1. 왜 이런 짓을 했는가?
책을 평소에 좋아해서 도서관 웹서비스를 이용할 때 불편함을 많이 느끼고, 지도 기반으로 대출 가능한 도서관을 보여줄 수 있는 서비스를 찾지 못해서 필요성을 느끼고 있었다. 그러던 중 항해 99 마지막 실전 프로젝트에서 기획 단계에서 내 도메인을 얘기 했고, 팀원들과 함께 도서 관련 프로젝트를 주제로 프로젝트를 시작 했다.
우리는 챌린지 팀으로써 서비스에 초점을 두기 보단 백엔드 기술에 더욱 집중하는 프로젝트 팀이였다. 그래서 우리는 초기 검색 엔진을 Elastic Search를 도입 하는데 있어 고민이 많았다. 시중 검색 엔진에서 가장 활용도가 높은 Elastic Search를 사용해서 성능을 개선한다고 해서 그것이 배우고 있는 우리에게 당장 필요한 것은 아니라고 생각 했다. 물론 현업에선 Elastic Search를 잘 다루고 바로 서비스에 투입 되는 게 중요 하겠지만, 이때 당시에는 그동안 배워왔던 Java,Spring,Mysql을 원 없이 코드를 짜보고, 그런 과정에서 풍부한 비즈니스 로직으로 리팩토링도 많이 경험하고 싶었다.
2. 어떤 과정을 거쳤는가?
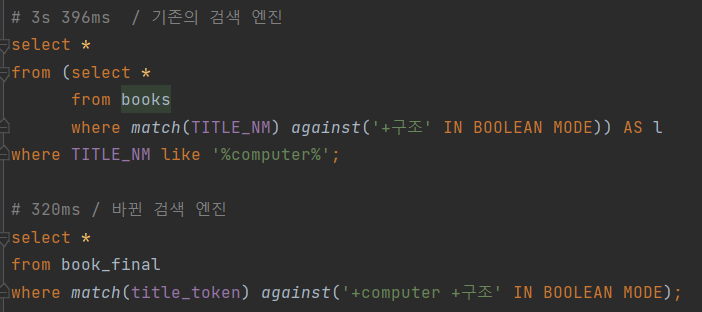
- Like절과 와일드 카드를 사용한 검색
-
Like절은 인덱스를 타지 못하기 때문에 검색 시 성능 저하
| 검색어 | 속도 |
| 스프링 부트 | 5210ms |
| 고양이 | 1877ms |
| spring boot | 4657ms | -
또한 검색 품질 저하 문제 '%자바의 정석%'을 통해서만 like절로 검색이 되고, '%자바 정석%;으로는 검색이 되지 않음.
-> 사용자의 입력 패턴이 각기 다를 수 있음을 인지. 정확한 검색어를 요구하기 보다는 서비스가 유연하게 검색 할 수 있는 기능을 보여야 함.
- Komoran Library + LIKE를 이용한 검색 (10s 이상 소요, 검색 정확도는 개선되었음)
-
따라서 사용자의 검색 쿼리를 동일하게 명사 단위로 추출하고, 그것을 위주로 검색하면 되지 않을까?
-
자연어 분석을 위해 Komoran 라이브러리를 사용하여 명사 단위로 추출.
-> 사용하기에 가장 간편 했고, 테스트 결과 만족스러운 결과에 의해
-
개선 : 검색 결과의 정확성, 유연함이 조금 더 나아졌다. (자바, 정석이 들어가면 자바의 정석 찾기가 가능)
-
한계 : 검색 속도가 10초 이상 걸린다.
- Full Text index를 이용한 검색
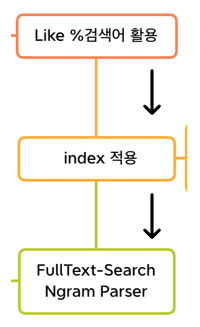
Full Text Index를 활용 하며, 영어와 한글에 대해 각기 다른 parser를 적용한 Index를 Title_nm에 이중으로 걸어서 검색에 사용 했었다.
