과제 => 어떠한 프로그램 보다 분석이 더 중요함
프로젝트는 숙제처럼, 기말시험없이 프로젝트 발표하는 형식으로
-
학습
-
학습의 방법: 확률적 경사하강법 이용했음(지도를 없애고, 안대를 끼고 낮은 골짜기로 향하는 모험가를 상상하자)
손실함수의 최솟값을 찾아가는 방법? -
모멘텀
운동량을 이용해 서서히 하강시키는 방법=> 속도조절
모멘텀 계수와 학습률 중요 -
AdaGrad 기법
학습률 조절
학습률 감소 기법
500g을 맞추기위해 한번 퍼 담을때 500g보다 작게 많이 푸고, 그 후로 조금씩 퍼담음.
전체를 균일하게 감소하기보다는 각각의 매개변수별로 감소시킴.
모멘텀, AdaGrad 기법 코드 복잡x
진동이 줄어든 모습 확인.
Adam 기법
모멘텀(의 장점: 공이 그릇 바닥을 구르는 듯한 움직임) + AdaGrad 기법(의 장점: 매개변수의 원소 마다 적응적으로 갱신 정도를 조정)
각각의 기법 => 특정 손실함수에 대해 진동을 막긴 했지만, 경우에 따라 다르다.
특정 모델을 학습할때 무엇을 선택?
=> 그래프를 그려보고 중심점으로 가장 빠르게 수렴하는 것을 택함.
학습 방법 계산 => 다 돌려보면 된다~
그러나 시간이 오래 걸리기 때문에 간단하게, 배치크기, 반복 횟수 로 확인해볼 수 있음
어떠한 학습 방법 적용?
최적의 해를 찾는 방법은 정해져 있지 x, 많이 해보면 노하우가 생긴다.
iteration: the repetition of a process or utterance.
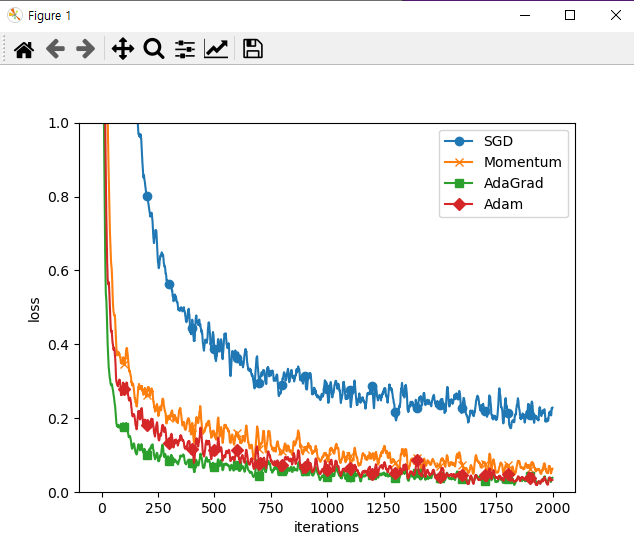
그래프분석
- AdaGrad가 가장 손실함수의 값이 낮다.
- SGD는 진동이 많으며 손실함수의 값이 가장 늦게 떨어진다.
- 반복하는 횟수가 많아질수록 결과가 좋진 않음(오버피팅)
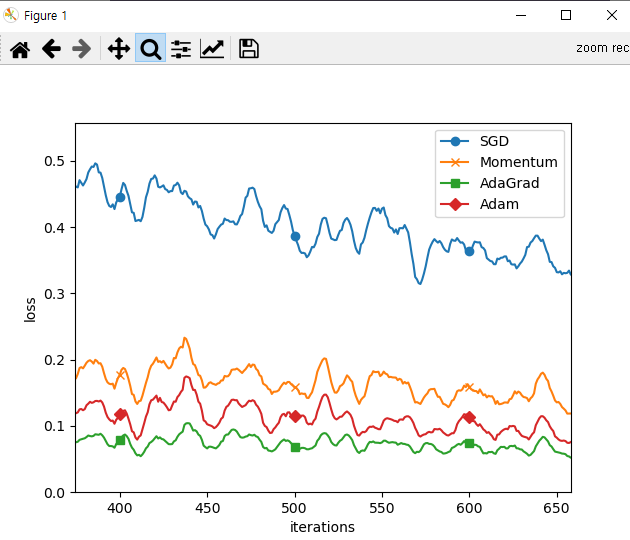
500번 반복시 결과의 차이가 심하다.
파라미터의 값을 변경할 수도!
배치사이즈를 바꿔보자(128 => 500)
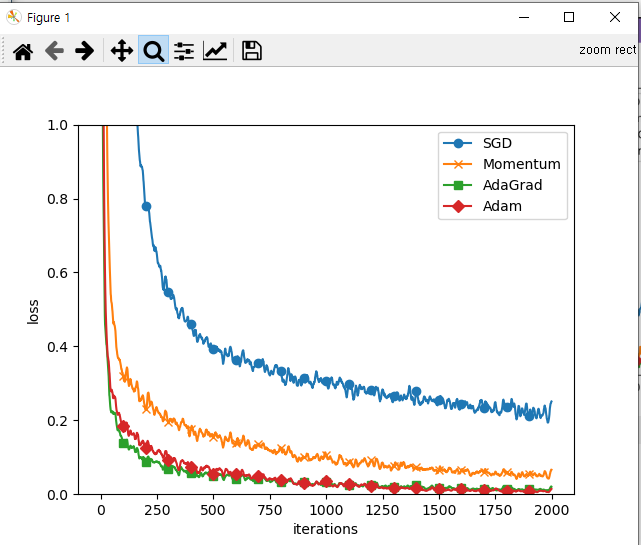
위의 그래프는 배치사이즈를 늘렸을 때의 그래프이다.
전체 코드
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet # two-layer가 아닌 multi_layer 사용
from common.optimizer import *
# 0. MNIST 데이터 읽기==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 500 # 배치 크기: 128(반복 횟수 줄이기)
max_iterations = 2000
# 1. 실험용 설정==========
optimizers = {}
# 수동이 아닌, 반복해서 할 것들을 파라미터로 정해놓고 파라미터만 변경하자!
# 딥러닝 조합들을 많이 시행할때 => 수동이 아닌 core 코드 + 반복하기위한 파라미터 정해놓고 loop를 돌게끔 하자
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
#optimizers['RMSprop'] = RMSprop()
networks = {}
train_loss = {}
for key in optimizers.keys(): # 위의 key들을 반복함
networks[key] = MultiLayerNet(
input_size=784, hidden_size_list=[100, 100, 100, 100],
output_size=10)
train_loss[key] = []
# 2. 훈련 시작==========
for i in range(max_iterations): # for문을 돌며 max_iterations 만큼 반복
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for key in optimizers.keys():
grads = networks[key].gradient(x_batch, t_batch)
optimizers[key].update(networks[key].params, grads) # optimizers[key] 변경
loss = networks[key].loss(x_batch, t_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print( "===========" + "iteration:" + str(i) + "===========")
for key in optimizers.keys():
loss = networks[key].loss(x_batch, t_batch)
print(key + ":" + str(loss))
# 3. 그래프 그리기==========
markers = {"SGD": "o", "Momentum": "x", "AdaGrad": "s", "Adam": "D"}
x = np.arange(max_iterations)
for key in optimizers.keys():
plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 1)
plt.legend()
plt.show()
