preview
퍼셉트론: input-가중치를 곱해 => 값을 만들어 낸 후 편향을 더해 활성화함수를 통과시켜 어떠한 값을 출력할 지 결정.
- input
- 입력값에 가중치를 곱함
- 값에 편향 더함
- 활성화 함수
퍼셉트론이 모여서 신경망이 된다.
다차원을 이용해서 하기때문에, 행렬의 곱을 잘 알아야!
예를 들어, 2x3과 _2_x2의 경우 대응하는 행렬이 같지 않기 때문에 계산 불가
How to define the node count?
입력층의 노드 개수는 처리할 데이터의 수와 같다.
출력층의 노드 개수는 설계할 수 있다.
신경망을 어디에 사용하느냐, 최종 결과에 따라
출력층 설계하기
-
분류(classification)
데이터가 어느 클래스에 속하는 지 확인
사진 속 인물의 성별 확인 -
회귀(regression)
입력데이터에서 연속적인 수치 예측
사진 속 인물의 몸무게 예측하기
(ex. 돼지의 개체 별 몸무게 예측) -
항등 함수(Identify Function)
입력된 값을 그대로 출력 => 입력-출력이 같음 -
소프트 맥스
어떤 값들이 나오면 그 값에 비중을 따질때, 0.5, 0.6 ... 등 이 값이 전체에서 차지하는 비중이 얼마? => 비율로 환산.
평균과는 다름.
비율값이 나옴
전체에서 차지하는 비중이 얼마니?
소프트 맥스 함수의 구현
import numpy as np
a = np.array([0.3, 2.9, 4.0])
exp_a = np.exp(a) # 지수 함수
print(exp_a) # [ 1.34985881 18.17414537 54.59815003]
sum_exp_a = np.sum(exp_a) # 지수 함수의 합
print(sum_exp_a) # 74.1221542101633
y = exp_a / sum_exp_a
print(y) # [0.01821127 0.24519181 0.73659691]분류로 생각해봤을 때,
가장 큰 출력값은 4.0임
앞에서 들어온 입력 중 4.0으로 분류될 확률이 높음.
행렬에 대한 계산인 지 헷갈리지 말기.
소프트맥스 함수 구현 시 주의 사항
- 지수 함수를 사용하면서 발생하는 오버플로우
오버플로우란?
컴퓨터가 표현할 수 있는 숫자의 범위를 벗어남
지수를 사용하다보면, 표현할 수 있는 숫자의 범위를 벗어나면 결과가 다르게 출력됨.
E^10 => 20,000이 넘음
E^100 => 0이 40개 나 되는 매우 큰 값
E^1000 => 무한대 값
- 소프트 맥수 함수의 개선
shift해 표현 범위 내로 적용시킴.
a = np.array([1010, 1000, 990])
# print(np.exp(a) / np.sum(np.exp(a))) #소프트맥스 함수의 계산
# RuntimeWarning: overflow encountered in exp
c = np.max(a) # c = 1010(최댓값)
print(a - c) # [ 0 -10 -20]
print(np.exp(a - c)/ np.sum(np.exp(a - c))) # [9.99954600e-01 4.53978686e-05 2.06106005e-09]소프트맥스 함수의 특징
함수의 출력은 0에서 1.0 사이의 실수
함수출력의 총합은 1 => 소프트맥스 함수의 중요한 성질
소프트맥스 함수를 이용함으로써 문제를 확률적(통계적)으로 대응 가능
크기의 순서 차이는 발생하지 않음 => 단조 증가 함수
단조 증가 함수
함수가 단조롭다는 것이 무슨 뜻일까? '선생님의 목소리가 단조롭다'는 것은 곧 졸린 목소리라는 것이다. 어떤 특징이 일정하게 유지될 때 우리는 그것을 단조롭다고 여긴다. 단조 함수는 이와 마찬가지로 함수의 증감이 변하지 않는 함수이다. 다음은 함수 f: D \rightarrow Cf:D→C가 단조 증가 함수(monotonically increasing function)인 것의 수학적 정의이다 [1].
https://hashmm.com/post/monotonic-functions/
가장 큰 값만 필요할 때는 눈에 보이는대로 계산 가능해 생략 가능.
출력층의 뉴런 수 정하기
분류하려는 데이터에 따라.
개/고양이로 분류하려고 할때, 어떤 값이 들어오든 개/고양이 2가지로 분류됨.
산에 불이 났는지 확인하려면? 불 났으면 O, 불이 안났으면 X
분류하려는 클래스의 개수로 결정
손글씨 숫자 인식 실습
출력층은 : 10개(0~9)
-
학습
수집된 데이터 셋을 이용해 인식의 특징 찾아냄
학습의 과정은 무엇인가 입력된 데이터를 가지고 가중치와 편향을 구하는 과정임.
