사이킷런을 설치하자
사이킷런에서 제공하는 데이터셋 sklearn.datasets 중에서 보스톤 주택 가격 데이터셋을 사용하기 위해 load_boston을
임포트하고, 데이터셋을 로드하여load_boston( ) 객체boston를 생성
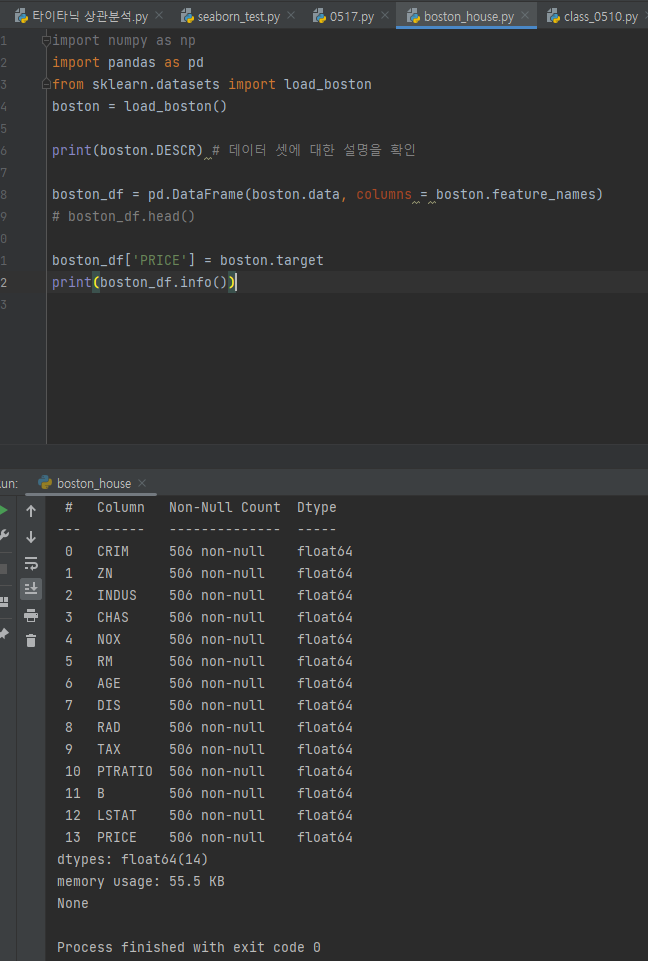
line 6: 데이터셋에 대한 설명boston.DESCR을 확인
line 8: 데이터셋 객체의 data 배열boston.data,즉 독립 변수 X가 되는 피처들을 DataFrame 자료형으로 변환하여 boston_df를 생성
line 12: boston_df의 데이터 전체를 확인 bostone_df.info( )
와인데이터셋 추세선 어떻게?
white, red와인 합쳐서 6000여개 있었음. 전체 데이터를 가지고 추세선을 구함
사용자가 입력한 데이터를 가지고 몇 등급인지 결과 추정함
학습이 잘 되었는지 안되었는지 확인하려면 훈련데이터와 시험 데이터로 알아보는 과정이 필요함.
503개 중 70%만 학습에 사용, 이 모델이 잘 학습이 되었는지 성능 평가.
(7:3 비율로 나뉨. 보통 70%는 훈련(train)/ 30%는 시험(test)!)
학습데이터로만 성능 평가했을 때 오버피팅이 일어나고 새로운 유형에 대해서는 성능이 매우 낮음.
