
YuNet
Object Detection Model을 이용해서 실시간으로 얼굴을 블러 처리하는 앱을 만들어 보자.
위 사진은 YuNet을 이용해서 얼굴을 감지하는 모습이다. 이번 글에서도 마찬가지로 Yunet을 이용해서 얼굴 감지 후, 블러 처리를 할 예정이다.
OpenCV 라이브러리를 이용할 예정이다. 아래 글에서 OpenCV 라이브러리를 로드하는 방법을 참고하고 아래 글을 보면 된다.
https://velog.io/@aloe/YOLOv8-segmentation-%EC%95%88%EB%93%9C%EB%A1%9C%EC%9D%B4%EB%93%9C-2#-3-opencv-%EB%9D%BC%EC%9D%B4%EB%B8%8C%EB%9F%AC%EB%A6%AC-%EC%A0%81%EC%9A%A9
물론 OpenCV 라이브러리를 사용하지 않아도 문제는 없다. 다만, OpenCV 라이브러리에서는 YuNet의 후처리 과정을 지원해주기 때문에 편의성을 위해 OpenCV 라이브러리를 사용할 예정이다.
YuNet에 대한 자세한 아키텍쳐나, 모델에 대한 내용은 아래 공식 github를 참고하면 될 듯하다.
https://github.com/ShiqiYu/libfacedetection
✔ 1. 모델 다운
YuNet은 2021년도 모델도 존재하지만, 2023년도에 새로 만들어진 모델이 있으므로, 아래 사이트에서 신규 모델을 다운 받을 수 있다.
https://github.com/opencv/opencv_zoo/blob/main/models/face_detection_yunet/face_detection_yunet_2023mar.onnx
앞서 설명했지만, OpenCV 라이브러리에서는 YuNet의 전처리나 후처리 과정을 지원해준다. 따라서 모델의 아키텍쳐나 출력 구조는 생략하겠다.
✔ 2. 앱 생성
새로운 안드로이드 앱을 생성하고, 모델과 라벨링된 txt 파일을 assets 폴더에 넣는다. 좌측 상단에 Android → Projcet 로 변경한 뒤에 app → src → main 폴더 우클릭 후 new → Directory에 assets 폴더를 생성하면 된다.
위에서 다운받은 YuNet onnx 모델 파일을 assets 폴더에 추가하면 된다.
이후 다시 좌측 상단에 Projcet를 Android로 변경한다.
✔ 3. 카메라 권한 및 OpenCV 로드
- 앱 권한에 카메라를 추가한다.
<uses-feature
android:name="android.hardware.camera"
android:required="false" />
<uses-permission android:name="android.permission.CAMERA" />프로젝트의 manifests 폴더에 아래와 같이 추가하면 된다.
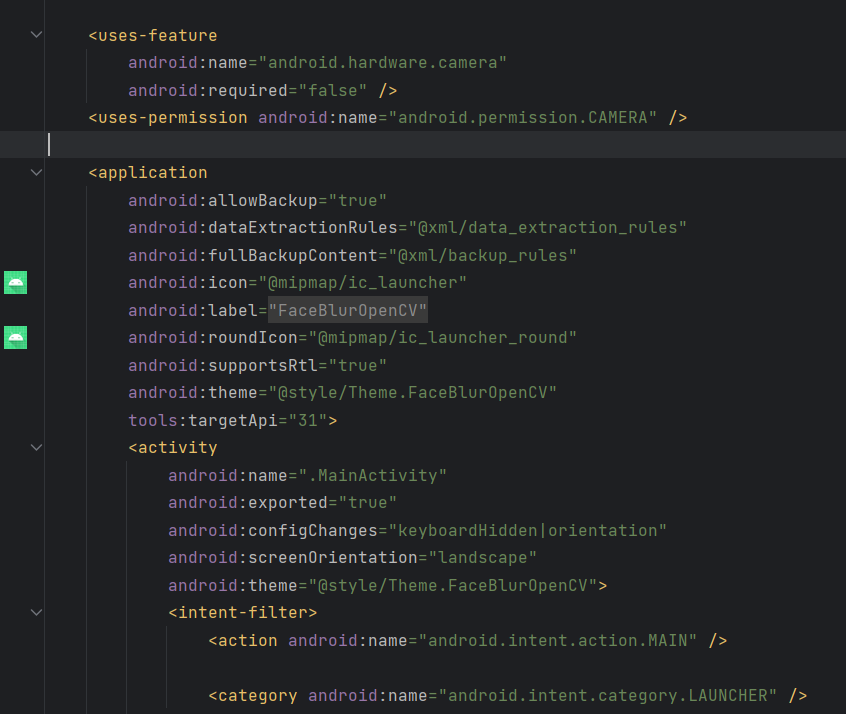
- 전체 화면을 위해서 res -> values -> themes.xml에 아래와 같이 코드를 추가한다.
