기말고사는 따로 없지만, 1주일정도 더 공부하고 퀴즈볼 예정(eclass)
플젝그룹은 random임
가중치의 초깃값 중요
예를 들어 산 등산에 있어, 맨 밑바닥부터 or 중간부터 시작하느냐는 큰 차이임. 가급적이면 높은 곳에서 시작하면 좋음.
초깃값 어떻게 설정 하느냐에 따라 학습의 패턴이 달라짐.
가중치를 작게하는 방향으로~
가중치 감소 기법
가중치의 매개변수 값이 작아지도록 학습하는 기법
오버피팅(특정 데이터셋에서만 과도한 학습)을 막아줌.
어차피 작아질 것을 최대한 작은 값에서 시작.
ex) 0.01*np.random.randn(10,100)
정규분포에서 생성된 값에 0.01배(표준편차가 0.01인 정규분포)
weight을 0으로 하면?
층을 거친 후 값은 only 편향값만 도출될 것.
이때, 동일한 값을 편향으로 주면?
- 출력값도 동일할 것 => 미분값이 0임
- 오차역전파법에서 모든 가중치가 똑같이 갱신됨
모든 가중치를 동일하게 하면 문제가 생긴다.
가중치의 초깃값 설정시 random하게 하는 것이 제일 좋다.
은닉층의 활성화 값 분포 = 활성화 함수의 출력값
- 시그모이드 함수
- 5층 신경망
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1/(1+np.exp(-x))
input_data = np.random.randn(1000, 100) #1000개의 데이터
node_num = 100 # 각 은닉층의 노드(뉴런) 수
hidden_layer_size = 5 # 은닉층이 5개
activations = {} # 활성화 결과 저장할 공간
x = input_data
for i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
w = np.random.randn(node_num, node_num) * 1
a = np.dot(x, w)
z = sigmoid(a)
activations[i] = z
# 히스토그램 그리기
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1)+"-layer")
if i != 0: plt.yticks([], []) # tick: 그래프의 축에 간격을 구분하기 위해 표시하는 눈금, matplotlib 눈금 표시하기
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()은닉층의 활성화 값 분포-히스토그램
표준편차를 바꾸는 것에 대한 의미?
편차: 가운데에서 얼마나 값이 펼쳐져 있느냐?
- 표준편차가 1인 정규분포로 초기화할 경우
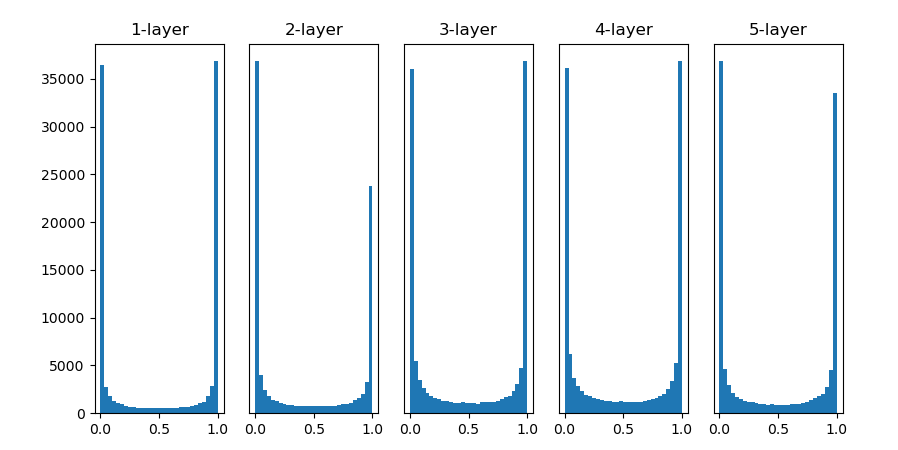
대부분의 값이 0과 1에 치중되어 있음 => 계단함수와 비슷한 결과값 도출
=> 역전파의 기울기 값이 점점 작아지다가 사라짐
왜 사라지지?