히트맵 확인(상관분석)
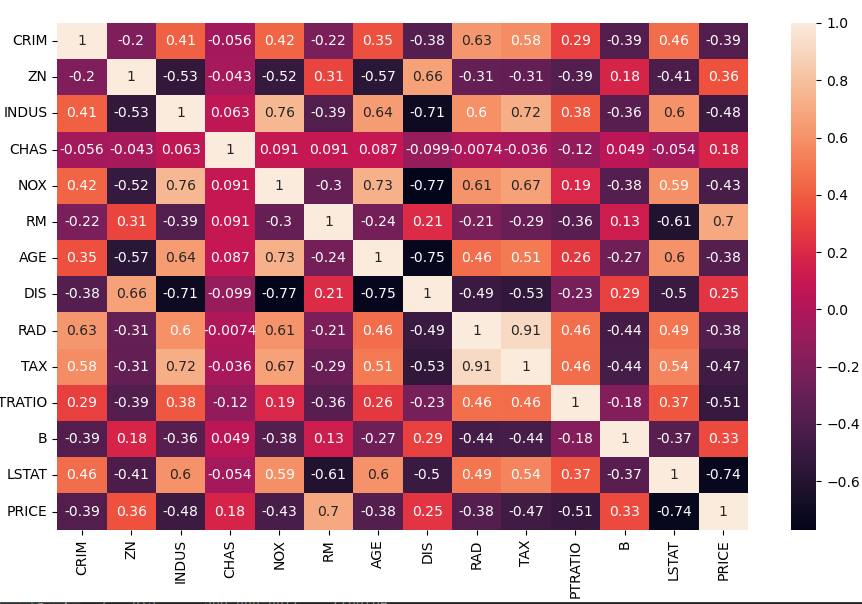
까만 부분이 상관성이 높음
수학공부하는데 누가 옆에 와서 영어를 블라블라 말하면 집중이 잘 안되듯이, 데이터 학습에서도 상관없는 데이터가 들어오면 학습이 잘 진행되지 않음
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.DESCR) # 데이터 셋에 대한 설명을 확인
boston_df = pd.DataFrame(boston.data, columns=boston.feature_names)
# boston_df.head()
boston_df['PRICE'] = boston.target
print(boston_df.info())
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# X, Y 분할하기
Y = boston_df['PRICE']
X = boston_df.drop(['PRICE'], axis=1, inplace=False)
# 훈련용 데이터와 평가용 데이터 분할하기
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=156) # random state는 숫자가 뭐든 상관 x
# random 함수는 컴퓨터가 시간을 가지고 랜덤값 도출함(이때, 디버깅을 위해 일정한 값인 seed로 값을 설정함)
# 선형 회귀 분석 : 모델 생성
lr = LinearRegression()
# 선형 회귀 분석 : 모델 훈련 => 추세선 구함
lr.fit(X_train, Y_train)
# 선형 회귀 분석 : 평가 데이터에 대한 예측 수행 -> 예측 결과 Y_predict 구하기 => 나온 추세선을 가지고 예측 결과 구하기!
Y_predict = lr.predict(X_test)
mse = mean_squared_error(Y_test, Y_predict) # (예측-정답)^2 : 평균제곱오차
rmse = np.sqrt(mse) # 루트(예측-정답)^2 : 제곱근 씌운다
print('MSE : {0:.3f}, RMSE : {1:.3f}'.format(mse, rmse)) # 17.297(price의 단위) 만큼 차이
print('R^2(Variance score) : {0:.3f}'.format(r2_score(Y_test, Y_predict)))
# 상관분석을 통해 각 변수들 사이 상관관계 분석
import seaborn as sns
import matplotlib.pyplot as plt
# corr = boston_df.corr()
# sns.heatmap(corr, annot=True)
# plt.show()
# pca를 이용한 성능 개선
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA # Principal component analysis
scaler = StandardScaler()
normalized_x = scaler.fit.transform(X)
# 데이터 분포 골고루
pca = PCA(n_componetns=6) # 주요한 성과 몇개로 축약해 보여줘!
pca_X = pca.fit.transform(normalized_x) # 나온 성과를 가지고 입력데이터를 쓰겠음
print('#' * 20)
# 훈련용 데이터와 평가용 데이터 분할하기
# 주요 성분 6개를 뽑은걸 가지고 학습 데이터로 쓰겟음
X_train, X_test, Y_train, Y_test = train_test_split(pca_X, Y, test_size=0.3, random_state=156)
# 선형 회귀 분석 : 모델 생성
lr = LinearRegression()
# 선형 회귀 분석 : 모델 훈련 => 추세선 구함
lr.fit(X_train, Y_train)
# 선형 회귀 분석 : 평가 데이터에 대한 예측 수행 -> 예측 결과 Y_predict 구하기 => 나온 추세선을 가지고 예측 결과 구하기!
Y_predict = lr.predict(X_test)
mse = mean_squared_error(Y_test, Y_predict) # (예측-정답)^2 : 평균제곱오차
rmse = np.sqrt(mse) # 루트(예측-정답)^2 : 제곱근 씌운다
print('MSE : {0:.3f}, RMSE : {1:.3f}'.format(mse, rmse)) # 17.297(price의 단위) 만큼 차이
print('R^2(Variance score) : {0:.3f}'.format(r2_score(Y_test, Y_predict)))회귀분석 이제 끝!
