1. 문제 상황
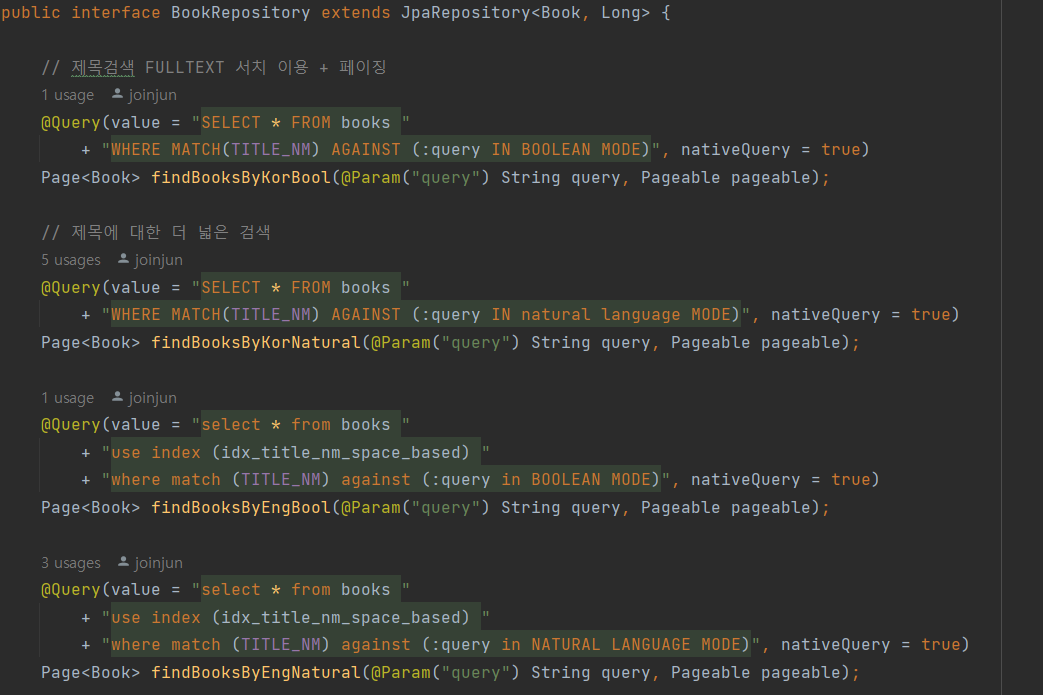
끔직하게도 복잡하고 중복된 Data JPA의 nativeQuery 코드가 많았던 기존의 Book과 Book 추천을 위한 Recommend Repository의 Data JPA에 담겨진 JPQL이다. 두 인터페이스에 정의된 nativeQuery 코드만 해도 200여 줄이 된다...
자세히 보면 중복된 코드도 많다. 그 이유는 Book에서 정의된 JPQL문에 단순히 orderBy를 붙이기 위해 중복된 코드가 필요해지는 상황이다.
아래는 문제의 코드들...
2. 왜 이런 nativeQuery가 필요 했는가?
Mysql의 Full Text index만을 사용해서 검색 엔진을 만들고자 했던 도전에서 기인한다. full text index는 한글과 영어를 언어 특성 차이에 따라 각기 다른 parser를 적용해야 했다.
