Kernel > RunAll 하면 모두 실행됨
훈련 데이터셋에서만 최적화된 모델이 되버림 => 오버피팅(과적합)
따라서 모든 훈련 데이터셋에서 몇 퍼센트를 떼어놓고 이용한다.
결정트리 매개변수 매개변수로
criterion='entropy'을 주면 정확도가 올라가는 방향
그리드 서치
search space 내에서
max depth같은 경우 => 2, 4, 6, 8, 10으로 설정을 해두고 가장 정확도가 높은 하이퍼파라미터를 구한다.
max depth: 트리의 깊이
결정을 할 때 sample이 나뉜다.

8일때, 8/16/24, 16일때, 8/16/24로.. 총 9개의 모델 생성
그리드 서치를 이용해 여러개 파리미터 중 최고의 효과를 나타내는 파라미터 선정 가능
accuracy를 높게 하는 매개변수
Random Forest
#기본적인 randomforest모형
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score # 정확도 함수
clf = RandomForestClassifier(n_estimators=20, max_depth=5,random_state=0)
clf.fit(X_train,Y_train)
predict1 = clf.predict(X_test)
print(accuracy_score(Y_test,predict1))앙상블(=조화, 섞다)
Estimator의 경우 나무를 20개 만들겠다.
decision의 경우 나무를 한개만 만듦.
561개에 대해 전체 조건을 따져 나무를 한개 만들었음
- 트리 개수, max_depth 증가 시 정확도 높아질 수도
- search space를 줄여나감
- 결정 트리보다는 random forest 쓰는게 효과적임(다수의 힘을 빌린다.)
feature 중요도 파악
import seaborn as sns
import matplotlib.pyplot as plt
feature_importance_values = best_dt_HAR.feature_importances_
feature_importance_values_s = pd.Series(feature_importance_values, index = X_train.columns)
feature_top10 = feature_importance_values_s.sort_values(ascending = False)[:10]
plt.figure(figsize = (10, 5))
plt.title('Feature Top 10')
sns.barplot(x = feature_top10, y = feature_top10.index)
plt.show()feature 이름 중복으로 원하는 결과가 나오지 않음
0~560까지 숫자로 사용했음 => 따라서 해당 이름을 feature name에서 가져와야!
graghviz 사용
주피터 노트북에서 graghviz 설치
pip 앞에 !를 붙여주자
!pip install graphviz
from sklearn.tree import export_graphviz
import graphviz
#export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일 생성
export_graphviz(best_dt_HAR, out_file = "tree.dot", class_names = label_name, feature_names = feature_name, impurity = True, filled = True)
#위에서 생성된 tree.dot 파일을 Graphviz가 읽어서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
g = graphviz.Source(dot_graph) # 그래프를 보기 편하게 만들자
g.view()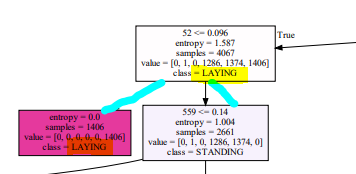
센서 측정 561개로 나뉜 후 ...
class 구분 가능
앙상블 하는 조건: 다수결, 트리에 따른 정확도
standing이 99% => 여기에 가중치를 두는 것이 의미 있음
군집분석
클러스터링
어떤 집단을 분류함
다뤄왔던 데이터 => feature 데이터(561개),암 데이터 정답이 있었음(정답 레이블 o)
군집레이블 => 정답레이블 x, feature만 있음
답을 알려주지 않고 150개 중 3개로 나뉘고, 국,영,수로 나뉜다라고 할때, 과목에 따라 분류를 해봐라 라는 것에 비유
패턴을 학습해서 알고 있음 => 컴퓨터에게 데이터를 주고 n개로 분류를 해봐 => 비지도학습
지도학습: 답o
비지도학습: 답x
마케팅 데이터 => 고객의 성향 분석
고객 성향 몇개로 분류?
10대/20대/30대, 여자/남자 ..
위 1000개의 데이터를 몇개의 군집으로 묶어줘!
4개의 분류가 너무 적으면 더 넓게 잡을 수도 있음
6월 16일 데분프, 데베구 기말