<item name="android:windowFullscreen">true</item>
- 앱이 실행될 때, 카메라 권한을 요청하고 수락한 경우에만 실행되게 작성한다.
private fun setPermissions() {
val requestPermissionLauncher =
registerForActivityResult(ActivityResultContracts.RequestPermission()) {
if (!it) {
Toast.makeText(this, "권한을 허용 하지 않으면 사용할 수 없습니다.", Toast.LENGTH_SHORT).show()
finish()
}
}
listOf(Manifest.permission.CAMERA).forEach {
if (ContextCompat.checkSelfPermission(this, it) != PackageManager.PERMISSION_GRANTED) {
requestPermissionLauncher.launch(it)
}
}
OpenCVLoader.initDebug()
}setPermissions 메서드를 정의하는 부분이다. 카메라 권한을 허용하지 않은 경우는 앱이 종료되게 된다. list로 지정할 필요는 없지만, 추후에 확장성을 위해서 list 형태로 설정하였다.
마지막에 OpenCVLoader.initDebug() 메서드를 사용하는 것을 확인할 수 있는데

해당 메서드를 사용해야 OpenCV 라이브러리를 사용할 수 있기 때문이다.
이제 이 메서드를 메인 액티비티가 실행될 때 수행하면 되게 아래와 같이 추가한다.

✔ 4. 카메라 추가 및 View 설정
- 카메라 리스너를 메인 액티비티에 implements 한다.
class MainActivity : ComponentActivity(), CameraBridgeViewBase.CvCameraViewListener2 {이후 아래와 같이 오류가 생길 것이다.

아래 사진과 같이 메서드들을 오버라이딩 하면 된다.
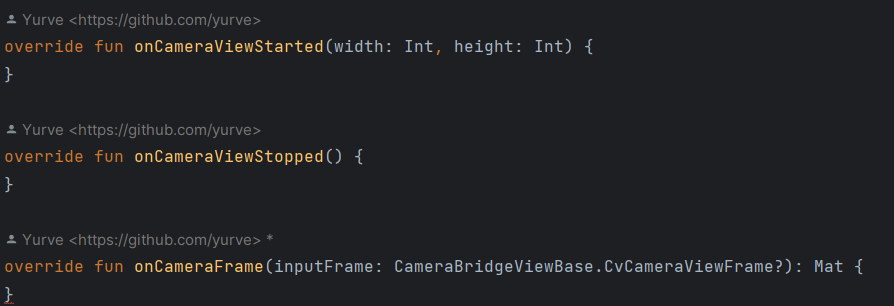
이곳 메인 액티비티에서 카메라 리스너를 등록해서 카메라로 받아온 화면에 대한 처리를 진행할 예정이다.
onCameraFrame 메서드를 통해서 화면에 대한 각종 처리를 진행할 수 있다.
onCameraFrame의 반환형에 없어서 에러가 나오는 것을 확인할 수 있다.
만약 카메라로 받아온 데이터에 대해 어떠한 처리도 없이 화면에 보이고 싶다면
retrun inputFrame!!.rgba() 위와 같이 onCameraFrame의 내부에 작성하면 된다.