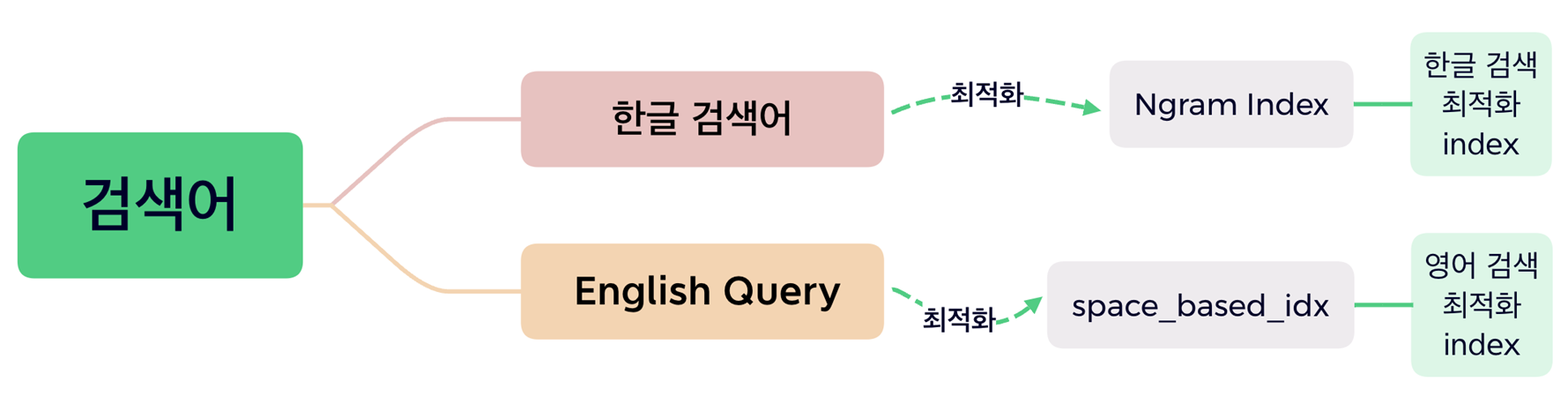

1.우리는 이런 도서 상세정보 table에서 TITLE_NM에 두가지의 인덱스를 적용하고, optimizer가 index를 자동으로 설정 해주지 않아 use index를 사용하게 됐다. 그렇다 보니 한글+영어 제목에 대해선 subquery를 사용해야만 했고, subquery를 사용 했을 때 countQuery를 명시 해줘야 했기 때문에 JPQL은 한없이 길어졌다.
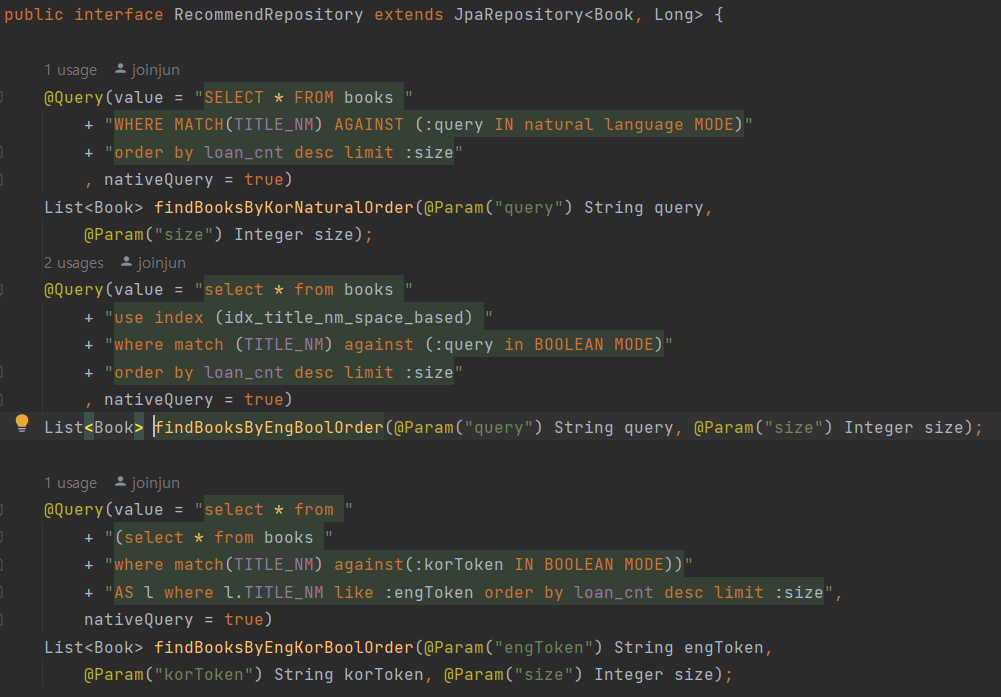
2.또한 우리는 도서 추천 관련한 서비스도 있는데, 이때도 마찬가지의 방법으로 도서를 검색 해야하는데 만들어진 도서 검색 쿼리를 재사용하지 못하고, orderBy만 추가된 중복된 코드들이 많았다.