- 기울기 소실(gradient vanishing)
층을 깊게 하는 딥러닝에서 기울기 소실은 심각한 문제임
활성화 함수 분포가 골고루 안되어 있기에 학습 진행에 어려움
- 표준편차가 0.01인 정규 분포로 초기화 할 경우
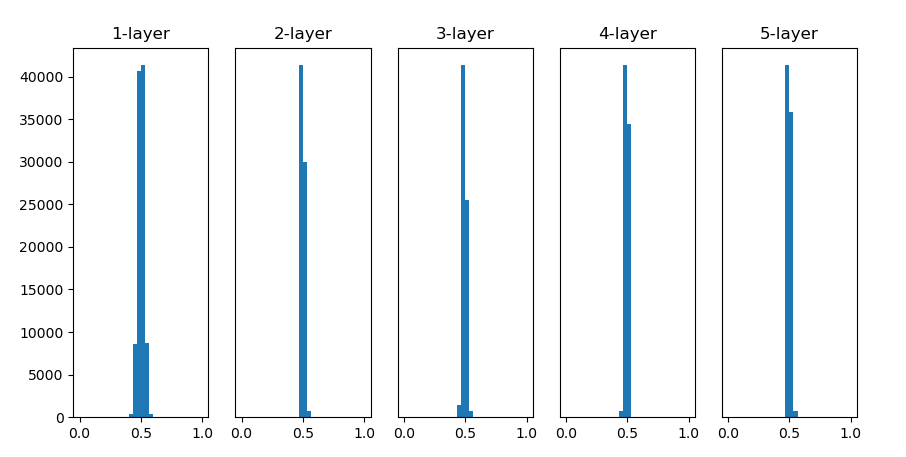
활성화함수를 통과한 값이 0.5에 치중되어 있음
=> 입력이 random하게 들어갔음에도 출력값이 비슷해짐
=> 표현력에 문제가 있음.
고양이, 강아지, 사자(random 값) 에 대한 다양한 출력값이 나와야하나 0.5같은 일정한 값이 도출되면 데이터에 대한 구분 불가
중요!
활성화 값이 일부에 집중 => 표현력 관점에서의 문제(다수의 뉴런이 거의 같은 값을 출력하고 있음)
문제점: 입력에 대해 제대로 구분하지 못함.
100개의 뉴런이 같은 값을 도출하면 1개의 뉴런만 있으면 될 일.
따라서, 가중치의 초깃값을 어떤 값을 잡느냐에 따라 학습의 방향성이 달라진다.
random하게 만들때, 얼만큼 폭넓게?
학습 성능에 영향 미침
은닉층의 활성화 값 분포-Xavier 초기값
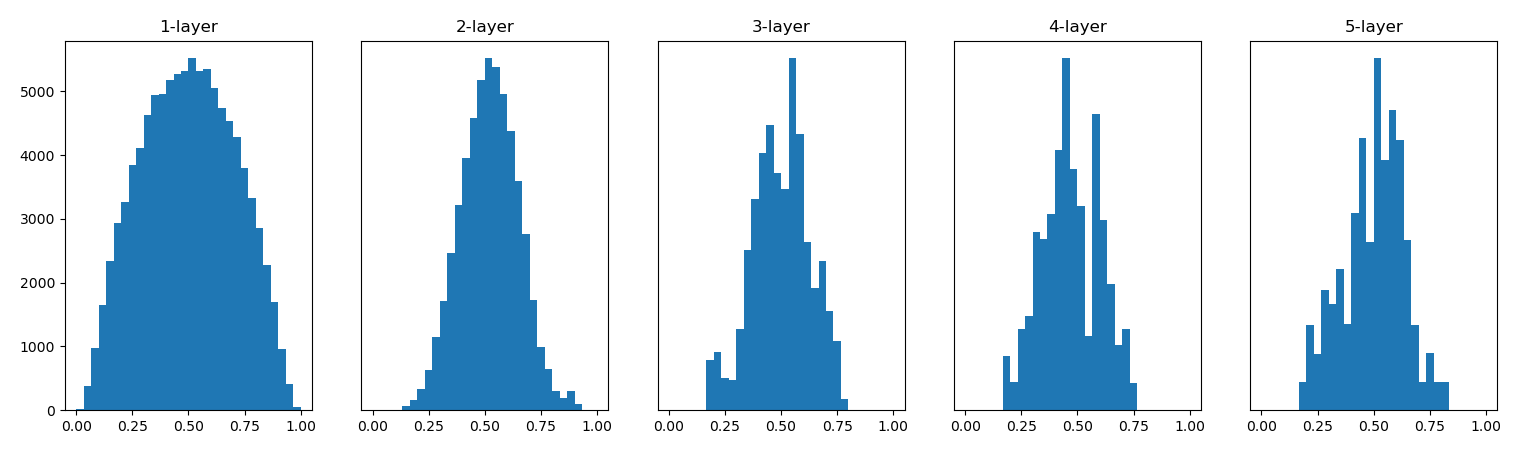
앞 계층의 노드에 따라 편차가 달라져야 할 필요성 느낌
=> 앞 계층의 노드가 n개 일 경우 표준편차가 1/루트n인 분포를 사용함.
앞 노드가 많으면 조금씩 좁게 표준편차를 정하자.
지금까지 활성화 함수는 시그모이드함수만 가지고 !
