개발환경
파이썬 버전, 라이브러리 버전(Numpy 버전 등)이 중요함.
함께 맞춰놓으면 디버깅 등 고생을 덜 할 수 있음.
아나콘다쓰는 이유: 개인 pc, 실험실, 딥러닝, 파이썬 등
개별적인 프로젝트를 진행하는데 개발환경이 다 다름!
다양한 개발환경을 지원하기 때문에!
과제 제출 해라!
8번 => pandas 객체를 바로 그래프 그릴 수 있음
그래프 종류에 따라서
x축이 나와야 되는게,
pandas에 컬럼, 인덱스 스위칭 기능있음
시간이 많이 걸림
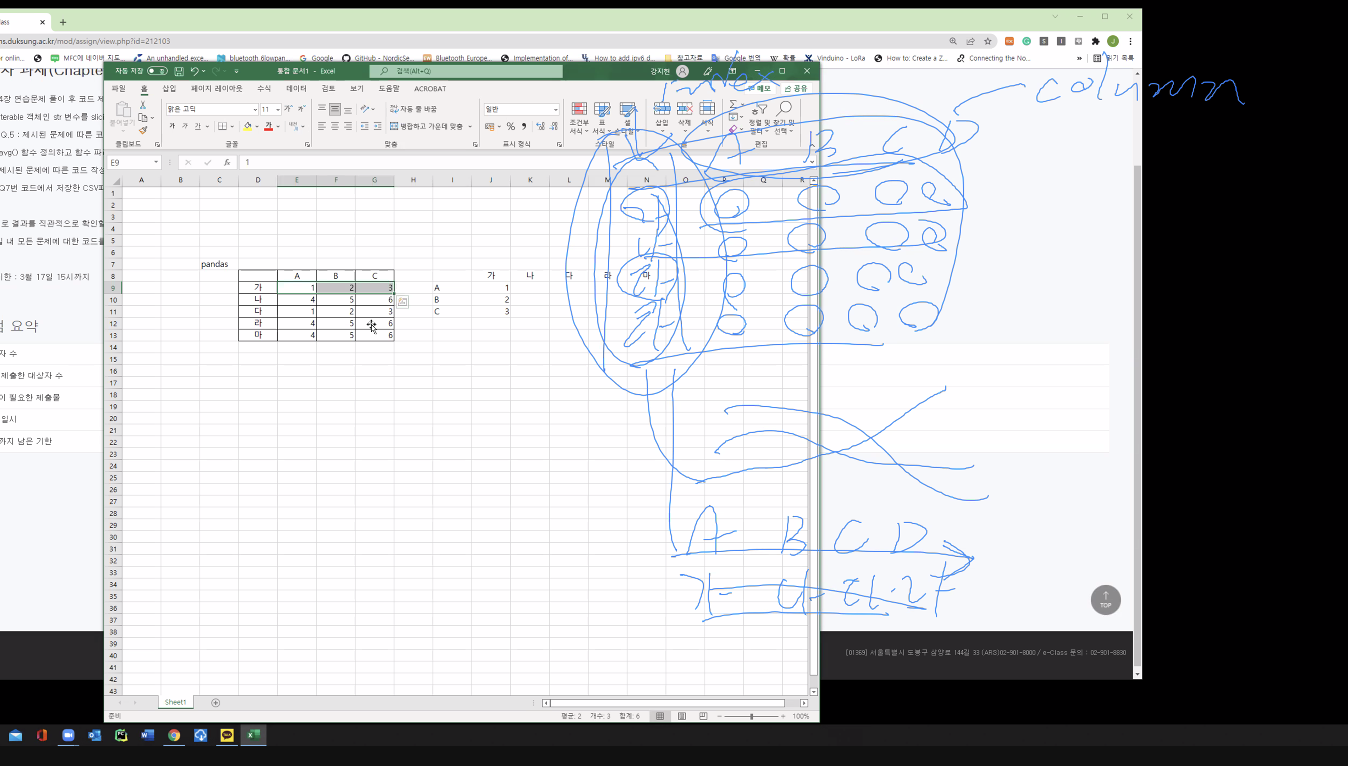
이렇게 변환이 가능하는 함수를 검색해서 간단히 해결하기!
한줄 한줄 읽어오는게 복잡하니까!
