preview
아나콘다 실행> Open in Terminal> pip install numpy matplot pandas seaborn
jupyter notebook 실행> lec2022-01-DataAnalysis 디렉토리 생성> 20220317 디렉토리 생성> pandas_sample2을 디렉토리안에 복붙함
컴퓨터에서 자기이름 폴더가 default 폴더임
파생변수까지 진도 나감.
데이터조작
matplotlib
라인플롯 차트, 바 차트, 파이 차트, 히스토그램, 산점도 등의 다양한 차트 그리기를 지원하는 라이브러리.
데이터 탐색이나 분석 결과를 시각화하기위해 많이 사용한다.
pip 명령을 사용해 설치한 후 임포트한다.
# matplot 임포트
import matplotlib
# matplotlib 버전 확인
matplotlib.__verison__
# pyplot 모듈 임포트하기
import matplot.pyplot as pltpyplot은 matplotlib의 주요 모듈이므로 함께 임포트한다.

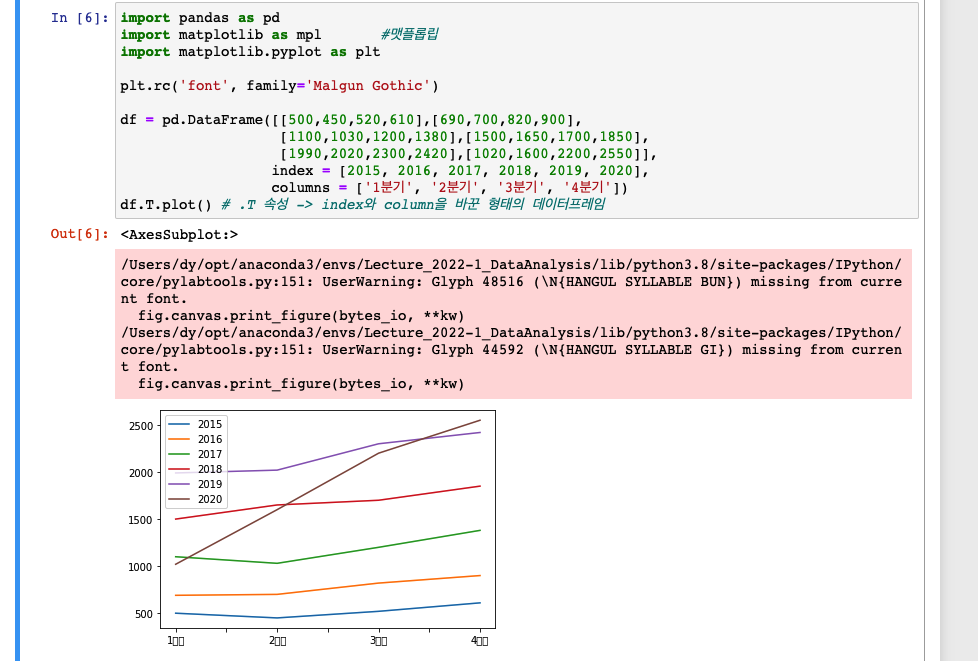
오류가 발생하는데, 한글 폰트 설치 관련 문제인 것 같다.
해결 방법은
import matplotlib.pyplot as plt
plt.rc("font",family="AppleGothic")을 입력해주자.
나는 os가 mac이라 기본서체가 윈도우의 Malgun Gothic이 아닌 애플고딕이라서 그런 것 이다!
또한 transpose된 그래프를 확인할 수 있다.
데이터조작(유형)을 통해 보기 편하게 만들기
1) 데이터 개수 확인
#데이터프레임 개수 확인
tips.count()
len(tips)2) 기타 보기
# 데이터프레임 인덱스 보기
tips.index
# 데이터프레임 컬럼 보기
tips.columns
# 행, 열 구조 보기
tips.values3) 정렬
# 지급액'열'을 기준으로 index(axis=0) 오름차순 정렬하기
# axis = 0은 row, axis = 1 column
tips.sort_value(by=['total_bill'], axis=0)
pandas에서의 axis란?
