퍼셉트론과 활성화함수
-
퍼셉트론: 입력값이 들어오면 가중치를 곱한 후 그 결과가 0보다 크면 1을 반환, 그렇지 않으면 0을 출력하고 그 값을 다음 층으로 값을 넘김
즉, 가중합산과 계단함수를 순차적으로 실행 => 계단함수는 퍼셉트론의 활성 여부 결정하기에 계단함수를 활성함수라고 부름 -
시그모이드: 신경망에서 자주 사용되는 활성화함수이다. 계단함수와 달리 S자형 곡선형태의 연속적인 함수임
-
계단함수와 시그모이드의 차이점은 0을 기준으로 입력값이 0보다 크면 1을 출력하고 0보다 작으면 0을 출력해서 사잇값을 표현할 수 없는 계단함수와 달리, 시그모이드는 부드러운 계단 함수 모양이라 값을 연속적으로 표현할 수 있다.
-
선형 vs 비선형 함수
선형: 출력이 입력의 상수배 만큼 변하는 함수
f(x) = ax + b(a와 b는 상수)비선형: 선형이 아닌 함수
신경망에 활성화 함수로는 비선형 함수를 사용 => 인공신경망의 자극치를 활성시키는 활성화 함수는 선형함수여선 안된다.
이게 무슨 말인가 하면,
h(x) = cx 와 같은 선형 함수를 사용한다면,
아무리 층을 깊게 하더라도 결국은 선형이 된다는 뜻이다.
말이 어려운데,
예를 들자면 h(x) 로 이루어진 신경망을 100층 쌓았다고 치자,
그러나 c(c(c(x))) .... 이런 식으로 반환 값을 인자로 쓰고, 그 반환 값을 인자로 쓰는걸 100번 반복하는 것 뿐이다.
이는 간단하게 a = (c^100)*x일 뿐으로, 결국 다층을 쌓는다 해도 1층과 차이가 없기 때문이다.
-
ReLU함수
0보다 큰 입력이 들어오면 그대로 통과시키고 0보다 작은 입력이 들어오면 0을 출력함. -
다차원 배열의 계산
넘파이의 다차원 배열을 사용한 계산법 => 신경망을 효율적으로 구현 가능
import numpy as np
A = np.array([[1,2],[3,4]])
print(A.shape) # 행렬 구조(?행?열)
B = np.array([[5,6],[7,8]])
print(B.shape)
print(np.dot(A, B)) # 행렬의 곱
# 2 x 3 행렬와 3 x 2 행렬의 곱 계산
C = np.array([[1,2,3],[4,5,6]])
print(C.shape)
D = np.array([[1,2],[3,4],[5,6]])
print(D.shape)
print(np.dot(C, D))
# 다음 코드의 문제점은?
print(C.shape)
E = np.array([[1,2],[3,4]])
print(E.shape)
print(np.dot(C, E))
# 2 x 3 행렬과 2 x 2 행렬의 곱 계산으로 오류 발생 => 행렬의 곱에서 서로 대응하는 차원의 수를 일치시켜야.
신경망에서의 행렬의 곱
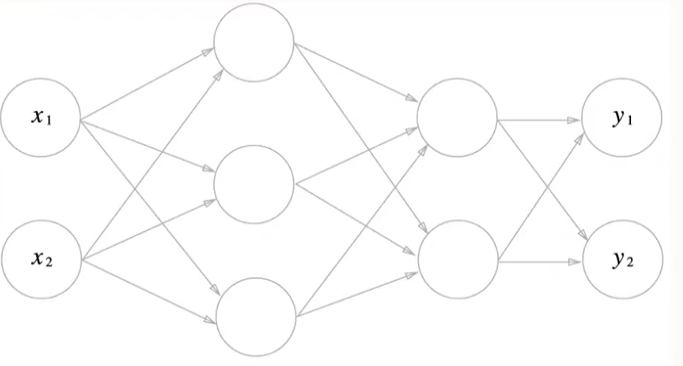
3층 신경망
- 입력층(0층) - 2개 노드
- 첫번째 은닉층(1층) - 3개 노드
- 두번째 은닉층(2층) - 2개 노드
- 출력층(3층) - 2개 노드
표기법
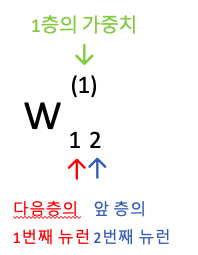
0층 -> 1층 신호전달
# a1 노드 계산의 파이썬 구현
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5],[0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2, 0.3])
print(W1.shape)
print(X.shape)
print(B1.shape)
A1 = np.dot(X, W1)+B1
print(A1)
def sigmoid(x):
return 1 / (1 + math.e ** -x)
Z1 = sigmoid(A1) # 활성화함수
print(Z1)1층 -> 2층 신호전달
# 1층 => 2층 신호전달 구현
W2 = np.array([[0.1, 0.4],[0.2, 0.5],[0.3, 0.6]])
B2 = np.array([0.1, 0.2])
print(Z1.shape) # (3, )
print(W2.shape) # (3, 2)
print(B2.shape) # (2, )
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)2층 -> 출력층 신호전달
출력층에선 다른 함수를 사용하지 않고 자기자신의 값을 그대로 내보낸다.
# 2층 => 출력층 신호전달 구현
def idenity_function(x):
return x
W3 = np.array([[0.1, 0.3],[0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = idenity_function(A3) # or Y = A3 도 같은 결과
print(Y) # 결과: [0.31682708 0.69627909]최종 코드
# 3층 신경망 구현 정리
import numpy as np
# 시그모이드 함수 구현
def sigmoid(x):
return 1/(1+np.exp(-x))
# 항등 함수 구현(입력을 그대로 출력)
def identify_function(x):
return x
# 가중치, 편향을 초기화 하고 network에 저장
# 딕셔너리 변수인 network에는 각 층에 필요한 매개변수(가중치와 편향) 저장
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5],[0.2, 0.4, 0.6]]) # 0->1 가중치
network['b1'] = np.array([0.1, 0.2, 0.3]) # 0->1 편향
network['W2'] = np.array([[0.1, 0.4],[0.2 ,0.5], [0.3, 0.6]]) # 1->2 가중치
network['b2'] = np.array([0.1, 0.2]) # 1->2 편향
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]]) # 2->3 가중치
network['b3'] = np.array([0.1, 0.2]) # 2->3 편향
return network
def forward(network, x): # 신호: 순방향(입력->출력)
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1 # 0->1 가중치 계산
z1 = sigmoid(a1) # 0->1 활성화
a2 = np.dot(z1, W2) + b2 # 1->2 가중치 계산
z2 = sigmoid(a2) # 1->2 활성화
a3 = np.dot(z2, W3) + b3 # 2->3 가중치 계산
y = identify_function(a3) # 2->3 활성화
return y
network = init_network()
x = np.array([1.0, 0.5]) # 입력값
y = forward(network, x) # 출력값
print(y) # [0.31682708 0.69627909]