- 카메라 생성
위의 1번을 통해 카메라로 받아온 화면에 대해 리스너를 등록하였다. 이제 카메라 자체를 생성해야 한다.
우선 MainActivity에 아래와 같이 추가한다.
companion object {
const val CAMERA_ID = 0
}CAMERA_ID는 0번으로 되어있는 데, 0번이 후면 카메라이고 1번이 전면 카메라이다.
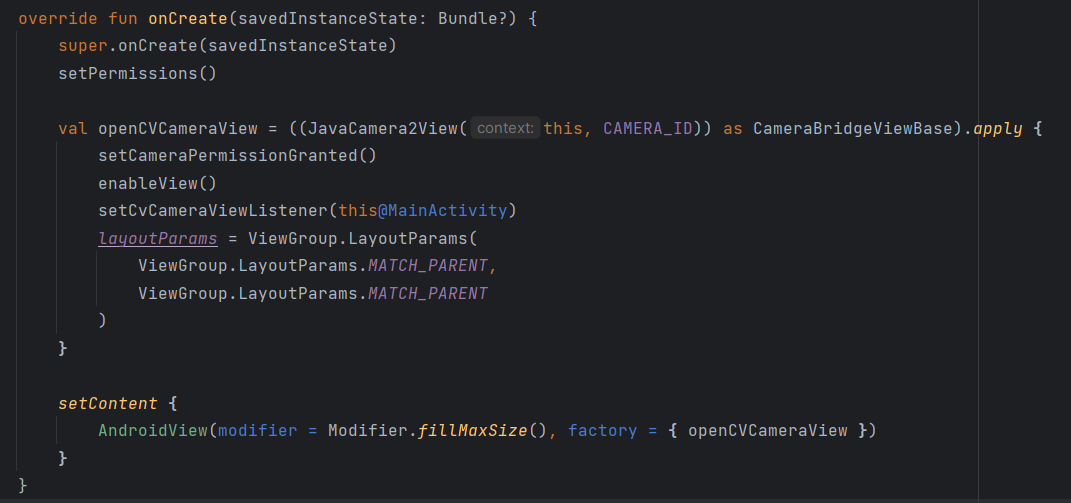
이제 onCreate 내부에서 카메라를 생성하고 Compose를 이용해서 화면을 작성한다.
val openCVCameraView = ((JavaCamera2View(this, CAMERA_ID)) as CameraBridgeViewBase).apply {
setCameraPermissionGranted()
enableView()
setCvCameraViewListener(this@MainActivity)
layoutParams = ViewGroup.LayoutParams(
ViewGroup.LayoutParams.MATCH_PARENT,
ViewGroup.LayoutParams.MATCH_PARENT
)
}
setContent {
AndroidView(modifier = Modifier.fillMaxSize(), factory = { openCVCameraView })
}JavaCamera2View 객체는 OpenCV 라이브러리에서 사용된 객체이지만, 내부를 보면 android Camera2 api를 사용하는 것을 알 수 있다.
setCvCameraViewListener를 이용해서 리스너를 등록하고, layoutParams 를 이용해서 전체 화면으로 할당한다.
Compose의 AndroidView를 이용해서 방금 생성한 카메라 View를 적용하면 된다.
정리하자면 CvCameraViewListener2를 이용해서 화면에 대한 각종 처리를 진행할 수 있으며, JavaCamera2View를 이용해서 카메라 생성 및 View 생성을 하는 것이다.
✔ 5. 추론 객체
- 추론을 담당할 Process 클래스를 프로젝트에 추가한다.
클래스 내부 변수를 아래와 같이 생성한다.
private lateinit var yunet: FaceDetectorYN
companion object {
const val MODEL = "face_detection_yunet_2023mar.onnx"
const val SIZE = 640
const val CONFIDENCE_THRESHOLD = 0.4f
const val NMS_THRESHOLD = 0.4f
}FaceDetectorYN 객체가 OpenCV 에서 제공하는 YuNet 모델의 후처리를 지원해주는 객체이다.
companion object 내부에는 model에서 사용되는 정보들을 정리한 내용이다. assets 폴더 안에 추가한 모델명, 입력 사이즈, 각종 confidence threshold를 설정한 것이다.