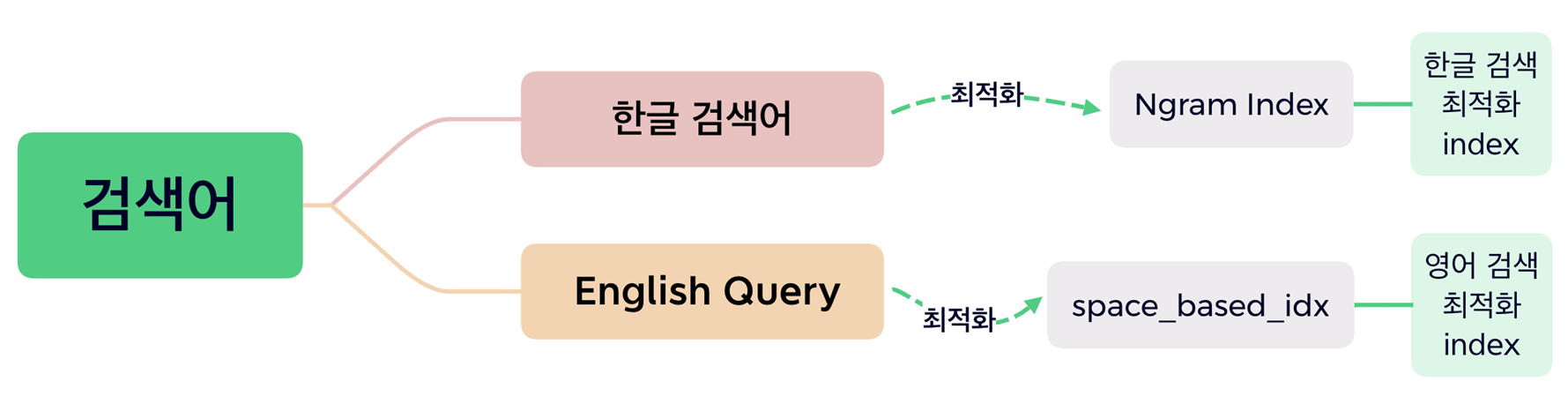
위의 그림과 같이 한글에 대해선 token 사이즈 2로 하는 ngram parser, 영어에 대해선 공백 기반의 파서로 full text index를 적용 했다.
적용 후 가장 큰 문제가 title_nm에 대해서 두개의 인덱스를 걸었을 때, 옵티마이저가 언어에 따라 적당한 인덱스를 선택하지 못했다. 그래서 초기에는 USE INDEX를 사용하는 방식으로 한글 제목에 대해선 ngram index를, 영어 제목에 대해선 space_based_idx를 USE INDEX를 통해 지정해서 검색 쿼리를 날렸었다.
이 검색 알고리즘의 문제점
-
한글+영어 검색시 한글만 가지고 먼저 full text search를 한뒤, 그 결과에서 like절로 영어를 검색하기 때문에 영어에 대해서 인덱스를 타지 못해 한글 결과가 많은 경우 5s라는 성능 저하
-
사용자 입력 쿼리에 따라서 여러 가지 경우의 수를 따져야 했기 때문에 증가되는 코드의 복잡성
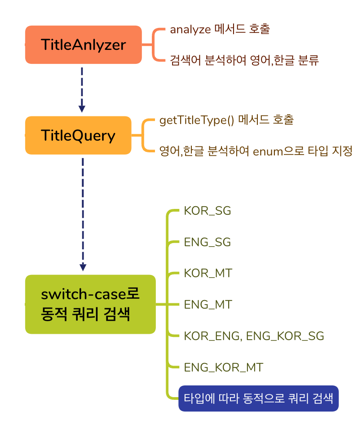
위에 그림은 사용자의 검색 쿼리를 받았을 때, DB에 연결하기 전 단계를 의미한다.
