 12개이고 종속변수(y)는 1개(quality)이다.
함수를 이용해 기술 통계 구하기
-
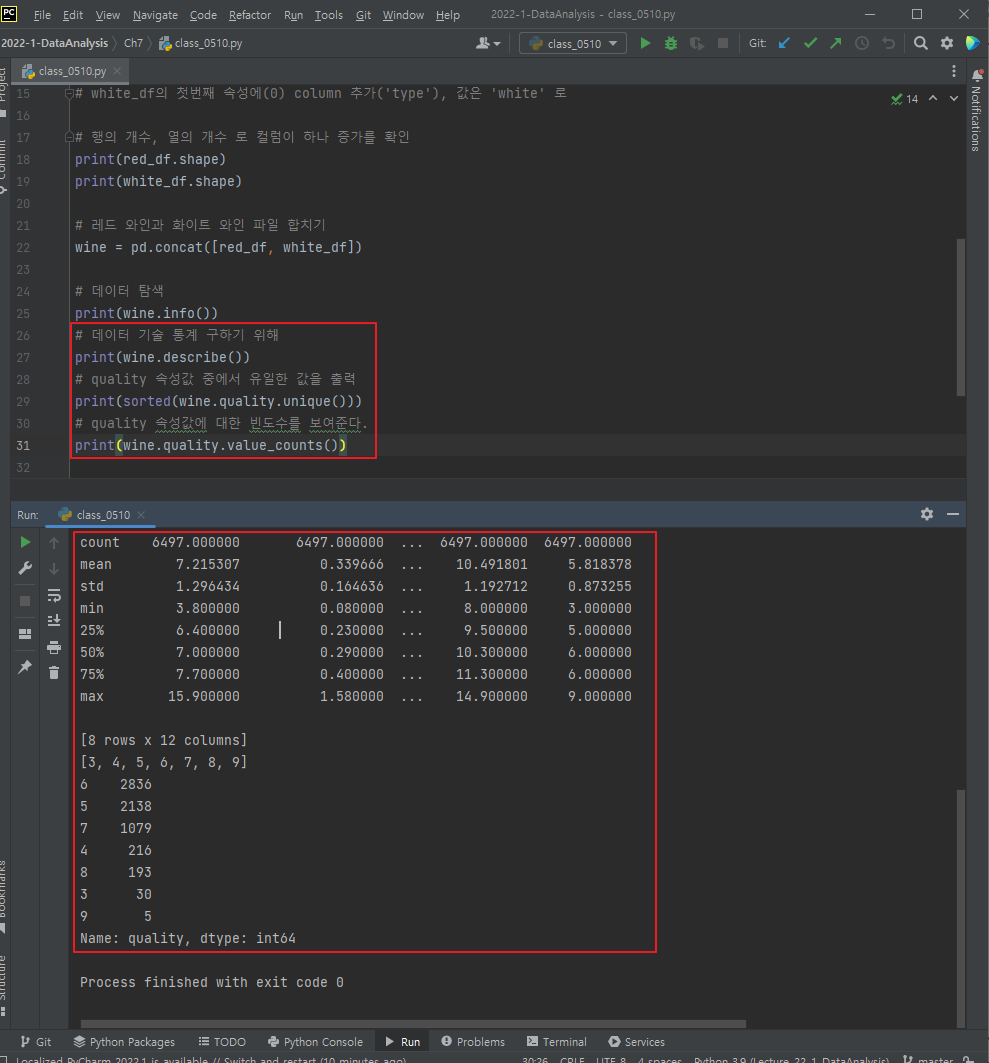
describe()함수로 속성별 개수(count), 평균(mean), 표준편차(std), 최소값(min), 전체 데이터 백분율에 대한 25번째 백분율 수(25%), 중앙값인 50번째 백분위수(50%), 75번째 백분위수(75%) 그리고 100번째 백분위수인 최대값(max)을 출력
-
unique 함수로 quality 속성값 중 유일한 값을 출력
이를 통해 와인 품질 등급인 quality은 3,4,5,6,7,8,9의 7개 등급이 있음을 알 수 있음 -
value_counts 함수로 quality 속성값에 대한 빈도수를 보여준다. 6등급인 샘플이 2836개로 가장 많고, 9등급인 샘플이 5개로 가장 적음 확인
데이터 모델링
기술 통계를 사용해 데이터에서 탐색한 내용을바탕으로 레드 와인 그룹과 화이트 와인 그룹을 비교한 후 품질 등급을 예측하기 위한 분석 모델을 만들어보자.
describe() 함수로 그룹 비교하기
그룹을 비교하는 첫 번째 방법은 type에 따라 그룹을 나누 후 종속 변수인 quality에 describe() 함수를 사용해 그룹 별로 count, mean, std...를 구해 비교하는 것
기술 통계 전부를 구할 때는 describe() 함수를 사용하지만 mean() 함수로 평균만 구해거나 std() 함수로 표준편차만 따로 구할 수 있음. 이때 mean()함수와 std() 함수를 묶어서 한번에 사용하려면 agg() 함수 이용
agg() 함수는 속도가 빠른 장점이 있음(속도 개선)
aggregate
: something formed by adding together several amounts or things
t-검정과 회귀 분석으로 그룹 비교하기
그룹을 비교하는 두 번째 방법은 t-검정을 사용해 그룹 간 차이를 확인하는 것.