숙제 제출 후 다음시간에 예시를 보여줄것임
아나콘다
1. 가상환경 만들기
create => Lecture_2022-1_DataAnalysis => 생성
2. 패키지 설치
install
주피터(jupyter)
ipython(interactive python)
데이터는 어떤 성격, 도대체 뭘 분석? => 탐색적 데이터분석 방법론
데이터는 어떤 것들이 포함되어 있는지에 쓰는지에는 적합
주피터노트북에서 New>Folder 클릭한 후 새로 생성된 untitled Folder 클릭 후
Leture_2022-1_DataAnalysis 로 rename
오른쪽 콤보박스의 new 를 클릭하면 ipython 환경(interative python 환경)으로 쓸 수 있음
주피터노트북의 모드는 2가지.
회색 박스 영역을 클릭하면 편집 모드, 그 외 범위 클릭 시 실행 모드, 해당 줄을 실행하고 싶을 때는 shift(ctrl)+enter 하면 실행 가능
jupyter notebook 단축어
<셀 추가>
위로 셀 추가: [a]
아래로 셀 추가: [b]
선택 셀 삭제: [d][d] (d를 두번 누름)
선택 셀 잘라내기 (삭제로 써도 무방): [x]
선택 셀 복사하기: [c]
선택 셀 아래에 붙여넣기: [p]
이클래스에서 다운받은 파일을 열어보자
upload 클릭 후 다운받은 파일(확장자: ipynb => 주피터노트북으로 만든 확장자명)을 선택 후 열자!
numpy
numpy는 수치 데이터를 다루기 위한 라이브러리로 다차원 배열 자료구조인 ndarray를 지원하며 선형대수계산 등의 행렬 연산에 주로 사용됨.
기본으로 설치되는 라이브러리가 아니므로 명령프롬프트 창에서 pip 명령으로 설치한 후에 임포트를 해야한다!
pip는 파이썬 패키지 관리 시스템이다.
리스트 좋은 구조체 => 그러나 ! 연결성이 없음, 포인터를 따라가다보니 속도가 좀 느림.
배열로 구조체도 만들 수 있는데 access , 자료 계산 등에 용이하고 빠름(다음 데이터는 바로 내 뒤에...! 이처럼 연결되어있음)
리스트로 벡터, 행렬 연산 가능하되, numpy가 수치연산에 최적화되어있는 패키지임.

numpy는 10개의 요소가 있을 경우, 각각 연산해주지 않아도 한번에 연산 가능!
ex)
numpy: 100만개 요소, 각 항목에 x2 => 시간 11ms
리스트: 100만개 요소, 각 항목에 x2 => 시간 551ms
당분간 numpy를 자세하게 다루지는 않을 예정
numpy 기능을 한번씩 실행시키길 당부!
numpy 사용법을 한번씩 경험해볼것!(구글링하면 정보 진짜 많이 나옴)
기능을 사용하려면 어떻게 해야하지..? 정도!
넘파이는 배열과 비슷한 기능 제공(슬라이싱) + 행과 열의 형태 변경 가능
pandas
데이터분석에서 자주 사용하는 테이블 형태를 다룰 수 있는 라이브러리이다. pandas는 1차원 자료구조인 Series, 2차원 자료구조인 DataFrame, 3차원 자료구조인 Panel을 지원하는데 그 중 Series와 DataFrame을 자주 사용!
pandas역시 기본으로 설치되는 라이브러리가 아니므로 다음과 같이 명령 프롬프트 창을 열고 pip 명령으로 설치한 후 임포트 해야함.
code / markdown 등 선택해 작성가능
기능은 크게 2개 시리즈, 데이터 프레임(구조) 제공하는 모듈
1차원 적인 표 = 시리즈(컬럼 1개)
컬럼이 늘어나는 것이 데이터 프레임
(예제 보기위해 교재 사야하나...)