1) 한글과 영어에 맞는 각각의 index를 직접 선택하는 use index를 사용하기 때문에 TitleAnalyzer가 사용자의 검색 쿼리를 한글, 영어로 각각 분리 해야했고,
2) 한글 제목의 경우 검색 품질을 위해 케이스를 분류하여 boolean mode와 natural mode를 각기 선택 했어야 했다. 예를 들면 '대한민국'이라는 검색어는 명사 키워드 1개이기 때문에 포괄적인 검색 결과를 위해 natural mode의 쿼리를 선택 했다.
-> 이 부분에 대해서도 queryDsl을 쓰지 않고 JPQL에 의존하여 SQL 코드의 복잡도와 중복이 심한 문제를 가지고 있었다.
3) 더욱 문제는 Spring Data JPA에 정의한 메소드를 각 상황에 맞게 선택하기 위해 Switch문을 활용 했다는 문제다.
-> 처음에는 전략 패턴으로 리팩토링 했고, 현재는 queryDsl을 사용하여 리팩토링 했기 때문에 해당 클래스는 제거 됐다.
다시 정리하면 우리가 프로젝트 발표 시점의 검색 엔진은 이랬다.
- 책 제목 칼럼(Title_nm)에 이중 Full text index를 사용 했고, use index를 통해 언어에 맞는 인덱스를 Java단에서 선택 해야 했다.
- Java단의 선택을 위해 TitleAnalyer를 구현 했지만, 7가지의 케이스로 분류되는 과정이 필요하여 코드의 복잡도가 높았다.
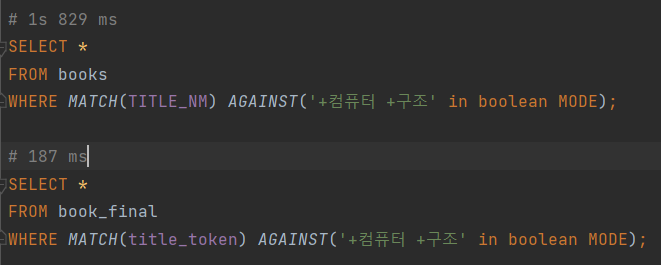
- 검색 성능은 한글 단일 제목이나 영어 단일 제목은 속도가 0.3s 이내로 준수 했지만, 한글+영어 제목의 경우 많은 경우가 3s가 넘어가는 성능 저하를 보였다.
그래서 결론은?
- 부트 캠프를 수료하고, 서비스를 내리지 않은 우리 검색 서비스를 직접 이용하면서 검색 엔진의 불편함을 많이 느꼈다. 그럼에도 그 이상으로 어떻게 개선 해야할지 뾰족한 수는 떠오르지 않았다. 그래서 개인적으로 루씬과 엘라스틱 서치를 공부하며 시중 검색 엔진을 도입하는 프로젝트를 하던 와중
아이디어가 떠올랐다.!
검색어를 명사 단위로 추출해서 검색 쿼리를 날리니깐, 미리 도서 제목을 다른 칼럼에 넣어놓고, 그 칼럼을 검색하면 되지 않을까?? 그리고 이렇게 하면 한글이여도 공백 기반으로 검색하면 되겠는데??
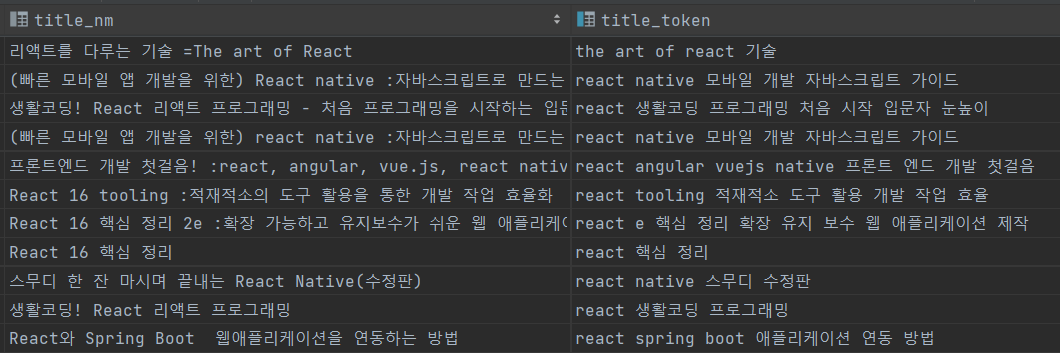
일단 결과를 보면 이렇다. title_token 칼럼이 새로 생겼으며, title_nm을 명사 키워드로 추출한 결과들이 담겨 있다. 그리고 검색어가 들어올 때도 title_token에 대해 공백 기반으로 검색 한다.