세 번째 방법은 회귀 분석을 수행하는 것.
t-검정을 위해서는 scipy 라이브러리 패키지를 사용하고, 회귀 분석을 위해서는 statsmodels 라이브러리 패키지 사용
pycharm 터미널에 가상환경이 적용이 안되서, 직접 file의 setting에 들어가 라이브러리 패키지를 설지하자. 회귀 분석을 위해 statsmodels 라이브러리 패키지 사용.
파이썬 언어의 장점: return 값이 2개 이상이 가능하다.
def test():
return 3, 'A' # python의 장점: return 값이 2개 이상 가능
print(test())단순선형회귀 분석 진행
Rformula = 'quality ~ fixed_acidity + volatile_acidity + citric_acid + residual_sugar + chlorides + free_sulfur_dioxide + total_sulfur_dioxide + density + pH + sulphates + alcohol'
regression_result = ols(Rformula, data=wine).fit() # fit을 통해 알아내시오.(학습완료)
regression_result.summary()statsmodels 패키지에 있는 ols 함수를 사용하면 간편하게 단순선형회귀 분석을 진행할 수 있다.
먼저 (Mac의 경우) 터미널에서 pip3 install statsmodels를 사용하여 statsmodels패키지를 설치하고,
from statsmodels.formula.api import ols 를 실행함으로써 ols 함수를 불러온다.
그리고 ols 함수의 파라미터들을 아래와 같은 순서로 입력하여 코드를 완성시키면 된다.
ols('종속변수명 ~ 독립변수명', data=데이터프레임명).fit().summary()
여기서 따옴표를 찍을 때 종속변수명과 독립변수명을 한번에 묶어주는 것(~)을 주의한다.
그러면 아래와 같이 예쁘게 정리된 OLS Regression Results가 출력되는 것을 볼 수 있다.
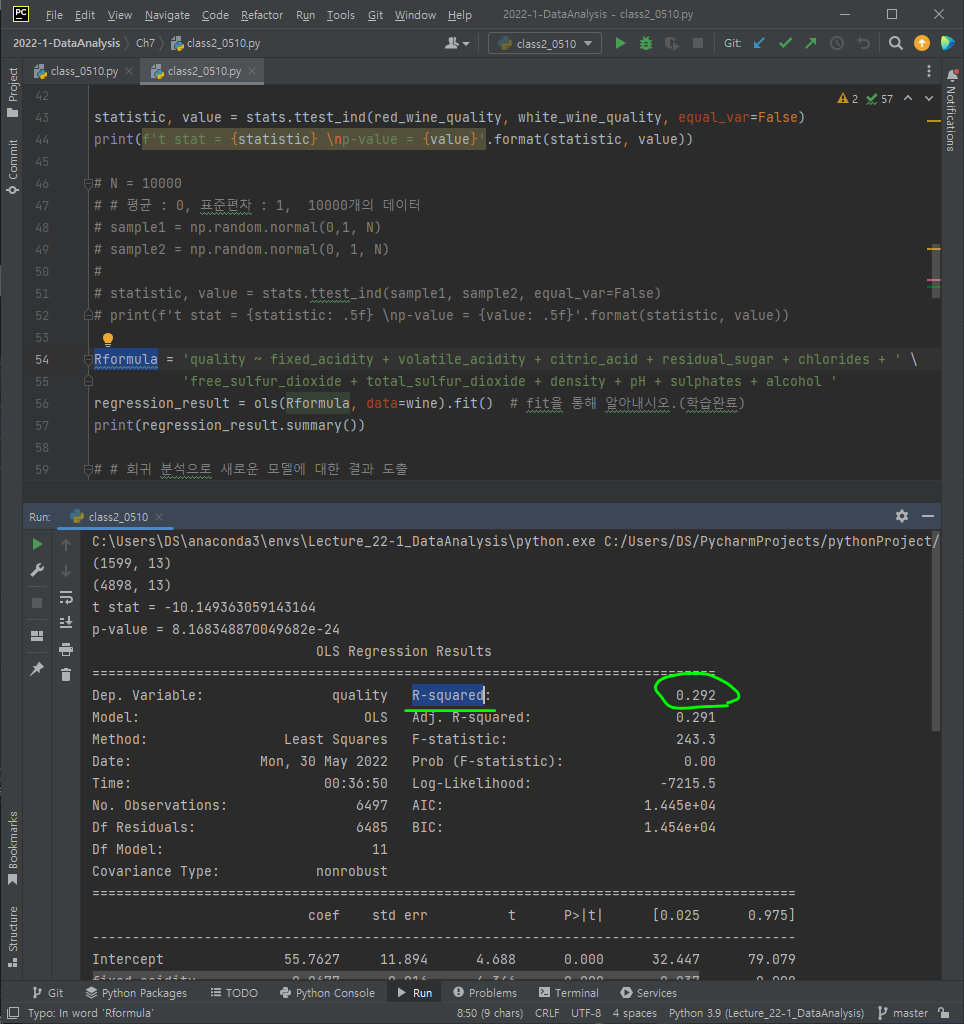
출력결과 중 R-squared 가 최소한 0.5정도는 되어야 하는데, 낮은 결과로 추세선이 잘 안 그려지는 걸 확인
종속변수: 와인의 성분(독립변수-성분들이 와인의 퀄리티에 어떻게 영향 미치는지!)
독립변수가 하나일때 추세선 구하는 방법은 y=ax+b임(선형)
독립변수가 두개일때 추세선을 구하는 방법은
y=ax+b+bx+cx...
이때의 intercept(절편)=> y절편임.
오늘 배운 건 가장 기본적인 회귀분석.
머신러닝 기법(사이킷런)이 들어간 회귀분석도 있음
다음에는 그래프 그리는법과 상관분석 배우겠음
