
MapBook 서비스의 검색은 도서의 대출 횟수를 기반으로 우선 상위 노출을 하는 것이 특징이다. 이 대출 횟수 데이터를 공공 데이터 플랫폼으로부터 직접적으로 획득 할 순 없다. 다른 데이터에서 합산해서 다시 Book 데이터 칼럼에 넣어줘야 한다.
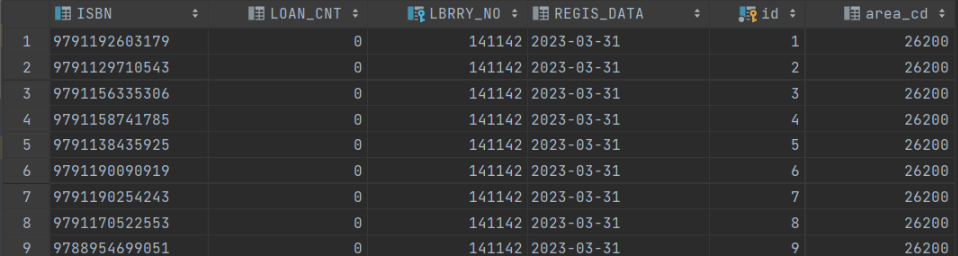
아래는 책의 상세 정보를 담는 Book 테이블의 일부 칼럼의 모습이다. 공공 데이터로 제공 받은 데이터에는 저 loan_cnt가 없다. 저 부분을 따로 다른 데이터에서 합산해서 넣어줘야 한다.
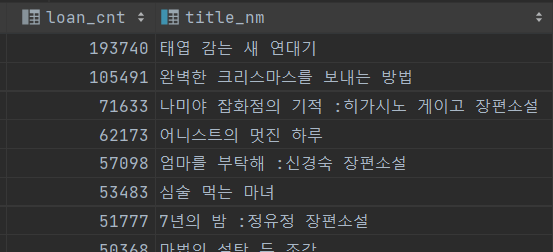
무슨 상황인가?
합산할 데이터를 수집하기 위해서 '도서관 장서 도서 목록' Csv file을 사이트에서 일일이 다운로드 받아야 했다.

현재 대출 횟수는 서울과 성남 도서관에 한정해서 합산한 데이터이다. 이정도만 해도 2500만건이고, 서울 지역이기에 대표성을 띌 수 있다고 판단하여 이정도의 데이터로 만족하고자 했다.
무슨 문제가 있는가?
- 계속해서 찜찜한 한가지가 있었다. '데이터의 최신화'의 문제이다.
1) 도서 상세 정보 데이터는 22년 이후로 공공 데이터를 제공하지 않는다.
-> 그래서 자체적으로 도서 데이터 수집 프로세스를 가지고 있긴 하다. 하지만 전제 조건이 도서관에 새로 들어온 책에 대한 데이터가 있어야 수집이 가능한 구조이다.
2) 따라서 도서관 별 소장 도서 데이터가 최신화가 되야 도서 상세 정보도 제대로 최신화가 될 수 있다. 또한 검색의 특징 중 하나인 대출 횟수도 신뢰성을 가질 수 있다.
그래서 어떻게 하고 싶은가?
file에 대한 다운로드도 자동화 해서 수집 할 순 없을까?
라는 생각이 들었고, 그것을 시도 했고 성공한 내용이다.
어떤 과정을 거쳤나?
1. 다운로드 사이트 html 구조 파악
- data-url의 attribute의 url를 파악하면 다운로드가 가능 할 것이라 판단 했다.
- data-url을 crawling하는 LoanCntUrlCrawler
public class LoanCntUrlCrawler {
private static final String TARGET_URL = "https://data4library.kr/openDataV?libcode=";
private static final String COMMON_DOWNLOAD_URL = "https://www.data4library.kr";
public static Optional<String> getDownloadUrl(int libCode, String date) throws IOException {
Connection conn = Jsoup.connect(TARGET_URL + libCode);
AtomicReference<String> result = new AtomicReference<>();
conn.get().select("table tr").forEach(
element -> {
Element link_td = element.selectFirst("td.link_td");
if (isContainsDateLine(link_td, date) && isExistTextTypeInElement(element)) {
result.set(COMMON_DOWNLOAD_URL + getDetailUrl(element));
}
});
return Optional.ofNullable(result.get());
}
private static String getDetailUrl(@NonNull Element element) {
return Objects.requireNonNull(
element.selectFirst("a.download_link.text_type"))
.attr("dataPipe-url");
}
private static boolean isContainsDateLine(Element link_td, String date) {
return link_td != null && link_td.text().contains(date);
}
private static boolean isExistTextTypeInElement(Element element) {
return element.selectFirst("a.download_link.text_type") != null;
}
}크롤링 할 url을 분석 해보니, 끝에 libcode만 바뀌면서 도서관 별 다운로드 페이지로 이동하는 식이였다.