시리즈
딕셔너리 이용해 제작
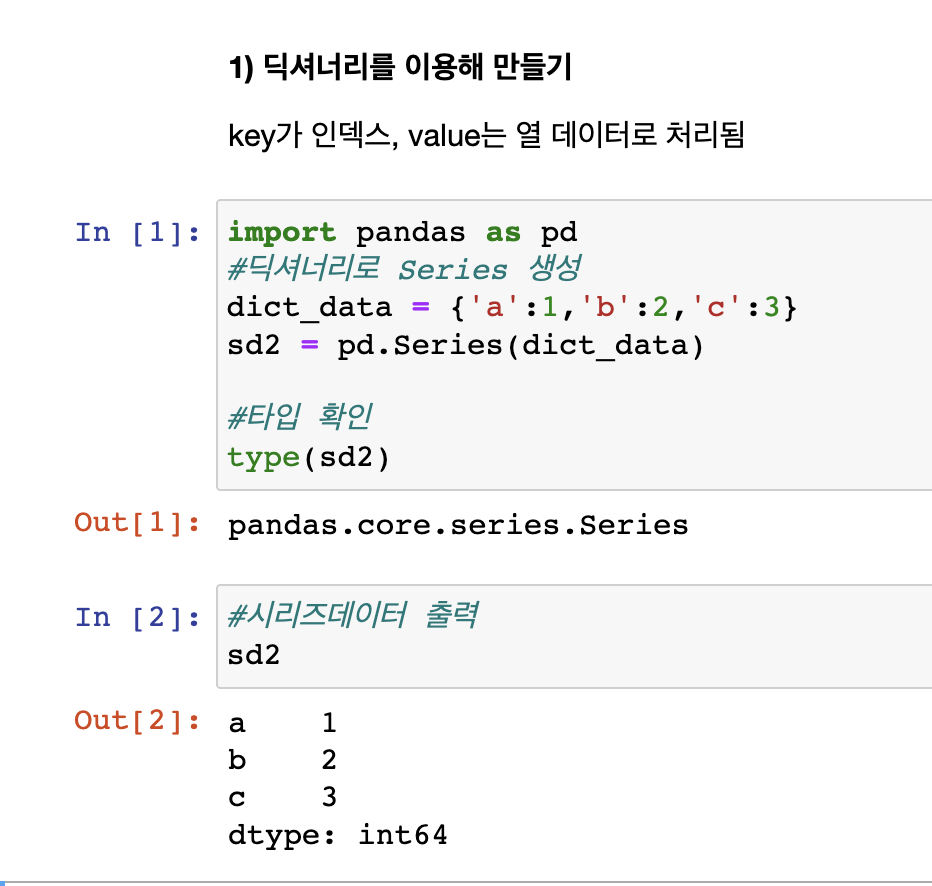
딕셔너리는 key와 value로 구성
시리즈로 만들때 딕셔너리의 key자체는 인덱스로 표현(인덱스는 숫자, 문자 가능)
리스트 이용
시리즈는 잘 사용하지 않음(1차원 데이터를 잘 다루지 않음)
csv 형태에서 한 열만 사용하더라도 데이터 프레임으로 불러오면 됨
값이 변경되지 않는 튜플로도 시리즈 생성 가능!
파이썬 딕셔너리, 리스트, 튜플 공부하자....
+) 03/22
두잇 buk.io 한달 이용권 구입했으니 두잇 파이썬 프로그래밍 책 보고 익숙해질 것
데이터 프레임
2차원 행과 열로 구성됨, 시리즈 여러개
딕셔너리
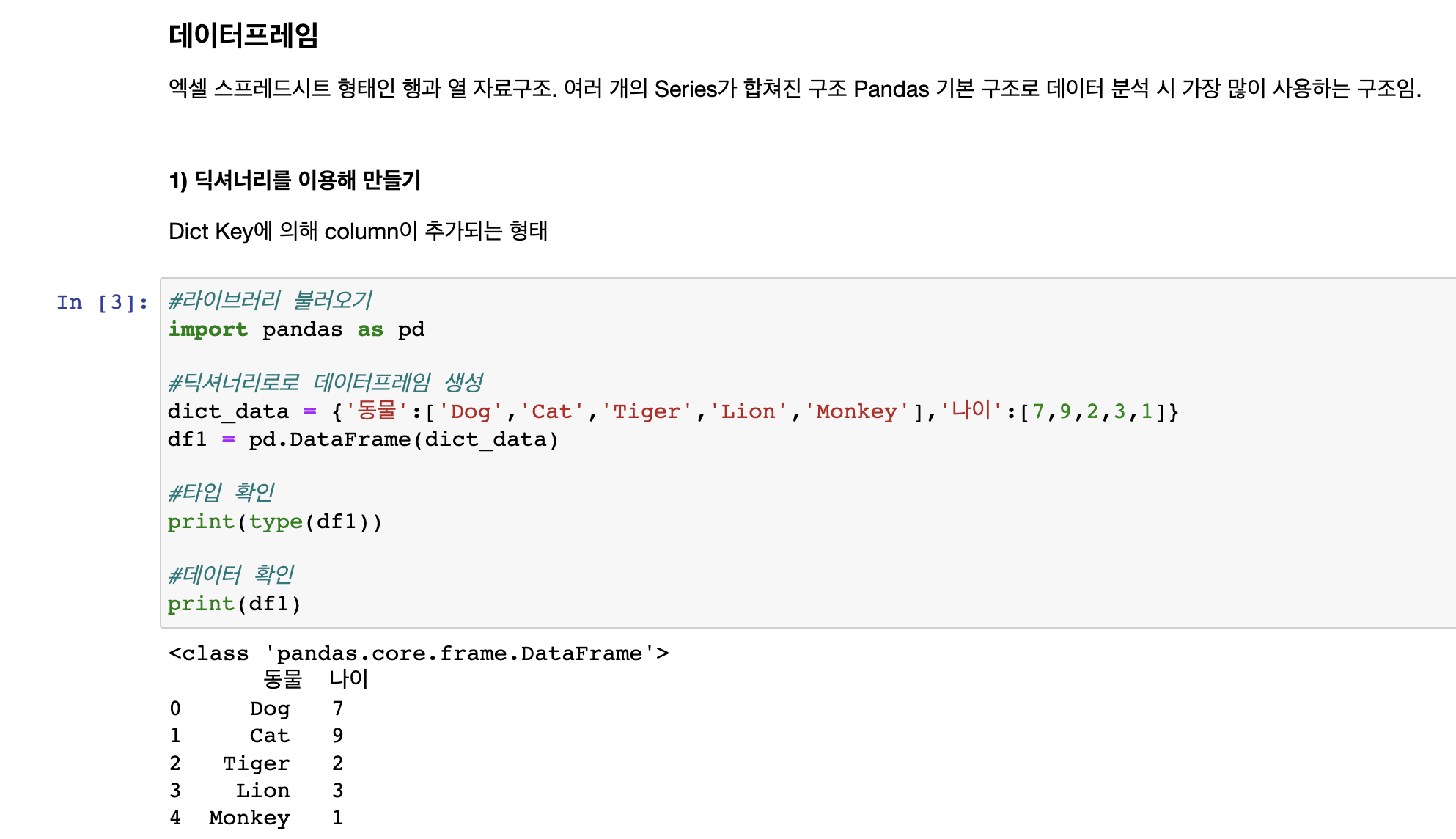
딕셔너리의 키는 컬럼이 된다.(동물, 나이)