- 모델 로드
assets 폴더 안에 있는 모델을 불러오는 메서드이다.
fun loadModel(assets: AssetManager, fileDir: String) {
val outputFile = File("$fileDir/$MODEL")
assets.open(MODEL).use { inputStream ->
FileOutputStream(outputFile).use { outputStream ->
val buffer = ByteArray(1024)
var read: Int
while (inputStream.read(buffer).also { read = it } != -1) {
outputStream.write(buffer, 0, read)
}
}
}
yunet = FaceDetectorYN.create(
"$fileDir/$MODEL",
"",
Size(SIZE.toDouble(), SIZE.toDouble()),
CONFIDENCE_THRESHOLD,
NMS_THRESHOLD
)
}yunet 모델의 생성자로 이전에 작성했던 companion object의 값들이 사용되는 것을 확인할 수 있다.
만약 실시간으로 threshold를 변경하고 싶다면, YuNet 모델 객체를 재생성하는 것이 아니라, set 메서드를 이용해서 confidence threshold를 변경하거나 iou threshold를 변경하면 된다.
- 전처리 메서드
private fun preProcess(mat: Mat): Mat {
val input = Mat()
Imgproc.cvtColor(mat, input, Imgproc.COLOR_RGBA2RGB)
Imgproc.resize(input, input, yunet.inputSize)
input.convertTo(input, CvType.CV_32FC3)
return input
}
OpenCV에서는 각종 전처리들을 메서드를 이용해서 간단히 사용할 수 있다.
원리는 아래와 같다.
- 입력으로 들어온 화면에 대해 RGBA -> RGB 3차원으로 축소한다.
- 입력 화면을 모델의 입력 사이즈에 맞게 수정한다.
- 입력 화면의 타입을 int -> float형태로 변환한다. (모델의 요구조건)
- 추론 메서드
fun detect(input: Mat): Mat {
val inputMat = preProcess(input)
val outputMat = Mat()
yunet.detect(inputMat, outputMat)
return outputMat
}메인 액티비티에서 사용될 메서드다. 입력 화면이 들어오게 되면 이전에 정의했던 전처리 메서드를 진행하고, 모델로 추론한 뒤 해당 결과값을 반환하는 메서드이다.
- 후처리 메서드
fun postProcess(input: Mat, result: Mat?): Mat {
if (result == null || result.total() == 0.toLong()) return input
(0 until result.rows()).forEach {
val dx = input.width() / SIZE.toFloat()
val dy = input.height() / SIZE.toFloat()
val left = max(0, (result.get(it, 0)[0] * dx).toInt())
val top = max(0, (result.get(it, 1)[0] * dy).toInt())
var width = (result.get(it, 2)[0] * dx).toInt()
var height = (result.get(it, 3)[0] * dy).toInt()
if (left + width > input.width()) width = input.width() - left
if(top + height > input.height()) height = input.height() - top
val rect = Rect(left, top, width, height)
val rectColor = Scalar(0.0, 255.0, 255.0)
val conf = result.get(it, 14)[0]
val text = "%.2f".format(conf * 100).plus("%")
val point = Point(left.toDouble(), top.toDouble() - 5)
val font = Imgproc.FONT_HERSHEY_SIMPLEX
val textColor = Scalar(0.0, 0.0, 0.0)
val face = Mat(input, rect)
Imgproc.GaussianBlur(face, face, Size(99.0, 99.0), 0.0, 0.0)
Imgproc.rectangle(input, rect, rectColor, 3)
Imgproc.putText(input, text, point, font, 1.3, textColor, 3)
}
return input
}후처리를 담당하는 메서드이다. 여기서 중요한 점은 모델에 대한 후처리가 아니라, 화면에 출력을 담당할 후처리 메서드라는 점이다. 모델의 출력에 대한 후처리 과정은 FaceDetectorYN 객체가 알아서 처리해준다.