입력데이터가 많으면 많을수록, 학습 능력 향상.
복잡한 원리와 과정을 필요로 함 -
추론
행렬의 연산, 활성화 함수로 계산
학습된 신경망에서 새로운 데이터(학습, 테스트-평가)를 입력해 분류, 인식 과정
순전파(Feedforward Propagation)를 이용 -
실습
MNIST 데이터 셋을 이용한 손글씨 숫자 인식
학습의 과정은 생략(이미 학습된 모델 이용)
추론 과정만을 구현하고 실습을 진행할 예정임.
MNIST 데이터 셋
28X28크기(784), 각 픽셀은 1BYTE => 784BYTE
입력이 총 784개이어야, 실제 의미하는 숫자가 레이블로 붙어 있음.
-
실습을 위해 필요한 사항
1) ./
실행할 파이썬 코드가 있는 디렉토리
2) mnist.py
./dataset/mnist.py로 저장
3) functions.py
./common/functions.py로 저장
4) sample_weight.pkl
신경망 모델을 포함하는 파일
./(현재 디렉토리) 에 저장 -
MNIST 데이터 셋 로딩 및 형상 확인
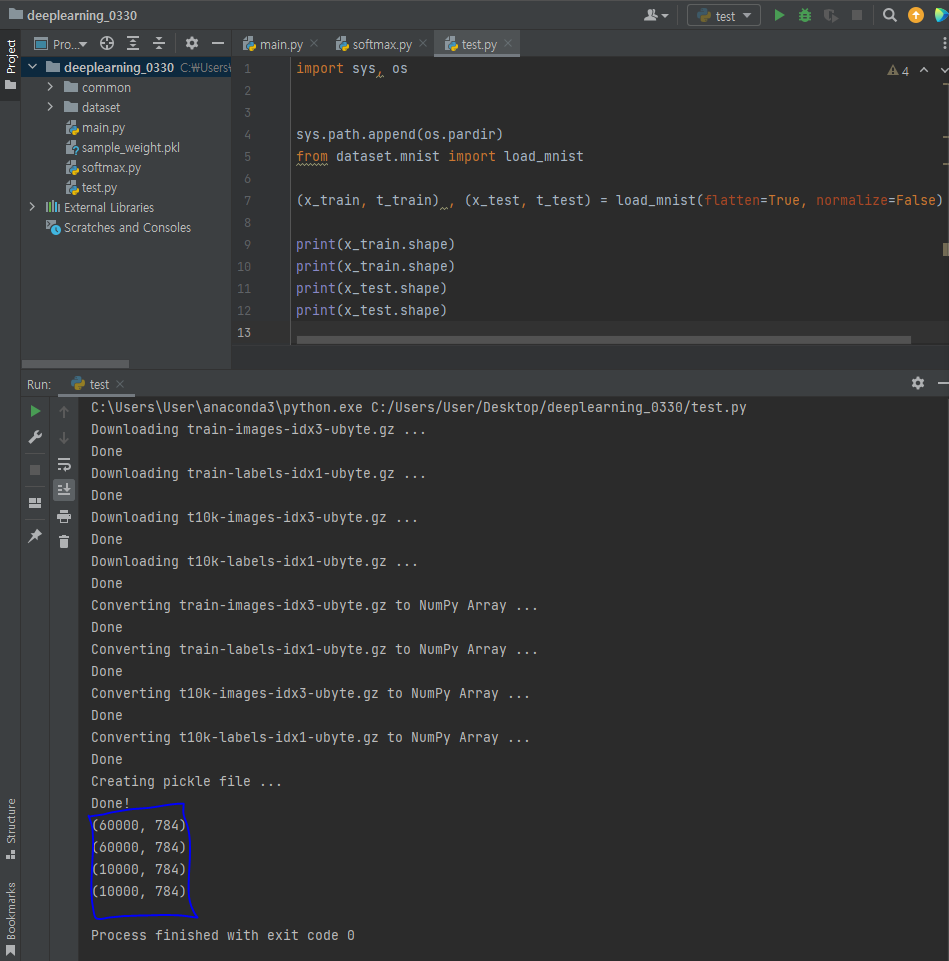
- 이미지 => numpy
import sys, os
sys.path.append(os.pardir) # 부모 디렉토리의 경로
import numpy as np
from dataset.mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[0]
label = t_train[0]
print(label) # 5
print(img.shape)
img = img.reshape(28, 28)
print(img.shape)
img_show(img)- numpy => 신경망 모델 => 입력 => 테스트 정확도 평가