인덱스는 0~4까지 할당이 되었는데, 직접 지정을 해주지 않았기에 default값이다.
리스트
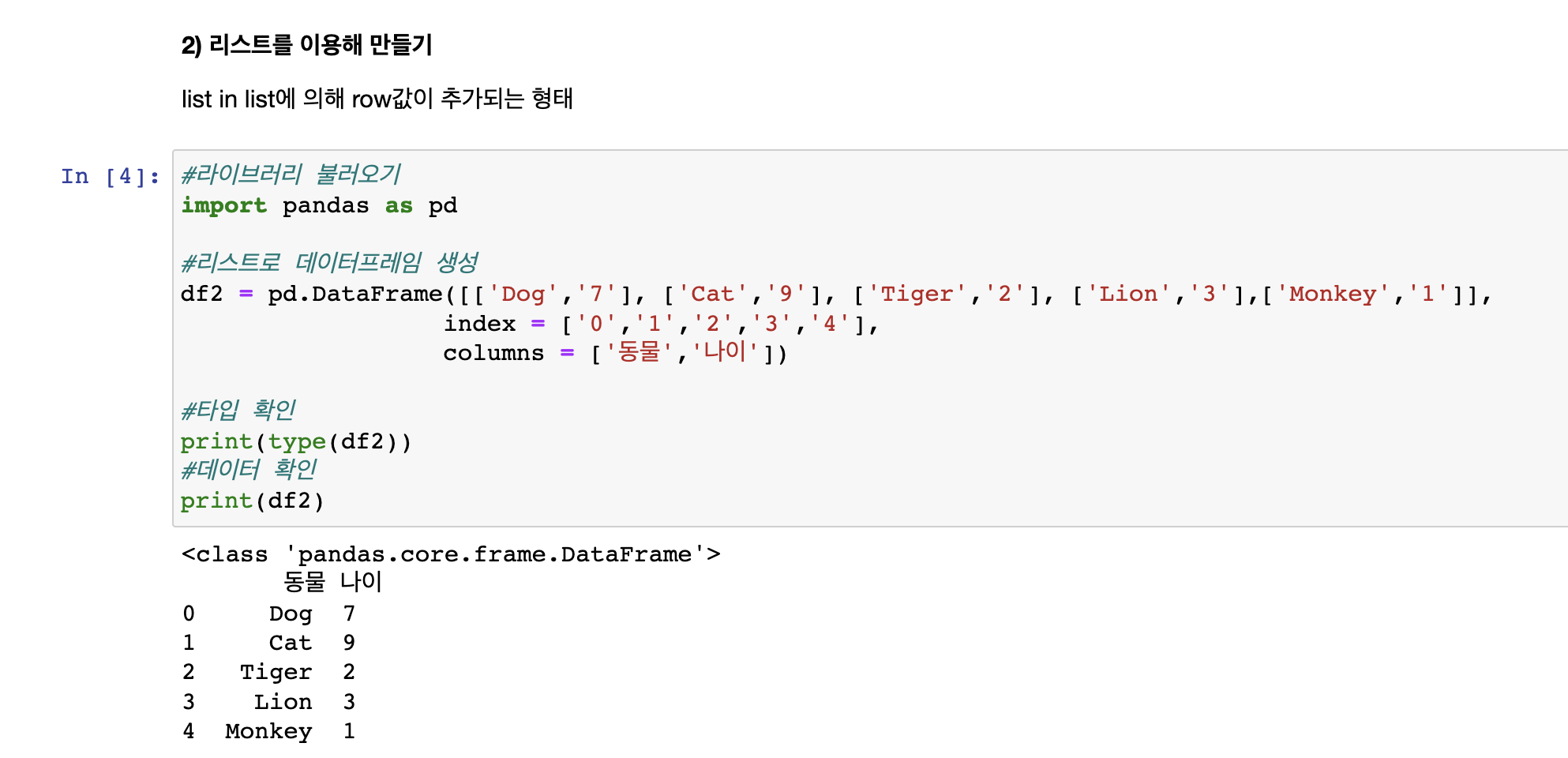
list 안 list에 의해 row(행)값이 추가되는 형태이다.
컬럼이 동물, 나이가 있고 list안 list로 선언해주면 딕셔너리와 동일한 결과 도출
집에서 꼭 실습하기
주피터노트북 코드를 준 이유 : 코드를 일일이 치게 되면.. 시간이 굉장히 오래걸림
따라서 코드를 실행시켜보기라도 할 것.
주석으로 단 것도 좀 보고(comment)
+) 수업시간에 해당 파일에 대한 메모를 남겨도 돼!
데이터 조작(기초 가공, 전처리)
데이터 프레임, 시리즈로 만듦
이렇게 만드는 경우는 잘 없음
코드로 데이터 명시해 한 경우 없음 => 파일에서 읽어오는 경우가 많음!
공공데이터 포털 회원가입 할 것
파일을 읽어올때 읽어오고 끝나는 것이 아니라, 필요한 데이터만 뽑아서 쓰는 경우가 많음(전처리, 데이터 가공의 기초단계임)
데이터 구조? 데이터 항목? 개수? 형식? => 데이터가 어떻게 생긴건지 탐색 필요!
- 시본(seaborn)
맷플롭립이 기본 그래프를 그려주는 모듈이라면 시본은 맷플롭립에서 몇 가지 기능을 추가한 것
시본 설치 시 샘플 예제 사용 가능한데, tips 이라는 데이터 셋 가져오기 가능
import pandas as pd
import seaborn as sns
import numpy as np이처럼 별명(short term)을 사용, 별명은 관습적이니까 맘대로 변경x
제공한 파일=> 실행된 결과가 있는 경우: 파일 내 실행결과가 있을 경우 저장 용량을 많이 차지하기 때문에 다른 사람에게 줄때는 실행 결과를 지우고 제공해야!