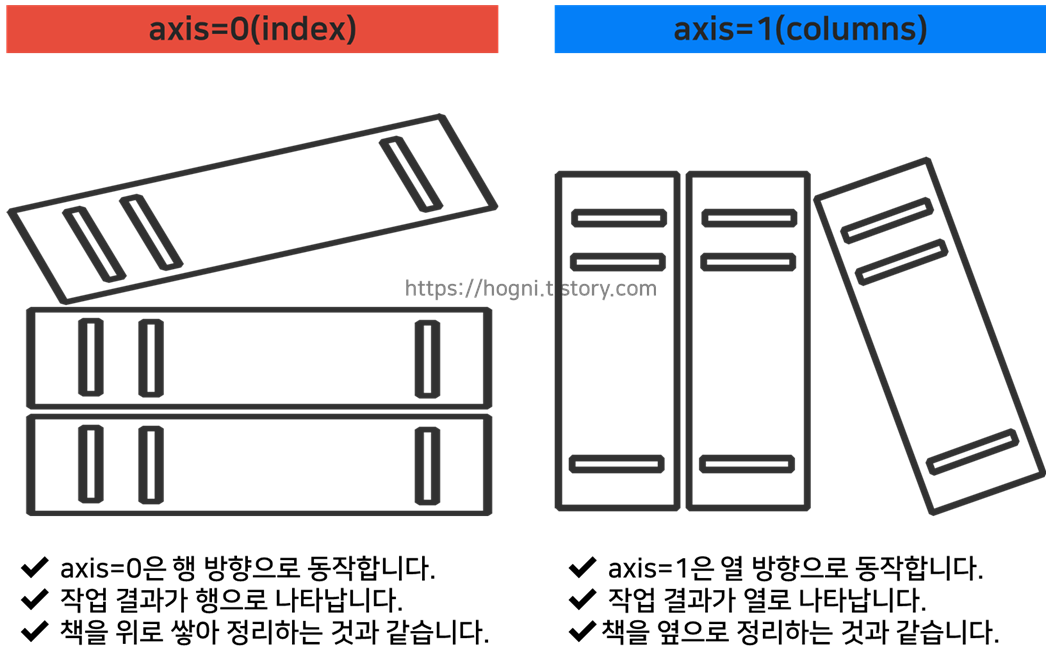
① axis=0(index)은 행을 따라 동작합니다. 각 컬럼의 모든 행에 대해서 작용합니다.
② axis=1(columns)은 열을 따라 동작합니다. 각 행의 모든 컬럼에 대해서 작동합니다.
사실상 데이터프레임을 가로로 붙이는 경우는 거의 없기 때문에 디폴트 값은 열 방향(axis=1)을 갖는다.
- 내림차순 으로 정렬하기
ascending=False 처리하기!
평균 vs 중간값
회사 연봉을 할때는 단순한 평균인 산출평균이 아닌, 중간값(median)을 찾아야 함!
Data cleansing or Data cleaning
필요에 따라서 잘못된 데이터, 데이터가 없을 수 있으니(결측데이터) 깔끔하게 데이터를 정리해야함!
사용할 데이터: 공공데이터포털> 데이터 목록> 2019 서울시 공공자전거 대여 데이터
데이터 불러오기
import pandas as pd
#파일경로를 찾고 변수 file_path에 저장
file_path= './pandas_sample_bycycle_dataset/공공자전거 대여이력 정보_1911.csv'
#read csv()함수로 데이터프레임 변환
df = pd.read_csv(file_path, engine='python', encoding='CP949')
# 결측데이터 확인
df.isnull( )
df.notnull() # 결측데이터는 false, 일반데이터는 true
# 결측값 개수
df.isnull().sum()결측데이터 제거
df.dropna(axis=0/1, how='any'/'all', subset=[col1, col2, ...], inplace=True/False)
dropna에 들어갈 수 있는 parameter들은 더 많지만 일단 대표적인 것들만 보겠습니다.
- axis = 0/1 or 'index'/'columns'
0 or 'index'
-> NaN 값이 포함된 row(행)를 drop (default 값입니다.)