다운로드 받는 파일을 직집 지정 해줘야 했고, 그 이름은 "강남구립논현도서관 (2023년 6월).csv"와 같은 형식으로 정했기 때문에 libcode와 매칭 되는 도서관 이름이 필요 했다. 그래서 기존에 존재하는 libraryInfoService를 활용해서 libcode 와 name을 매칭 했다.
- 크롤러에게 제공 받은 다운로드 url에 SSL을 모두 신뢰하는 조건에서 파일을 다운로드 하는 LoanCntDownloader
@RequiredArgsConstructor
@Service
public class LoanCntDownloader {
private final LibraryFindService libraryFindService;
private static final String DEFAULT_EXTENSION = "csv";
private static final String DEFAULT_DIRECTORY = "download/";
public void collectLoanCnt(String date) {
// csv file을 서버로부터 다운 받기 위해 SSL을 모두 신뢰 한다.
setupTrustAllSSLContext();
libraryFindService.getAllLibraries().forEach(
library -> {
try {
Optional<String> url =
LoanCntUrlCrawler.getDownloadUrl(library.getLibCd(), date);
if (url.isPresent()) {
downloadFile(url.get(), configureFileName(library.getLibNm(), date));
}
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
);
}
private String configureFileName(String libNm, String date) {
return DEFAULT_DIRECTORY + "/"
+ String.join(" ", libNm, date)
+ String.join(".", DEFAULT_EXTENSION);
}
public void downloadFile(String siteUrl, String fileName) throws IOException {
InputStream in = new BufferedInputStream(new URL(siteUrl).openStream());
OutputStream out = new FileOutputStream(fileName);
byte[] data = new byte[1024];
int count;
while ((count = in.read(data, 0, 1024)) != -1) {
out.write(data, 0, count);
}
out.close();
in.close();
}
private void setupTrustAllSSLContext() {
try {
HttpsURLConnection.setDefaultHostnameVerifier((hostname, session) -> true);
SSLContext context = SSLContext.getInstance("TLS");
context.init(null, new X509TrustManager[]{generateAllTrustManager()}, new SecureRandom());
HttpsURLConnection.setDefaultSSLSocketFactory(context.getSocketFactory());
} catch (Exception e) {
e.printStackTrace();
}
}
//모든 SSL 연결을 신뢰 한다.
private X509TrustManager generateAllTrustManager() {
return new X509TrustManager() {
public void checkClientTrusted(X509Certificate[] chain, String authType) {
}
public void checkServerTrusted(X509Certificate[] chain, String authType) {
}
public X509Certificate[] getAcceptedIssuers() {
return new X509Certificate[0];
}
};
}
}