과제
수업시간에 보여준거 이용하기(standard 어쩌구)
pca를 선택한 기준: 상관분석을 통해 봐서 0.4이상의 상관계수가 있는걸 확인(corr을 통해 히트맵으로 뿌리고)했음(감 잡기)
line by line으로 주석달기
어떤 함수의 파라미터로 들어간 값 => 어떤 기능을 하는지 최대한 많이 설정
파라미터의 의미가 뭔지?
text size: 비율 결정하는거..
random_state: random하게 뽑을때 seed 결정하는거...
python 함수 파라미터 명 치면 많이 나온다.
주석의 성실성으로 평가하겠음
상세하게 주석을 달면, 다음에 활용할 때 기억이 빨리 날 수 있음
과제는 다음주 목요일까지!!
추가적으로 캘리포니아 하우스를 해보고 싶다하면.. 자동차 연비를 하던.. 지금있는 코드에서 데이터 셋 가져오는 것만 바꾸면 된다.(주석을 달것)
코드 전문
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.DESCR) # 데이터 셋에 대한 설명을 확인
boston_df = pd.DataFrame(boston.data, columns=boston.feature_names)
# boston_df.head()
boston_df['PRICE'] = boston.target
print(boston_df.info())
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# X, Y 분할하기
Y = boston_df['PRICE']
X = boston_df.drop(['PRICE'], axis=1, inplace=False)
# 훈련용 데이터와 평가용 데이터 분할하기
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=156) # random state는 숫자가 뭐든 상관 x
# random 함수는 컴퓨터가 시간을 가지고 랜덤값 도출함(이때, 디버깅을 위해 일정한 값인 seed로 값을 설정함)
# 선형 회귀 분석 : 모델 생성
lr = LinearRegression()
# 선형 회귀 분석 : 모델 훈련 => 추세선 구함
lr.fit(X_train, Y_train)
# 선형 회귀 분석 : 평가 데이터에 대한 예측 수행 -> 예측 결과 Y_predict 구하기 => 나온 추세선을 가지고 예측 결과 구하기!
Y_predict = lr.predict(X_test)
mse = mean_squared_error(Y_test, Y_predict) # (예측-정답)^2 : 평균제곱오차
rmse = np.sqrt(mse) # 루트(예측-정답)^2 : 제곱근 씌운다
print('MSE : {0:.3f}, RMSE : {1:.3f}'.format(mse, rmse)) # 17.297(price의 단위) 만큼 차이
print('R^2(Variance score) : {0:.3f}'.format(r2_score(Y_test, Y_predict)))
# 상관분석을 통해 각 변수들 사이 상관관계 분석
import seaborn as sns
import matplotlib.pyplot as plt
# corr = boston_df.corr()
# sns.heatmap(corr, annot=True)
# plt.show()
# pca를 이용한 성능 개선
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA # Principal component analysis
scaler = StandardScaler()
normalized_x = scaler.fit.transform(X)
# 데이터 분포 골고루
pca = PCA(n_componetns=6) # 주요한 성과 몇개로 축약해 보여줘!
pca_X = pca.fit.transform(normalized_x) # 나온 성과를 가지고 입력데이터를 쓰겠음
print('#' * 20)
# 훈련용 데이터와 평가용 데이터 분할하기
# 주요 성분 6개를 뽑은걸 가지고 학습 데이터로 쓰겟음
X_train, X_test, Y_train, Y_test = train_test_split(pca_X, Y, test_size=0.3, random_state=156)
# 선형 회귀 분석 : 모델 생성
lr = LinearRegression()
# 선형 회귀 분석 : 모델 훈련 => 추세선 구함
lr.fit(X_train, Y_train)
# 선형 회귀 분석 : 평가 데이터에 대한 예측 수행 -> 예측 결과 Y_predict 구하기 => 나온 추세선을 가지고 예측 결과 구하기!
Y_predict = lr.predict(X_test)
mse = mean_squared_error(Y_test, Y_predict) # (예측-정답)^2 : 평균제곱오차
rmse = np.sqrt(mse) # 루트(예측-정답)^2 : 제곱근 씌운다
print('MSE : {0:.3f}, RMSE : {1:.3f}'.format(mse, rmse)) # 17.297(price의 단위) 만큼 차이
print('R^2(Variance score) : {0:.3f}'.format(r2_score(Y_test, Y_predict)))
fig, axs = plt.subplots(figsize = (16, 16), ncols = 3, nrows = 5)
x_features = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B','LSTAT']
for i, feature in enumerate(x_features):
row = int(i/3)
col = i%3
sns.regplot(x = feature, y = 'PRICE', data = boston_df, ax = axs[row][col])