주피터 카테고리 Kernal > Restart&Clear Output으로 실행결과를 싹 삭제 가능
tips.info()을 통해 데이터 셋의 정보를 표현 가능!
Dtype의 category == string
sns.replot
시본을 통해 바로 그래프를 그릴 수 있음!
판다스로도 바로 그릴 수 있음
ex) pd에서 데이터 프레임(df)을 만들었을 경우
=> df.plot(색깔 등 지정 가능) 로 그래프 그릴 수 있음
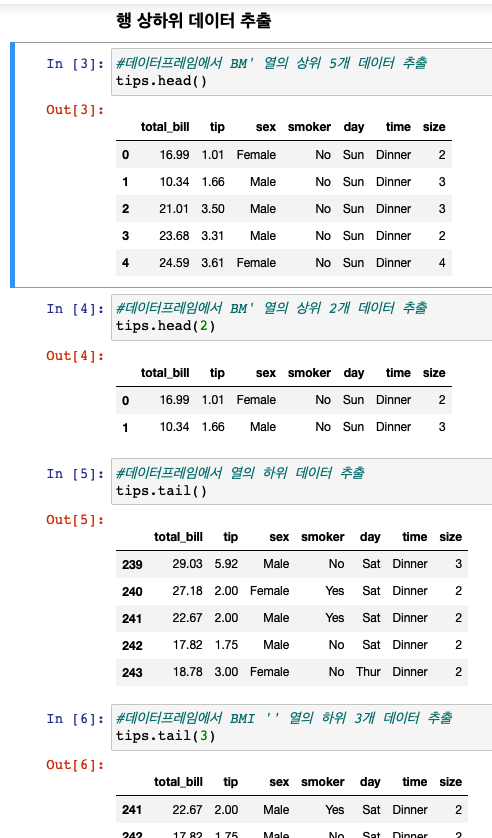
- 행 상하위 데이터 추출
tips.head()을 통해 상위 5개 데이터를 추출할 수 있다.
tips.head(2)을 통해 상위 2개 데이터를 추출할 수 있다.
tips.tail()을 통해 열의 하위 데이터 5개를 추출할 수 있다.
tips.tail(3)을 통해 하위 3개 데이터를 추출할 수 있다.
loc와 iloc, 인덱스와 행번호란?
인덱스를 명시해준 것도 있고, 아닌 것은 0~n까지 자동할당됨.
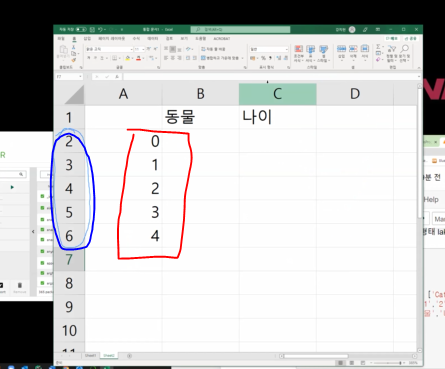
빨간 박스는 인덱스번호(내가 설정 가능, 문자든 숫자든)
파란 박스는 행번호(리스트에서의 인덱스와 같은 개념)
인덱스는 사용자가 임의로 설정, 변경 가능하다.
이때 파이썬에서의 리스트의 인덱스와 헷갈리면 안된다.
리스트에서
ex. list = [1,2,3,4,5]
가 있을때, 각 원소에 access하기위해 list[0] = 1을 이용.
이때 인덱스 값은 사용자가 변경 불가능.
pandas dataframe에서 행번호는 low의 개수이다.
파이썬의 list에서 access할 수 있는 인덱스와 같은 개념.
파이썬 기초 문법 때 인덱싱(indexing)개념에 대해 배움.
인덱싱은 데이터 프레임에도 적용 가능한데 판다스에서 특정 행(row)이나 열(column)을 골라낼 때 사용하는 방법으로 loc와 iloc가 있다.
loc
location의 약어로, 데이터 프레임의 행/칼럼의 label 이나 boolean array로 인덱싱하는 방법.