1 or 'columns'
-> NaN 값이 포함된 column을 drop
- how = 'any'/'all'
any
-> row 또는 column에 NaN값이 1개만 있어도 drop (default 값입니다.)
all
-> row 또는 column에 있는 모든 값이 NaN이어야 drop
- inplace = True/False
True
-> dropna가 적용된 DataFrame 자체에 dropna를 적용
기존에 데이터프레임에 바로 적용됨(변수에 덮어쓰기)
False
-> dropna가 적용된 DataFrame는 그대로 두고, dropna를 적용한 DataFrame을 return
원하는 컬럼이나 행이 삭제되지만, 따로 변수에 저장을 해두지 않았기에 다시 데이터프레임을 출력하면 삭제되지 않은 것을 확인할 수 있다.
- subset = [col1, col2, ...]
subset을 명시하지 않으면 DataFrame 전체(모든 column & 모든 row)에 대해 dropna를 진행
subset을 명시하면 subset에 적힌 "column값에 대해서만 dropna를 진행"
#결측치가 있는 전체 행 제거
df_drop_allrow = df.dropna(axis=0)
df_drop_allrow
#결측치가 있는 전체 열 제거
df_drop_allcolumn = df.dropna(axis=1)
df_drop_allcolumn
# 하단 df.dropna(axis=0)와 동일
df[['대여소번호','대여거치대','이용시간']].dropna()
df[['대여소번호','대여거치대','이용시간']].dropna(axis=0)
결측데이터 대체
df.fillna(대체하고픈 값)
#결측값을 특정 값(0)으로 대체
df_1 = df.fillna(0)
df_1
#특정항목 "평균"으로 대체 => 애매할 때 많이 사용
df_6 = df.fillna(df['이용거리'].mean())
