회귀분석: 데이터의 추세선으로 데이터를 예측, 추정하기 위함
상관분석: 변수들간에 어떤 상관관계가 있는지 확인
0~1까지, 절댓값 1에 가까울수록 상관성이 높음.
0에 가까울수록 상관성(correlation)이 없음
상관 계수 구하기
히트맵이 어떻게 나오는지를 보고 상관계수를 구할 수 있음
titanic_corr = titanic.corr(method='pearson')
titanic_corr연속형변수에 대해서만 상관계수 구할 수 있음(불린값x)
=> 어떤 변수와 양의 상관성, 음의 상관성이 있느냐?
상관성이 떨어져보이는 걸 삭제하느냐 마느냐 결정시 사용
산점도를 뿌려 데이터 분포 확인
히트맵으로 데이터 분포 확인
titanic = titanic.drop(['alone','adult_male'], axis=1, inplace=False)
def category_age(x):
'''
나이: 1,2,3,.., 9는 0
11,12,13..., 19는 1
21,22,...,29는 2
101,102,...,109는 100
'''
return int(x//10) # 파이썬에서 몫 구하는 법: //
titanic['age2']=titanic['age'].apply(lambda x:int(x//10)) # 몇줄 안되는 코드이기에, lambda로 함수 작성 가능
print(titanic['age2'],titanic['age'])
# apply: 가로축 연산, 세로축 연산
# map은 series의 경우 apply와 같은 연산임. 단, map의 경우 함수 또는 딕셔너리가 들어갈 수 있다!10장에 회귀분석이 나오기 때문에 학습의 연속성을 위해 10장부터 나갈 예정임
용어: 독립변수, 종속변수 => 머신러닝에서는 feature로 사용
통계적인 이야기에서는 독립변수(꼬리, 다리수, 얼룩무늬, 날개 등을)라고 하고, 사자/호랑이/독수리/뱀은 종속변수라 하고 이는 머신러닝에서는 label이다.
기계가 학습을 잘 하도록 해야!
결정을 내리는데 방해가 되는 데이터는 지워줘야!(잘생김?)
feature를 잘 정해야!
feature조차도 기계가 뽑아줄 수 있음
CNN: feature를 알아서 뽑아주는 머신러닝기법
사이킷런으로 사용해볼 예정임.
와인 회귀분석의 경우, 정답과 예측값이 존재함
정답 데이터로 학습 시킨 후 나온 추세선에 예측값을 대입해봄
평균적인 차이(예측값과 정답값 사이)
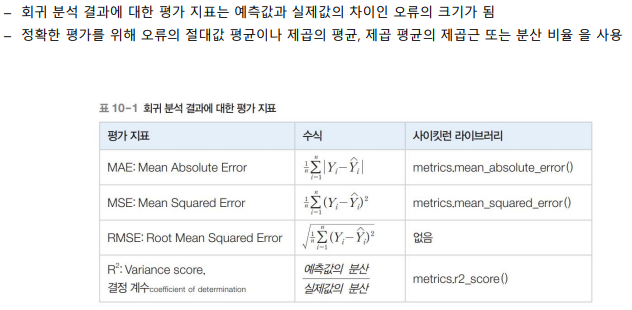
MSE, RMSE 많이 사용(평균 제곱 오차와 제곱근 평균 제곱 오차)

모든 건 zero 부터, 차근차근 헛둘헛둘