1. 어떤 과정이 필요 했나?
1) Java단으로 읽어오고, 명사 키워드로 추출 후 데이터 삽입 속도를 위해 sql insert 대신 csv file로 만든뒤, 그 파일을 다시 import 했다.
public void exportToCvs() {
// 360만건 도서 데이터이기 때문에 한번에 모든 데이터를 가져오면
out of memory 문제가 일어나 paging을 통해 나눠서 가져온다.
int pageSize = 500000;
int pageNumber = 0;
Pageable pageable = PageRequest.of(pageNumber, pageSize);
Page<Book> page;
do {
// 대출 횟수(loan_cnt) 기준으로 내림 차순으로 데이터를 입력하고,
실제 작업을 수행하기 위해 DB에서 Java단으로 데이터를 가져온다
page = bookRepository.findAllAndSort(pageable);
List<BookVo2> books = new ArrayList<>();
for (Book book : page.getContent()) {
// 도서 제목을 한글과 영어 단어로 분리하고, 한글은 명사 단위로 추출,
영어는 모두 소문자로 변환 한다.
TitleQuery query = titleAnalyzer.analyze(book.getTitle());
StringJoiner joiner = new StringJoiner(" ");
Arrays.stream(query.getEngKorTokens().split(" "))
.distinct().forEach(joiner::add);
books.add(new BookVo2(book, joiner.toString()));
}
//마지막으로 객체를 변환하여 Csv file로 만들기 위해
미리 정의한 메소드를 호출 한다
csvWriter.writeAnalyzedBooksToCsv(books, "bookFinal2.csv");
pageable = pageable.next(); // 다음 페이지를 가져오기 위한 설정
} while (page.hasNext()); // 다음 페이지가 존재하는지 확인
}public void writeAnalyzedBooksToCsv(List<BookVo2> books, String outputPath) {
try {
Path path = Paths.get(outputPath);
Writer writer;
// file이 이미 존재하면 이어쓰기를 실시 한다.
if (Files.exists(path)) {
writer = Files.newBufferedWriter(path, StandardOpenOption.APPEND);
} else {
//file이 없으면 새로 파일을 만들고 시작 한다.
writer = Files.newBufferedWriter(path);
}
StatefulBeanToCsv<BookVo2> beanToCsv = new StatefulBeanToCsvBuilder<BookVo2>(writer)
.withQuotechar('"')
.build();
beanToCsv.write(books);
writer.close();
} catch (Exception e) {
e.printStackTrace();
}
}2) 사용자 검색 요청이 들어오면 검색어를 한글, 영어로만 분류하고 저장한 방식과 마찬가지로 한글은 명사 단위로 추출, 영어는 소문자로 변환 한다.
그리고 boolean과 natural mode를 적절히 사용하기 위해 전처리가 끝난 결과 검색 키워드의 개수를 파악해 관련 된 enum 타입을 설정 한다.
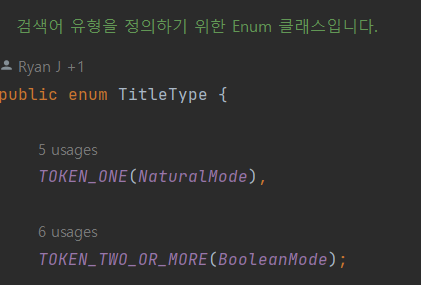
3) 마지막으로 queryDsl을 이용해 정의된 Repository단에서 적합한 쿼리를 선택해 DB에서 검색 한다.
아래는 보기 쉽게 쿼리문을 보여준다.