즉, 사람이 읽을 수 있는 라벨 값으로 특정 값을 골라오는 방법
- loc 사용방법
df.loc[행 인덱싱 값, 열 인덱싱 값]
loc[ ]에 하나의 값만 입력한다면 그에 해당하는 하나의 행만 뽑아온다고 생각하면 된다!
만약 df1.loc[0]을 입력할 경우 'df1이라는 전체 데이터 프레임에서 인덱스 이름이 0인 행만 출력해서 가져와!'라는 의미가 된다.
파이썬 기초 문법을 잘 안다면, '인덱싱'을 할 수 있다면 '슬라이싱'도 할 수 있지 않을까?라는 생각을 할 수 있는데, 판다스에서도 할 수 있다!
슬라이싱 개념을 loc에 적용해 데이터 프레임의 값들을 가져와보자.
특정 구간을 지정하지 않고 :로만 입력한다면 처음부터 끝까지! 로 범위가 설정된다.
따라서 df1.loc[:,:]라는 것은 'df1 라는 데이터 프레임에서 전체 행, 전체 열을 가져와!'라는 의미가 된다.
이제 자신이 가져오고 싶은 특정 구간을 지정해주면 되는데,
df1.loc[:,'Column1']로 작성해 전체 행을 추출하고 열을 입력하는 자리에 내가 가져오고 싶은 특정 칼럼명을 적어주면 된다!
(이 경우 굳이 loc를 사용하지 않고, df1['Column1']의 방법으로 훨씬 쉽게 특정 열을 가져올 수 있지만..)
만약 인덱스 이름이 0~4까지의 값을 가져오고 싶다면, df1.loc[:4, :'뽑고싶은컬럼명']으로 작성해주면 내가 원하는 범위에 있는 값들을 한번에 가져올 수 있다.
정리하자면, 슬라이싱에서 : 앞에 아무것도 안 쓰면 첫번째 값부터라는 의미이고, :의 뒤에 아무것도 안쓰면 끝까지 라는 의미가 된다.
또한, loc는 불린(boolean)으로 특정 값을 추출해올 수 있다.
전체 데이터 프레임에서 특정한 조건을 만족시키는 값들만 추출해오려면?
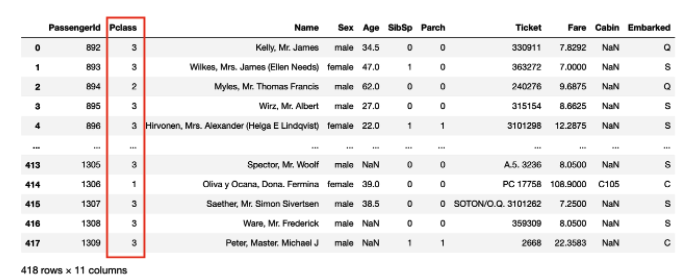
사진출처
'Pclass'라는 컬럼에서 값이 3인 값들만 추출하려면?
cond1 = df1['Pclass'] == 3
df1.loc[cond1]위와 같이 내가 추출하고자 하는 특정한 조건을 하나의 변수로 선언한 다음, 그 변수를 loc[]에 넣어주면 됨.
이러한 방법을 이용해 내가 원하는 조건을 충족하는 데이터만 뽑아낼 수 있는데,
loc[]안에 원하는 조건식을 작성하면 된다!
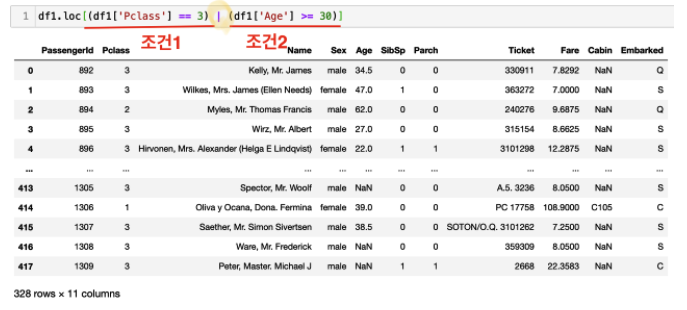
df1.loc[(df1['Pclass']==3) | (df1['Age']>=30)]으로, df1의 'Pclass'라는 컬럼에서 값이 3이거나 (|을 사용하면 '또는', &를 사용하면 '그리고'라는 의미) df1의 'Age'컬럼의 값이 30보다 크거나 같은 경우에 해당되는 값들만 출력하라는 의미!
iloc
iloc는 integer location의 약어로, 데이터 프레임의 행이나 컬럼의 순서를 나타내는 정수로 특정 값을 추출해오는 방법.
loc는 칼럼명을 직접 적거나 특정 조건식을 써줌으로써 사람이 읽기 좋은 방법으로 데이터에 접근하는 방법이었다면, iloc는 컴퓨터가 읽기 좋은 방법으로(숫자로) 데이터가 있는 위치(순서)에 접근한다고 생각하면 쉽다!
