Graphviz
설치
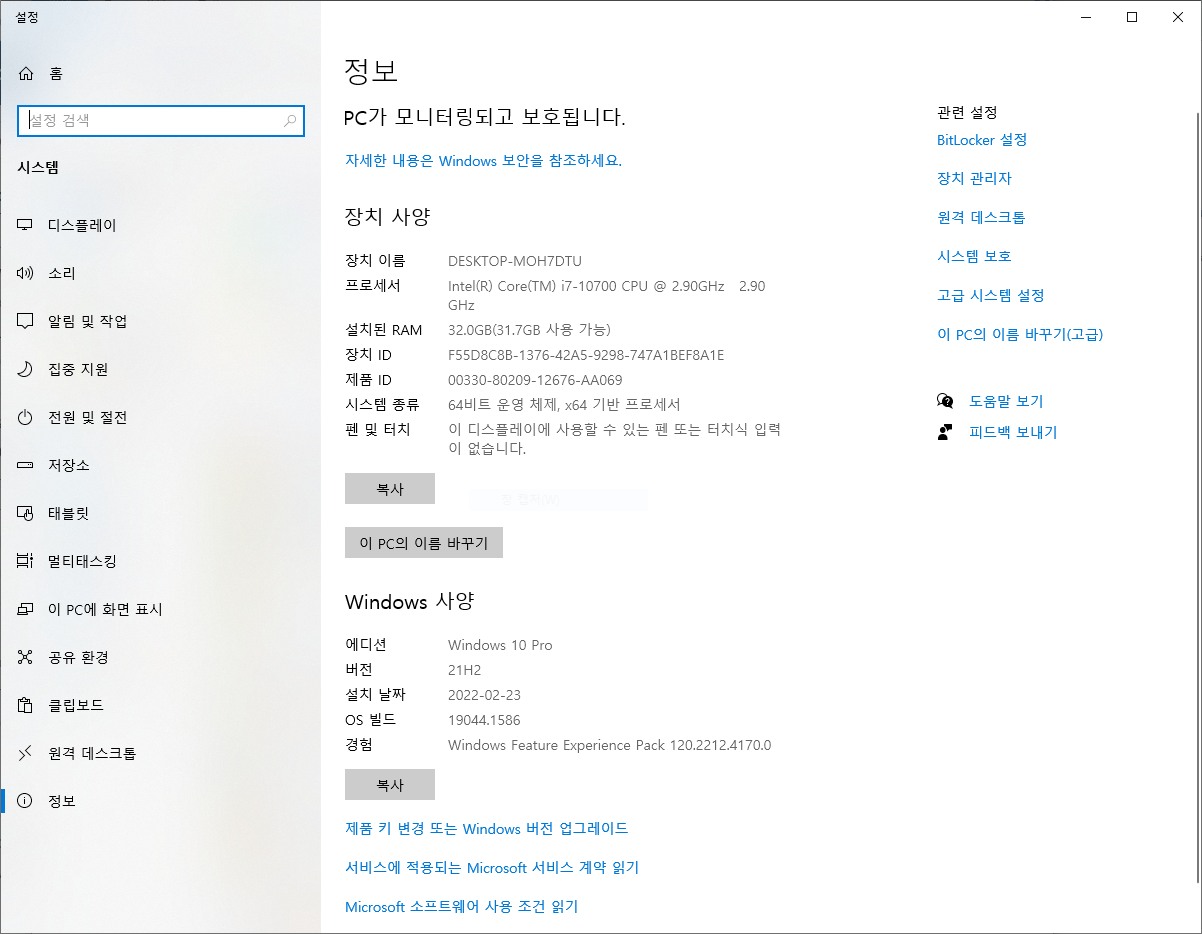
내 PC > 우클릭 > 속성 > 64비트인지 아닌지 확인
환경변수 설정
결정 트리
분류할때 로지스틱 회귀를 통해 값이 딱 2가지 였음
이번에는 2개 이상의 여러가지 값으로 분석을 해보자 => 결정 트리 이용
가장 엔트로피를 낮출 수 있는, 한번에 많이 구분할 수 있는 것
혼잡도, 지니계수 => 나눴을때 분포가 가장 잘 되는 방향으로(엔트로피 낮은 방향)
결정 트리를 이용해 6개의 클래스 비교할 예정임
어떤 데이터는 엔트로피, 지니 계수에 따라 좋은 결과를 얻는 여부가 다름.