- 한글+영어 제목에선 full text index를 서브 쿼리로 찾고, 다시 그 결과에서 use index를 사용해서 다른 full text search를 시행하려고 했지만 이것은 지원되지 않는 쿼리이기 때문에, 우리는
한글+영어 제목을 검색시 먼저 서브쿼리로 한글 키워드에 해당되는 제목만 찾고 그 결과안에서 like절로 영어 키워드가 포함돼 있는지 작업을 거쳤었다. 그러다 보니 like절로 인해 인덱스를 이용하지 못하고 한글로 검색된 결과가 많을수록 심각한 성능 저하가 나타나게 됐다.
재사용하지 못하고 중복되던 Repository 코드들
3. 그래서 어떻게 해결 했는가?
처음에는 QueryDsl를 이용해서 단순히 nativeQuery를 리팩토링을 하려고 했다.리팩토링을 하는 과정에서 현재 검색 엔진 알고리즘의 타당성에 대해서 고민하게 됐고, 그것이 틀렸다고 판단 했다.
기존의 검색 엔진은 사용자 검색 쿼리를 자연어 분석 라이브러리를 활용하여 명사 키워드로 변환한 뒤, 검색하는 과정을 거친다. 그래서 아이디어가 떠오른 게 [제목을 명사 키워드로 추출한 뒤 비정규화를 거치자] 이다. 이렇게 하면 한글도 공백 기반 파서로 full text index를 설정하면 되기 때문에 문제가 깔끔 해진다고 판단 했다.
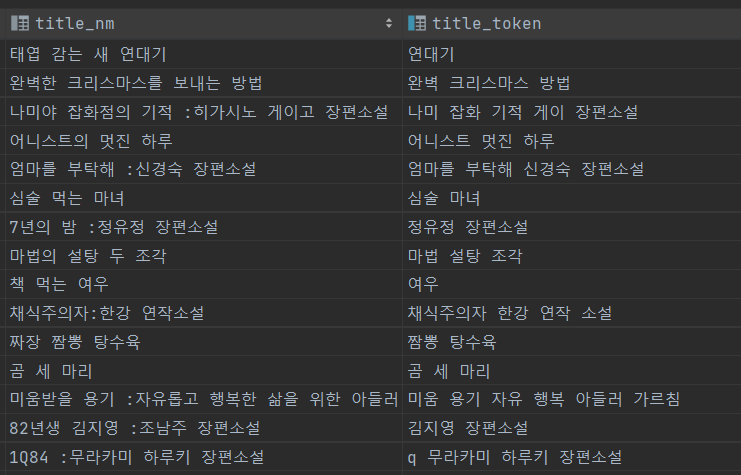
- 비정규화 된 새로운 Book table의 모습이다. 검색 쿼리를 날릴때도 title_token에 대해서 검색해서 결과값을 얻는다.
비정규화 과정은 기존에 있던 Book Table을 JPA를 통해 Java단으로 읽어와 명사 키워드 추출 작업을 하고, 빠른 삽입을 위해 Csv 파일로 변환한 뒤, 완성된 Csv 파일을 DB에 다시 임포트 하는 과정을 거쳤다. 이 과정을 다른 글에서 소개 하겠다.
4. 그래서 결론은?
검색 엔진의 알고리즘을 바꾸니 이제는 단일 Full text index이기 때문에 Use Index를 고려할 필요도 없어졌다. 기존에 사용자 검색 쿼리를 각각의 Full Text index와 매핑하기 위해서 분석하는 과정도 대폭 삭제 됐다.
또한 이 글에서 문제로 제기한 JPQL문도 검색 품질을 위해 키워드 갯수만 판단하여 그 갯수에 따라 boolean mode 나 natural mode만 선택하면 되기에 간단 명료 해졌다.
5. 복잡 했던 nativeQuery를 대체하는 새로운 Repository


이 글은 제게 많은 도움이 되었습니다.