df_6파이참-아나콘다 가상환경 연결
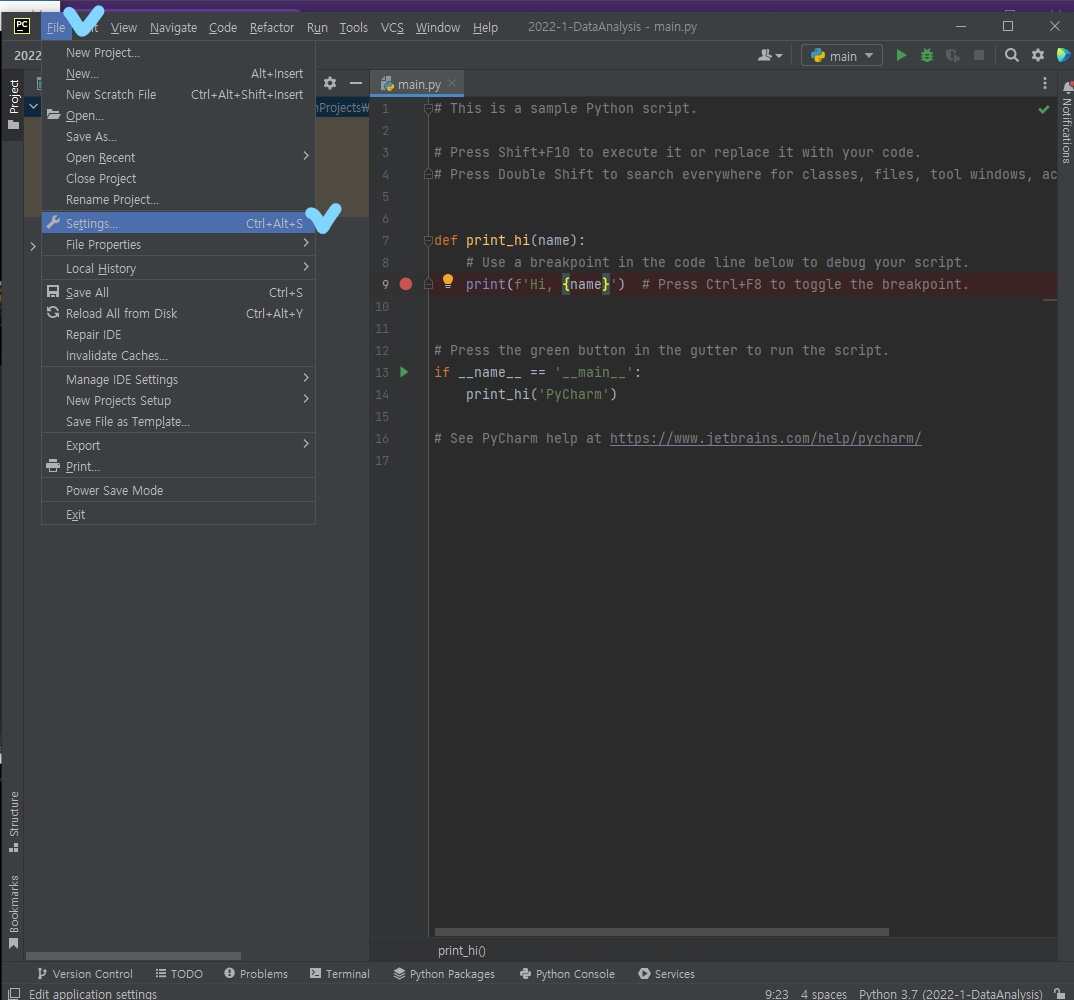
파이참> File> Settings >
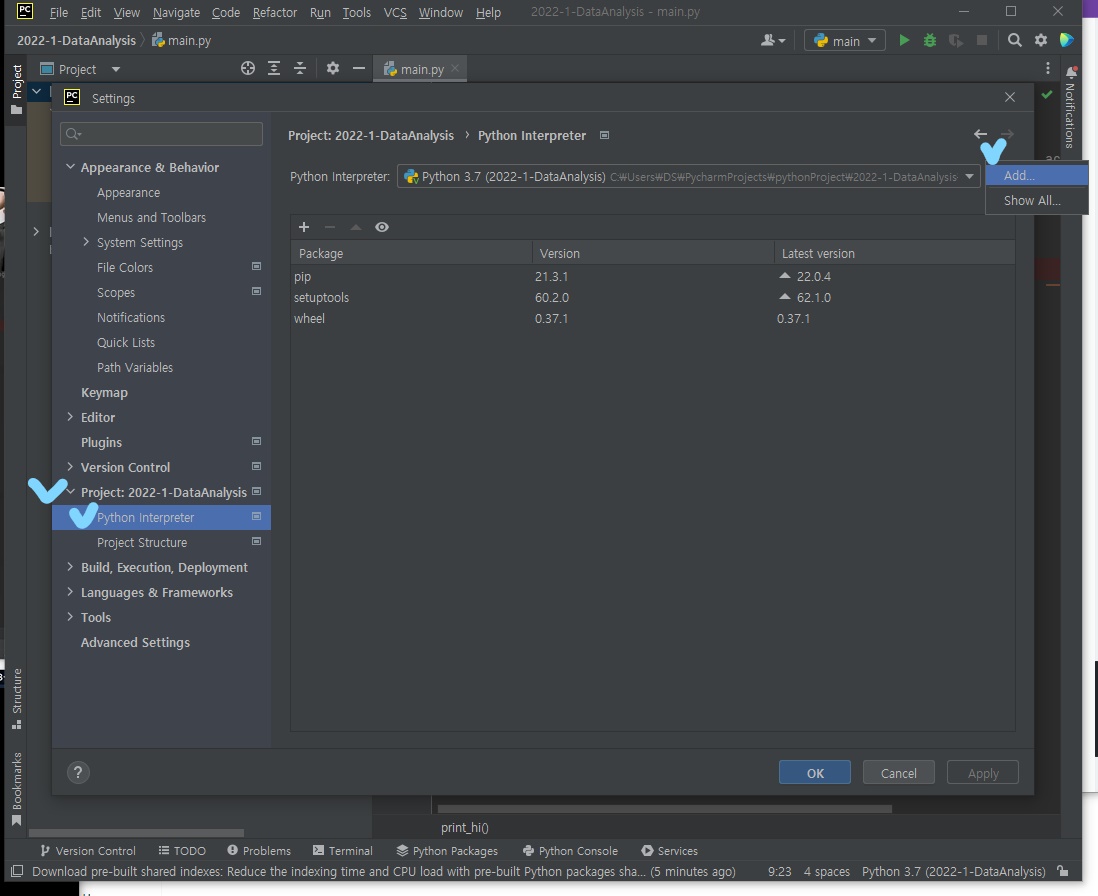
Project: '생성한 프로젝트명'> Python Interpreter > 인터프리터를 선택하는 콤보박스 옆 톱니바퀴 클릭 > Add
Anaconda로 가상환경을 만들었으니까 우측 메뉴바에서 Conda Environment 선택 > ... 박스 클릭 > Select Python Interpreter라는 팝업창에서 만든 가상환경 폴더 경로대로 들어가서 최종적으로 python.exe 클릭
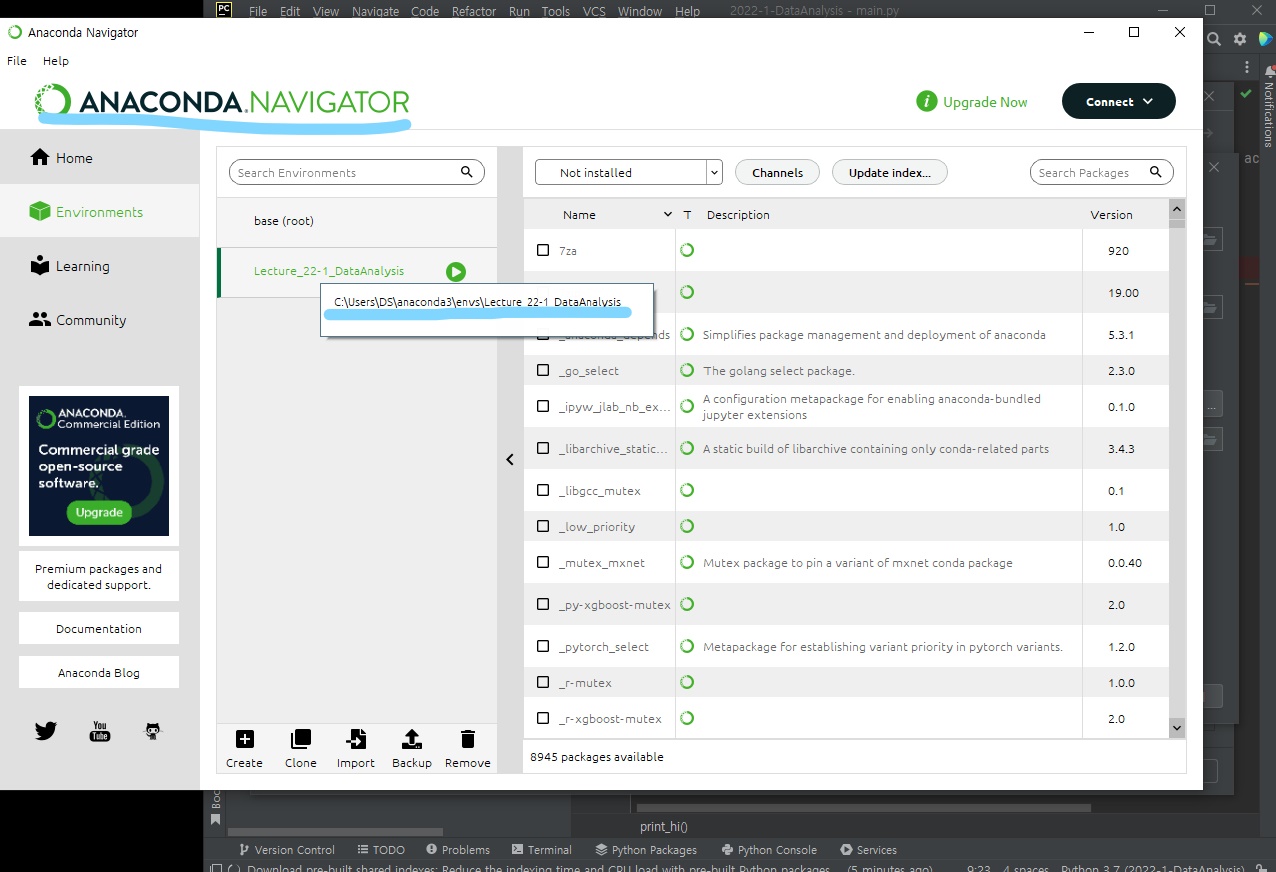
아나콘다 가상환경은 아나콘다 네비게이터 실행 후 만든 가상환경에 마우스를 올려두면 저렇게 경로가 보인다!