히스토그램은 해당값의 빈도수를 표현
은닉층의 활성화 값 분포-He 초기값
He 초기값
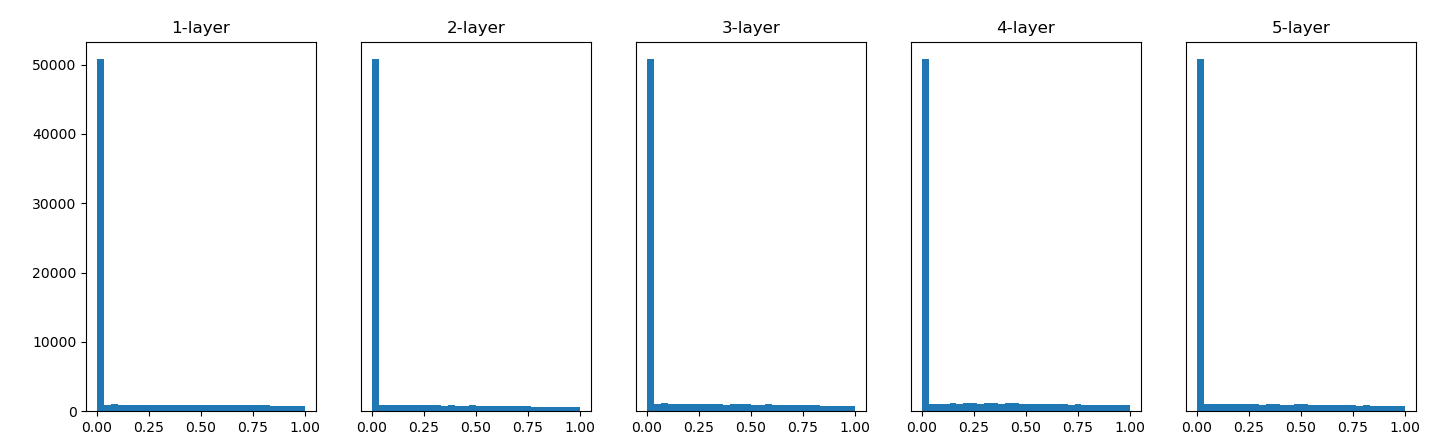
앞 계층의 노드가 n개일 때 표준편차가 루트(2/n)인 정규분포를 사용
MNIST 데이터셋으로 본 가중치 초기값 비교
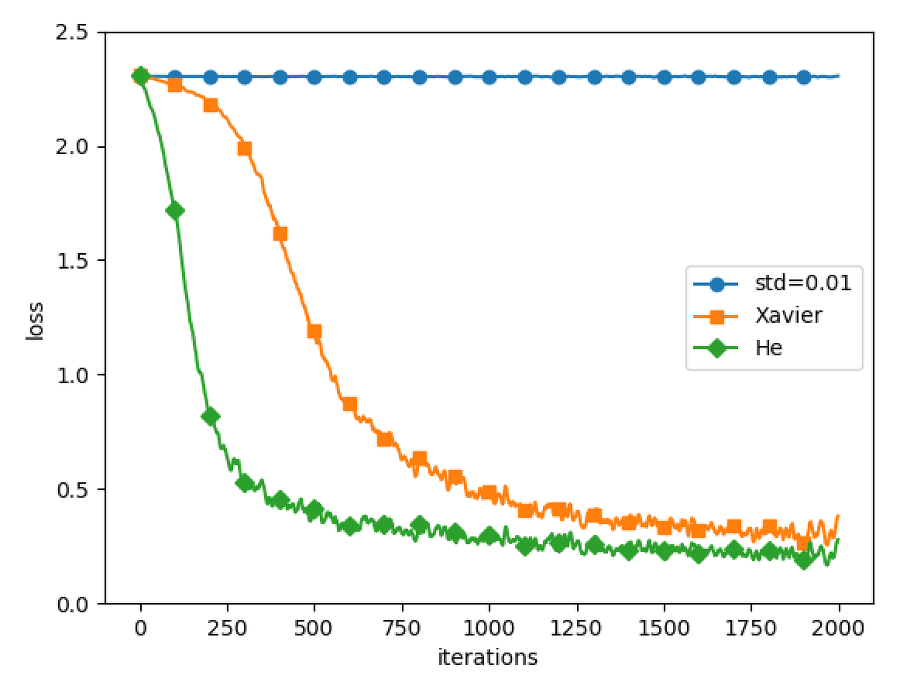
많이 돌려봤을때는 잘 몰라도 적게 돌릴때는 He 초기값이 유리하다.
가중치 초기값에 따라 학습의 속도&최대 정확도가 달라짐
중간고사 관련
글을 쓸때는 전달력이 중요하다.
다른 사람이 잘 이해할 수 있도록
서면으로 전달할때의 표현력!이 중요.