🫥 iloc 사용방법
df.iloc[행 인덱스, 열 인덱스]
앞서 loc에선 df1.loc[0]은 '전체 데이터 프레임에서 인덱스 이름이 0인 행만 추출해줘'라는 의미였다면, df1.iloc[0]는 '전체 데이터 프레임에서 0번째 행에 있는 값들만 추출해라!'라는 의미가 된다.
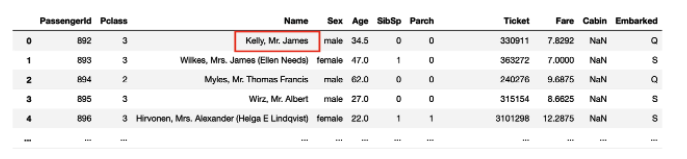
사진출처
빨간 박스 안에 있는 특정 값을 iloc를 이용해 추출해보자. 해당 값은 '0번 행, 2번 칼럼'에 위치한 값이다.
이는 df1.iloc[0,2]로 작성해주면 된다.
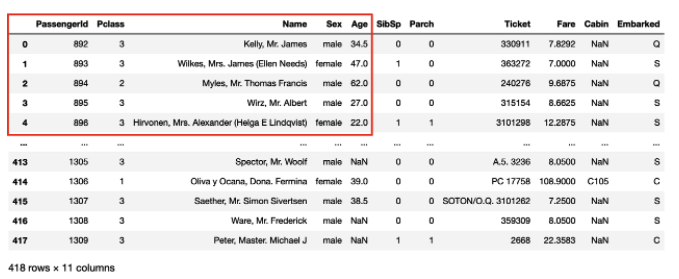
사진출처
이번에는 빨간색으로 표시한 구간을 iloc를 이용해 값을 추출해보자. 해당 값은 5번째 까지의 행,열로 범위를 지정할 수 있음.
df1.iloc[:5, :5]로 작성해주면 된다.
df1.loc[5]처럼 인덱스로 콕 집을 때는 해당되는 인덱스를 적으면 되었지만, df1.loc[:5]처럼 슬라이싱으로 범위를 지정해줄 때는 마지막에 쓴 숫자 전까지 출력해라~! 라는 것을 명심하자(항상 0부터 카운트한다는 것도 명심)
iloc의 이러한 특성을 이용해 특정 조건의 행 또는 열만 추출하려면?
전체 행 중에서 짝수번째에 위치한 행들만 추출하고 싶다면 df1.iloc[::2, :]으로 작성해주면 됨.
즉, '데이터 프레임 df1 전체 값 중, 2 간격으로 추출하고, 열은 전체 추출하라'라는 의미이다.

iloc에는 정수값만 들어가야 한다. 문자열을 입력하게 되면 에러가 뜬다.
loc: 인덱스 기준으로 행 데이터 읽기
iloc: 행 번호를 기준으로 행 데이터 읽기
몇번째 인덱스(키)를 가져올건지
tips.loc[-10]
여기서 행번호는 리스트의 인덱스와 같은 개념
끝에서 10번째 있는거 가져와! 라는 뜻
몇번째 컬럼 가져올 건지
등등 조건 설정해 검색 가능
파생변수(유도변수) 만들기
위 데이터프레임에는 sex, time, tip 등 여러개의 column이 있었음.
이때 특정 목적을 위해 기존 변수에서 새로운 변수를 유도해 생성할 수 있는데, 이를 파생변수라고 한다!
# 금액과 팁의 합계인 총액 (total) 파생변수 만들기
tips['total'] = tips['total_bill'] + tips['tip']
tips['total']참고 블로그
https://kkokkilkon.tistory.com/151
https://bigdaheta.tistory.com/42?category=958415