보통 경로는 Users\anaconda3\envs\만든 가상환경명 이다.
선택한 후 OK를 누르자.
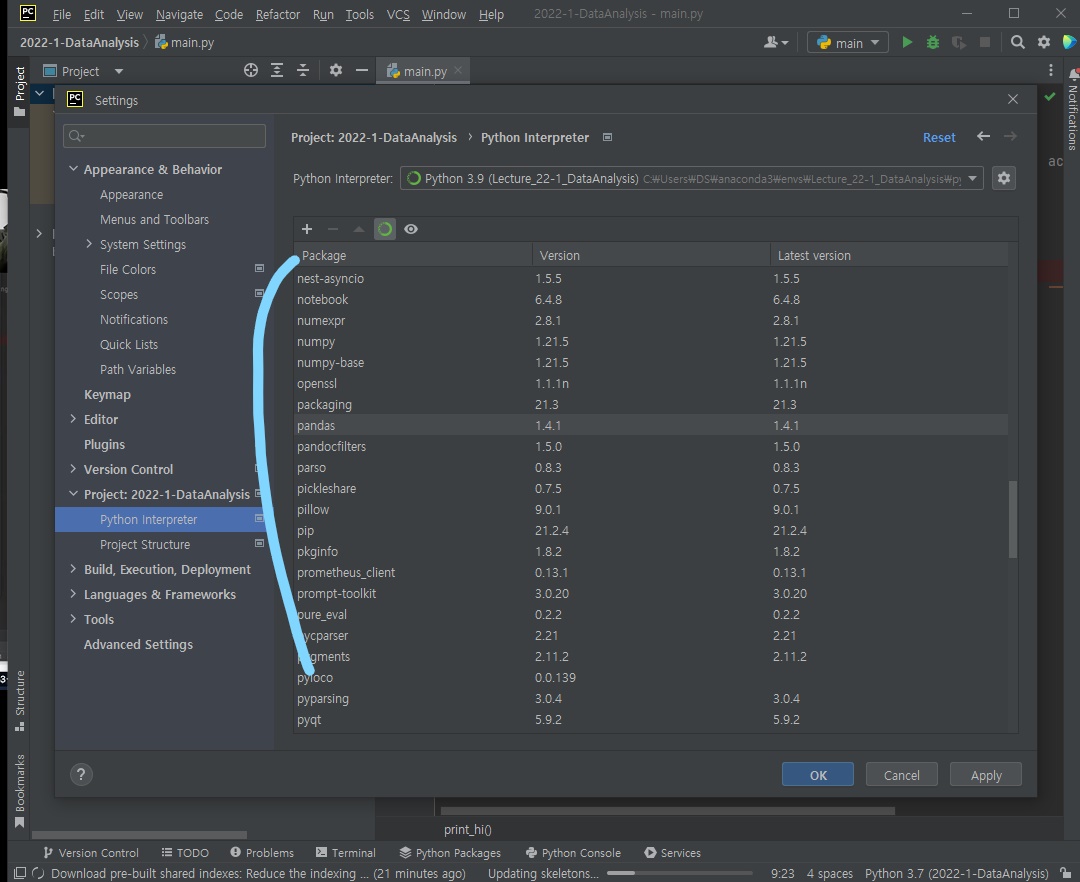
그러면 아나콘다 가상환경과 파이참이 연결되어 아나콘다에서 설치했던 파이썬 라이브러리 들이 보인다.
확인 후 OK를 누르자.
이제 파이참 터미널에서 pip를 해도 아나콘다 가상환경에 반영이 된다.
과제
공공데이터 포털 => 임의로 데이터 선택 => row 데이터가 어느정도 있는 것=> 1000개 정도 가지고 => pandas basic(주피터노트북)에 있는 기능 테스트하기.
배운 pandas 기능 10가지 정도..
report 형식으로 제출하기
어떤 데이터를 받았고?
그 결과
주피터 파일을 제출하기