UCI Machine Learning Repository에 접속해 human activity recognition을 검색해 센서 데이터 다운로드
파이참으로 폴더 정리한 후에 raw 데이터 확인
7:3정도로 train set, test set을 분리해놈
주피터 노트북을 열고 chapter11을 열자
중복컬럼이 있을때 판다스가 허용하지 않아, 버전을 낮추는 걸 추천하나 우리는 그냥 간다
중복된 컬럼이 꽤 많아서(561개 데이터 중)
무시하고 그냥 간다
shift+enter를 치면 아래 행이 생긴다.
딥기초 플젝 학습을 위한 팁
training data set이 많을 수록 좋음
학습을 하려면 train set 필요
학습을 잘 했는지 평가하기 위해 test set으로 성능 평가
시험 공부를 하려면 시험 범위 내 잘 공부해야
공부를 잘 하고 있나 확인하기 위한 모의고사 => train set으로 성능 평가
모의고사랑 실제 문제랑 다를 수 있음
6만장 쓰는 데 시간 몇 시간?
각기 다른 사람들에게서 손글씨 받음
=> 현실적으로 불가
어그멘테이션를 통해 회전, 크기를 변경해 학습 성능을 높인다.
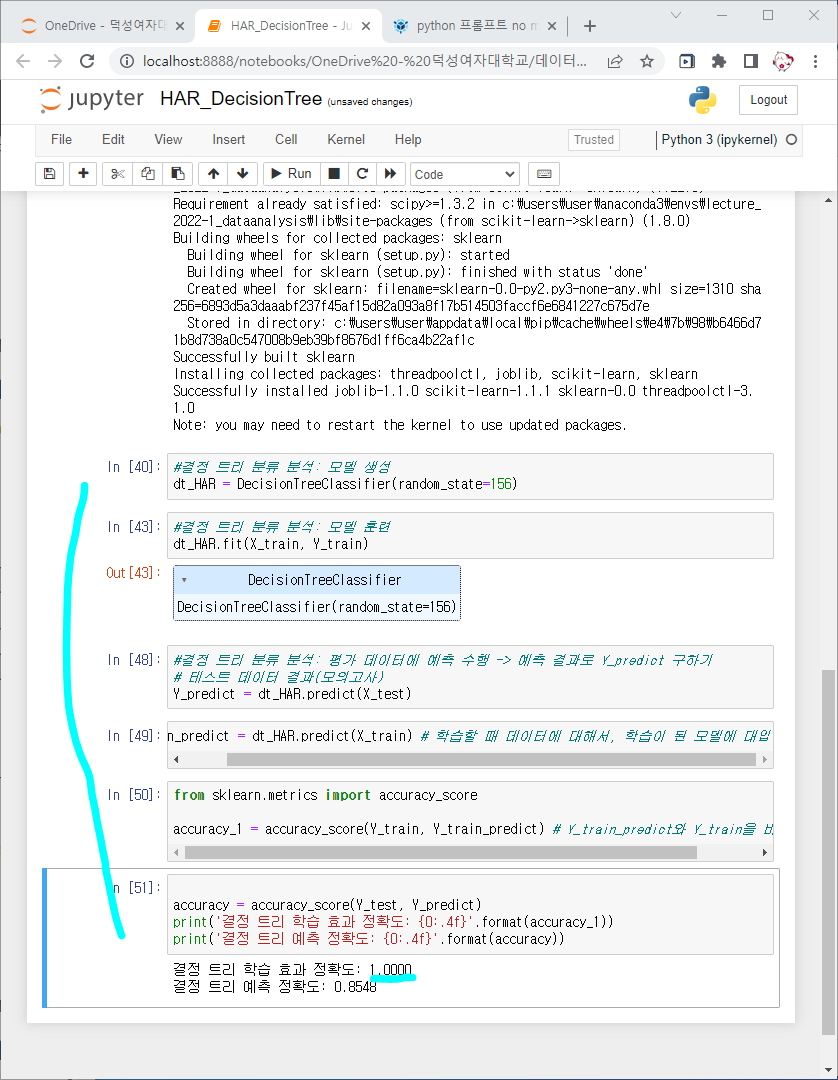
train data set에만 최적화되어 있는상태임
따라서 선생님이 알려주지 않은 문제까지 잘 학습할 수 있도록 해보자
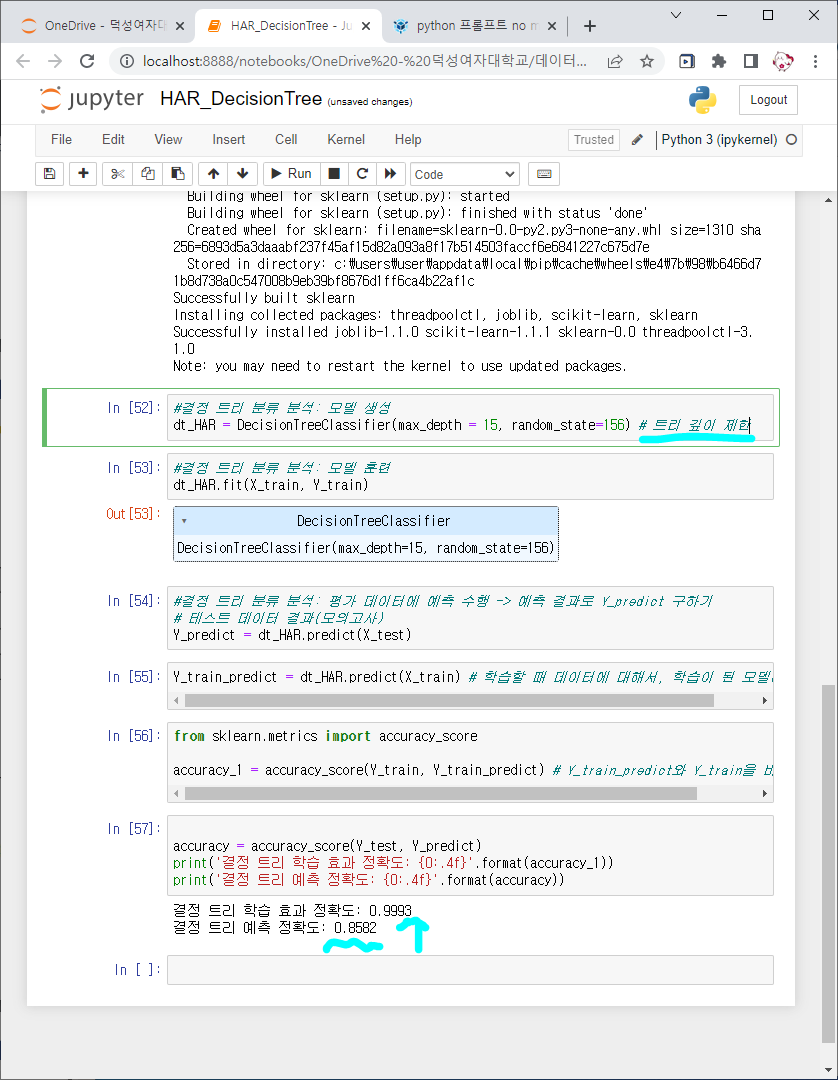
test set에 대한 정확도가 올라감
12,14로 두면 test set에 대한 accuracy가 더 올라가지 않을까!
ㅇㅇ 맞았음
12일때 트리 예측 정확도: 0.8646

학습데이터가 최대가 될 때 까지 주는 값들은 None이다.
그리드 서치
정확도를 향상 시킬때까지 계속해서 돌리는 과정
학습률, 이미지 데이터로 CNN이라면 커널의 개수를 얼마, 사이즈 몇개? => 하이퍼파라미터 를 계속 변경해야 함
자동으로 모델을 몇개 만들어서 돌려라!
validation) Train set 자체 내에서도 5등분으로 나눠서 4개를 학습해보고 ....