결과값은 N차원 Mat 객체로 이루어져 있다. 감지된 얼굴의 개수가 N개라면 N차원이 생성된다. 만약 감지된 얼굴이 1개라면, 1차원 Mat 객체로 이루어져 있다.
1차원 내부에는 얼굴에 대한 좌표값, 특징점들(눈의 위치, 코의 위치, 입술의 위치)이 있다. 그러나 이번 프로젝트에서는 특징점을 사용할 필요가 없어서 구현하지 않았다.
후처리 과정은 아래와 같다.
- 감지된 객체가 존재하지 않으면 원본 사진 반환
- 감치된 객체의 좌표값을 화면의 크기에 맞게 수정 & 화면의 max 값을 넘지 못하게 수정
- 바운딩 박스와 확률값 추출
- 화면 바운딩 박스 위치에 가우시안 블러효과 적용
- 화면에 바운딩 박스 그리기
- 화면에 확률값 작성
✔ 6. 비동기 추론 및 그리기
5번을 통해서 추론에 관련된 객체를 구현하였다. 이제 이를 메인 액티비티에서 사용할 예정이다.
- 메인 액티비티에 아래와 같이 객체를 추가한다.
private val process by lazy { Process() }
private var result: Mat? = null
private var isDetect = falseProcess 객체를 전역 변수로 할당해서 여러 곳에서 사용할 수 있게 하였다.
result 객체는 모델의 출력 객체이다. 이곳에 얼굴에 대한 각종 정보들이 담겨있다.
isDetect는 추론 중이라면 추론을 하지 않게 설정하는 boolean 값이다.
- onCreate 내부에 모델 로드 메서드를 추가한다.
process.loadModel(assets, filesDir.toString())
- onCameraFrame 내부에 추론 및 후처리 과정을 작성한다.
override fun onCameraFrame(inputFrame: CameraBridgeViewBase.CvCameraViewFrame?): Mat {
val view = inputFrame!!.rgba()
lifecycleScope.launch(Dispatchers.Default) {
if(isDetect) return@launch
isDetect = true
result = process.detect(view)
isDetect = false
}
return process.postProcess(view, result)
}코루틴 블럭을 이용해서 비동기로 추론을 하게 된다. 이때 추론 속도보다 화면 전환 속도가 빠르므로 추론은 반드시 1개만 하도록 isDetect 값을 이용한다.
postProcess 메서드를 이용해서 결과값을 화면에 표출하게 된다.
화면을 변경하는 내용이므로 코루틴 블럭이 아닌 곳에서 실행하게 설정하였다.
아래 사진은 얼굴 블러 처리에 대한 결과이다.

구글에 face로 검색했을 때 가장 앞에 있는 사진에 대해 앱을 적용시킨 결과이다.
잘 적용된 것을 확인해볼 수 있다.
object detection 모델로 YOLO를 선택할 수도 있지만, face와 같이 특정 객체만 찾고 싶은 경우는 이런 모델도 참고하면 좋을듯 하다. face에 대해서는 YOLO 모델만큼 잘 탐지가 가능할 뿐더러 추론 속도도 빠르기 때문에 더 나은 선택지가 될 수 있다.
전체 코드는 깃허브를 참고하면 될 듯하다.
https://github.com/Aloe-droid/FaceBlurApp
이번 프로젝트는 OpenCV 라이브러리를 이용하다 보니 후처리 과정이 굉장히 생략된 점이 있다.
만약 후처리를 직접 구현하고 싶다면 아래 깃허브를 참고하면 될 듯하다.
https://github.com/Aloe-droid/WebDetect
다만, 위의 프로젝트는 여러 detect를 제공하는 내용으로 후처리 과정만 보고 싶다면,
https://github.com/Aloe-droid/WebDetect/blob/master/WebDetect-ONNX/wwwroot/js/post_yunet.js
이곳을 참고하면 된다.