- 이제 수집은 됐으니, 데이터를 정제하고 정규화 하는 과정을 거치고 하나의 파일로 병합하는 과정이 남았다. (데이터가 null이나 . 과 같이 잘못된 데이터가 꽤 있다). 나머지 과정을 LibraryDataCsvMerger가 맡아서 한다.
public class LibraryDataCsvMerger {
private final LibraryFindService libraryFindService;
private static final int ISBN_MIN_SIZE = 10;
private static final String ISBN_REGEX = "^\\d+$";
private static final String HEADER_NAME = "ISBN,LOAN_CNT,LBRRY_CD,REGIS_DATA,AREA_CD";
// DB의 library 정보와 Csv file의 데이터 중 필요한 부분을 서로 합친다.
public void mergeLibraryData(String inputFolder, String outputFileName) {
// libarary 정보를 DB에서 모두 가져온다.
List<LibraryInfoDto> libraries = libraryFindService.getAllLibraries();
try (BufferedWriter writer = Files.newBufferedWriter(
Paths.get(outputFileName), StandardCharsets.UTF_8)) {
//가져온 library 정보와 csv file의 내용을 정규화 과정을 거치며 합친다.
processFilesMerging(getCsvFiles(inputFolder), writer, libraries);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
private void processFilesMerging(File[] files, BufferedWriter writer,
List<LibraryInfoDto> libraries) {
AtomicBoolean headerSaved = new AtomicBoolean(false);
Arrays.stream(files).forEach(file -> {
Optional<LibraryInfoDto> libraryOpt = findLibraryInfo(file, libraries);
// 필요한 칼럼에 해당하는 데이터만 저장 한다.
normalizeAndWriteIfPresent(file, headerSaved, writer, libraryOpt);
});
}
private File[] getCsvFiles(String folder) {
return new File(folder).listFiles((dir, name) -> name.endsWith(".csv"));
}
// input 된 file의 이름과 일치하는 library 정보를 찾는다.
private Optional<LibraryInfoDto> findLibraryInfo(File file, List<LibraryInfoDto> libraries) {
return libraries.stream()
.filter(library -> isContainsLibNmInFile(file, library))
.findAny();
}
private void normalizeAndWriteIfPresent(File file, AtomicBoolean headerSaved,
BufferedWriter writer, Optional<LibraryInfoDto> libraryOpt) {
libraryOpt.ifPresent(libraryDto -> {
try {
normalizeAndWrite(file, headerSaved.get(), writer, libraryDto);
headerSaved.set(true);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
});
}
private void normalizeAndWrite(File file, boolean headerSaved, BufferedWriter writer,
LibraryInfoDto library) throws IOException {
try (Reader reader = Files.newBufferedReader(
file.toPath(), Charset.forName("EUC-KR"))) {
CSVParser csvParser = new CSVParser(reader, CSVFormat.DEFAULT);
if (!headerSaved) {
writer.write(HEADER_NAME);
writer.newLine();
}
for (CSVRecord record : csvParser) {
String result = normalizeData(record, library);
if (!result.isBlank()) {
writer.write(result);
writer.newLine();
}
}
}
}
private boolean isContainsLibNmInFile(File file, LibraryInfoDto library) {
return library.getLibNm().contains(extractLibraryName(file));
}
// File Name : 구성도서관 장서 대출목록 (2023년 04월)에서 '구성도서관'만 추출
private String extractLibraryName(File file) {
return file.getName().split(" ", 3)[0];
}
private String normalizeData(CSVRecord record, LibraryInfoDto library) {
LoanCntVo vo = new LoanCntVo(record);
String isbn = vo.getIsbn();
String loanCt = vo.getLoanCnt();
String regisDate = vo.getRegisterDate();
String libNo = String.valueOf(library.getLibNo());
String areaCd = String.valueOf(library.getAreaCd());
return isValidIsbn(isbn) ? buildCsvLine(isbn, loanCt, regisDate, libNo, areaCd) : "";
}
private boolean isValidIsbn(String isbn) {
Pattern pattern = Pattern.compile(ISBN_REGEX);
Matcher matcher = pattern.matcher(isbn);
return matcher.matches() && isbn.length() > ISBN_MIN_SIZE;
}
private String buildCsvLine(String... args) {
return String.join(",", args);
}
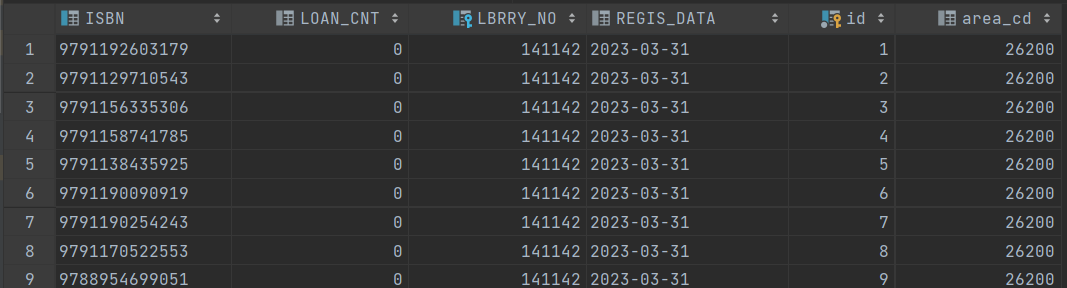
}- 아래는 최종 결과물이 import 되고 난 이후의 모습이다. 이 데이터는 대출 횟수의 합산이 있고, 지도 기반 서비스에서 API 연결 전 소장하고 있는지 checking하는 전처리를 위해 지역을 커스텀하게 코드 번호로 묶은 area_cd도 있다. area_cd는 LibraryDataCsvMerger가 이름과 매칭해서 만들어서 넣어준다.

수집 결과 : 1억 2천 4백만 건

좋은 영향력과 교류를 위하여